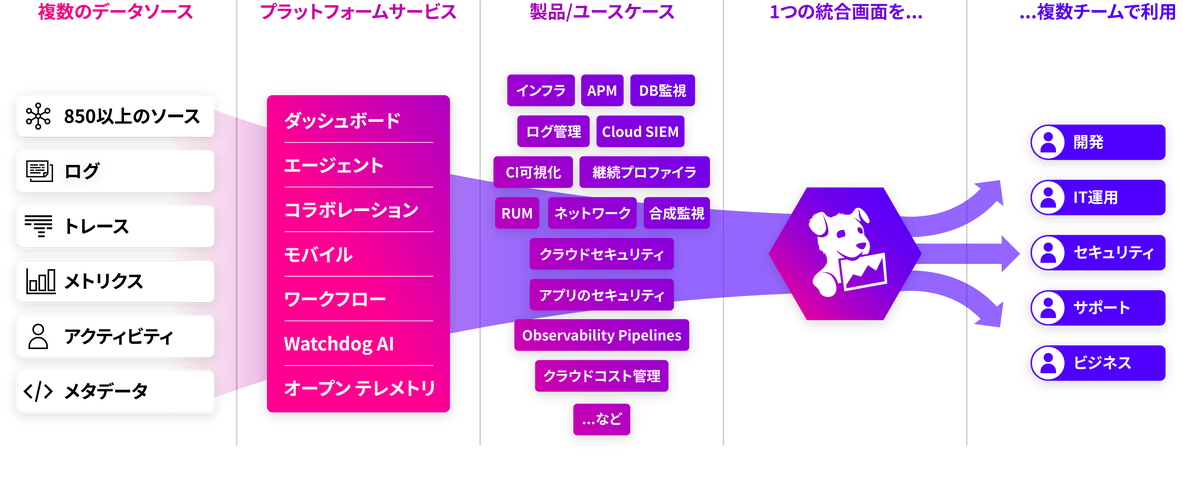

「クラウドでの開発と運用を進めるなか、Datadogを導入した目的 は統合監視ツールで様々な事象を関連付けて分析することです。 可観測性が上がり、問題の切り分けから対応までが迅速化するだ けでなく、開発者はAPMでただちに性能試験もできて、ボトルネ ックをすぐ発見できる。我々はビジネスロジックに集中し、アジ リティを高めたい。そうした要件があるなかDatadogはSaaSで提 供されているので運用負荷が低く、マルチクラウドにも対応し ているところがよかった。」
株式会社NTTドコモ
サービスデザイン部 第三クラウド推進
担当部⻑ 三井 力 氏
課題
かつて現場では、開発と運用間のコミュニケーションに課題があった。トラブルの切り分けに時間が かかっていた。運用で問題が起きたらすぐに解 決したかった。
Datadog による効果
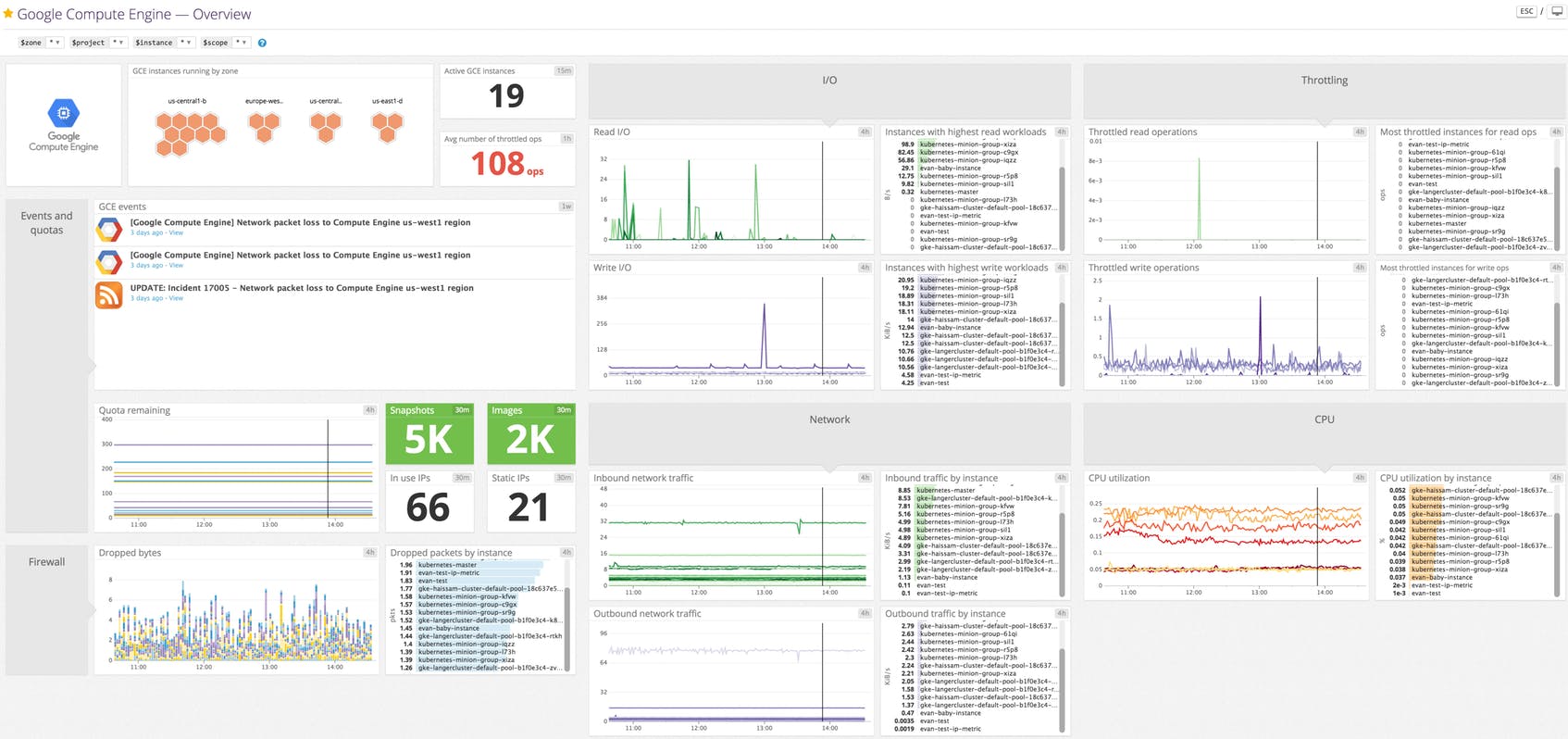
Datadogは様々な事象を関連付けて分析ができて、可観測性が高まり、対処までの時間を短縮できる。ダッシュボードの表現力、使い勝手、人気ランキングが表示されるなどの機能がメンバーを魅了し、有益なダッシュボードが次々と生まれた。DatadogがSaaS型で運用負荷が低く、マルチクラウド対応しているところもよかった。