

2018 年以降、Watchdog は、アプリケーションのパフォーマンスの問題を通知する自動異常検出を提供しています。今年の初めに、Watchdog for Infra を導入し、Watchdog を拡張してインフラストラクチャーも監視できるようにしました。Watchdog の最新の機能強化を発表できることを嬉しく思います。これにより、各アプリケーションの問題の全範囲について、より多くの可視性とより優れたコンテキストが提供されます。新しい Watchdog は、さまざまなサービスにまたがる関連する APM 異常を自動的に単一のストーリーにグループ化し、根本原因分析のための実用的な情報を提供します。また、Watchdog はアラートにコンテキストを追加し、Kubernetes クラスター内で発生する異常を自動的に表示するようになりました。Watchdog を利用すれば、セットアップなしで、動的環境をさらに深く可視化することができるようになりました。

サービス全体の APM 異常のトラブルシューティング
1 つのサービスに現れる異常は、ダウンストリームのサービスに悪影響を与える可能性があります。たとえば、あるサービスのデータベースクエリが制限された場合、そのダウンストリームサービスのレイテンシーは上昇します。これらのダウンストリームサービスの一部では、タイムアウトが原因でエラー率が最終的に増加する可能性があります。これは 2 つの切り離された問題としてではなく、単一の根本原因から派生した 1 つの問題として捉えて解決策を練る必要があります。
Watchdog は複数のサービスに影響する問題が検知された場合に、関連する APM の異常検知を単一のストーリーに自動でグループ化してこのようなトラブルシューティングをサポートします。このストーリーには、そもそもの問題が発生したサービスと、そこから影響を受けたダウンストリームの依存関係を示す依存関係マップが含まれています。マップを活用することで問題のインパクトを迅速に把握し、根本原因を解明するためのインサイトを得ることができます。
以下のスクリーンショットは、問題の概要から始まり、異常検知を捉えたグラフを示す Watchdog のストーリーです。この下の依存関係マップに、問題の完全なスコープが描写されます。問題は ad-server-http-client サービスに起因し、そのダウンストリームサービスである web-store と web-store-mongo に影響しています。依存関係マップの下には影響を受けたサービスの一覧表とヒット率、レイテンシー、エラー率のメトリクスが表示されます。この場合、表内のデータはダウンストリームサービスのレイテンシーが上昇したことを示しています。

Watchdog は、関連する異常を 1 つのストーリーに集約することで、ノイズを減らし、複数の別々のストーリーを 1 つのリッチなストーリーに置き換え、トラブルシューティングプロセスを高速化します。
ストーリーを関連するダッシュボードと関連付ける
Watchdog APM ストーリーには、相関するメトリクスとダッシュボードが含まれることで、問題のコンテキストをすばやく確認できるようになりました。Watchdog が APM ストーリーを作成するとき、相関する異常を示すダッシュボード内のメトリクスとグラフを見つけます。この相関ダッシュボードは、ストーリーで説明されている問題をより深く調査するための有用なリソースとして機能します。
以下のスクリーンショットは、1 つの相関ダッシュボードを含む Watchdog ストーリーを示しています。ダッシュボードの 2 つのグラフは、ストーリーの主要な異常に関連する異常、つまり ApplicationController#health エンドポイントでのレイテンシーの増加を強調しています。
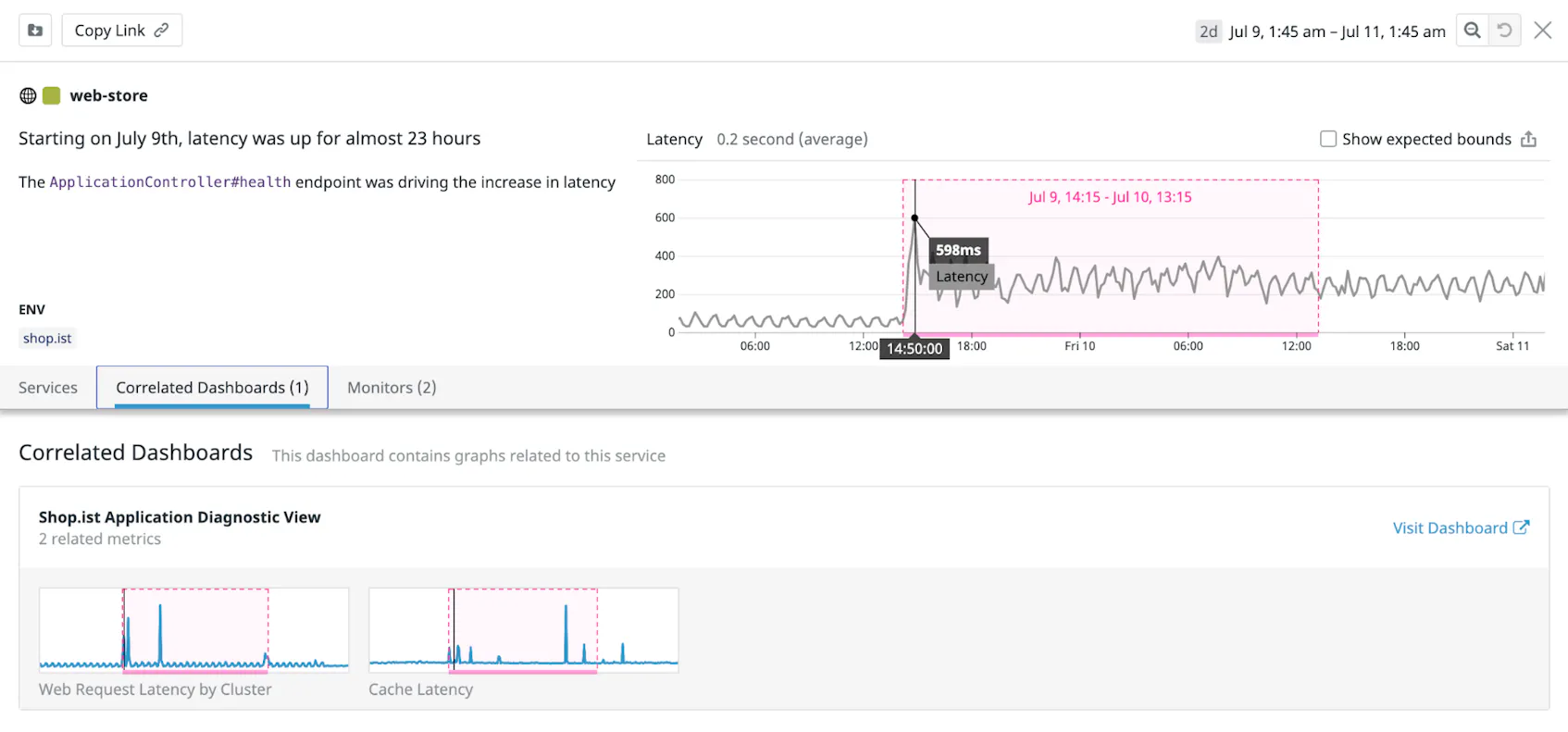
この例では、相関ダッシュボードの Web Request Latency by Cluster と Cache Latency のグラフは、ストーリーで強調表示されている異常と同時にスパイクを示しています。Visit Dashboard リンクをクリックすれば、相関ダッシュボードに直接移動し、さらに調査することができます。
アラートのコンテキストを増やす
アラートの 1 つがトリガーされると、Watchdog は、トリガーされた関連アラートを自動的に表示するようになったため、状況をすばやくトリアージできます。Watchdog は、Datadog の過去のインシデントでトレーニングされた機械学習アルゴリズムを使用して関連するアラートを検索します。アクティブなアラートを表示すると、Watchdog により、トラブルシューティングに役立つコンテキストを提供できる他のアクティブなアラートを簡単に見つけることができます。

上のスクリーンショットのアラートには、Watchdog が関連するアラートを検出したことを示すメッセージが含まれています。メッセージをクリックすると、関連するすべてのアラートと、影響を受けるサービスの依存関係マップを表示するサイドパネル (以下に表示) を開くことができます。これで、アップストリームサービスに対して同時に発生するアラートがあるかどうかを簡単に確認し、詳細情報のために確認するべきダッシュボードがどれかを知ることができます。

Kubernetes の異常を調査する
Watchdog では、Kubernetes クラスターの健常性とパフォーマンスの可視性が強化されました。たとえば、Watchdog を使用して、クラスターのスケジューリングレイテンシーの増加、および障害、準備ができていない、または使用不可の状態にあるポッドの数の増加を自動的に検出できます。これらのメトリクスのいずれかが増加すると、サービスのアップタイムに影響を与え、SLO に干渉する可能性があります。
以下に示すサンプルストーリーでは、Watchdog は、準備ができていない状態にある StatefulSet レプリカの割合の大幅な増加を検出しました。異常の範囲を明確にするために、ストーリーには関連する env、service、kube_cluster_name、kube_namespace タグも表示されます。

ストーリーの Overview セクションには、検出された異常の要約が表示されます。この場合、準備ができていないポッドの割合が増加したこと、問題のコンテキストと分析、および関連する Kubernetes ドキュメントへのリンクが表示されています。ストーリーの Suggested next steps セクションには、問題のトラブルシューティングと解決方法に関するガイダンスがあります。
Watchdog ストーリーには、関連するモニターのリストも含まれているため、報告された問題のコンテキストでモニターの状態を確認できます。また、Watchdog は、ワンクリックで有効にできる新しいモニター (下のスクリーンショットに表示) を提案し、今後チームに同様の問題が通知されるようにします。

Watchdog による根本原因の発見のサポート
最新の Watchdog 機能が一般に公開されました。すでに Watchdog をご利用の場合は、これらの新機能はすぐに使用できます。セットアップは必要ありません。Watchdog の詳細については、ドキュメントを参照してください。Datadog をまだご使用でない場合は、14 日間の無料トライアルにご登録ください。
