

VMware’s vSphere is a virtualization platform that allows users to provision and manage one or more virtual machines (VMs) on individual physical servers using the underlying resources. With vSphere, organizations can optimize costs, centrally manage their infrastructure, and set up fault-tolerant virtual environments. Instead of using one physical server for each application you run, virtualization enables you to allocate a server’s resources across multiple VMs so you can host multiple isolated operating systems that run different workloads on a single machine, allowing more efficient use of the same physical resources and reducing spending on storage space and hardware maintenance.
VMware also provides VM cluster management tools like the Distributed Resource Scheduler (DRS), which uses vMotion to automatically distribute shared physical resources to VMs based on their needs. In cases where downtime is expected for a particular server (e.g., for maintenance) or a server is overburdened, vMotion can also be used to migrate a VM to another server with zero downtime. Together, DRS and vMotion help make your virtual environment resilient and fault tolerant.
If your organization is using vSphere to run applications, it’s vital that you pay close attention to your environment’s overall performance and capacity at different layers, including the VMs running workloads and the underlying hosts. This helps ensure that available resources meet the demands of the applications and services running on your vSphere infrastructure.
Performance and capacity management go hand-in-hand. For instance, if your applications and workloads experience a bottleneck, it can lead to degraded performance or even downtime if you do not have the necessary resource capacity. For vSphere administrators, monitoring can help rightsize virtual machines so that resources are optimally distributed between them. If you are a developer, monitoring vSphere will help ensure that your applications running on VMs behave as expected.
In this post we will cover key metrics that provide insight into the health, performance, and capacity of your vSphere infrastructure. This includes metrics from both the physical and virtual components of your vSphere infrastructure, divided into the following categories:
Before diving into these metrics, let’s look at how vSphere works. Or, you can jump straight to the metrics.
vSphere overview and terminology
VSphere consists of a collection of components that make up its virtualization platform. For monitoring purposes, there are two core components to be aware of:
ESXi hypervisors
ESXi is the bare-metal hypervisor that runs on each physical server and enables vSphere to run VMs on that server. ESXi hypervisors run an operating system called the VMKernel on their underlying bare metal hosts. The VMKernel is responsible for decoupling resources from the physical servers that ESXi hypervisors are installed on and provisioning those resources to VMs.
Servers running ESXi hypervisors are called ESXi hosts. By default, ESXi hosts allocate physical resources to each running VM based on a variety of factors, including what resources are available (on a host or across a group of hosts), the number of VMs currently running, and the resource usage of those VMs. If resources are overcommitted (i.e., total resource allocation exceeds capacity), there are three settings that you can customize in order to manage and optimize how the ESXi host allocates resources:
Shares allow you to prioritize certain VMs by defining their relative claim to resources. For example, a VM with half as many shares of memory as another can only consume up to half as much memory.
Reservations define a guaranteed minimum amount of a resource that the ESXi host will allocate to a VM.
Limits define a maximum amount of a resource that the ESXi host will allocate to a VM.
By default, VMs will have shares based on their allocated resources. In other words, if a VM is allocated twice as much vCPU as another VM, it will have twice as many CPU shares. Shares are also bound by any configured reservations or limits, so even if a VM has more shares, the host will not allocate more resources than its set limit.
You can also partition the physical resources of one or more ESXi hosts into logical units called resource pools. Resource pools are organized hierarchically. A parent pool can contain one or more VMs, or it can be subdivided into child resource pools that share the parent pool’s resources. Each child resource pool can in turn be subdivided further. Resource pools add flexibility to vSphere resource management, making it possible to silo resource consumption across your organization (e.g., different departments and administrators are assigned their own resource pools).
The vCenter Server
The vCenter Server is vSphere’s centralized management component for ESXi hosts. Through the vCenter Server, vSphere administrators can monitor the health and status of all their connected ESXi hosts. The vCenter Server also provides a centralized utility for spinning up, configuring, and monitoring VMs on the ESXi hosts it manages. ESXi hosts managed by a single vCenter Server can be grouped into clusters. The VMs running on hosts in the same cluster share resources between them, including CPU, memory, storage, and network bandwidth.
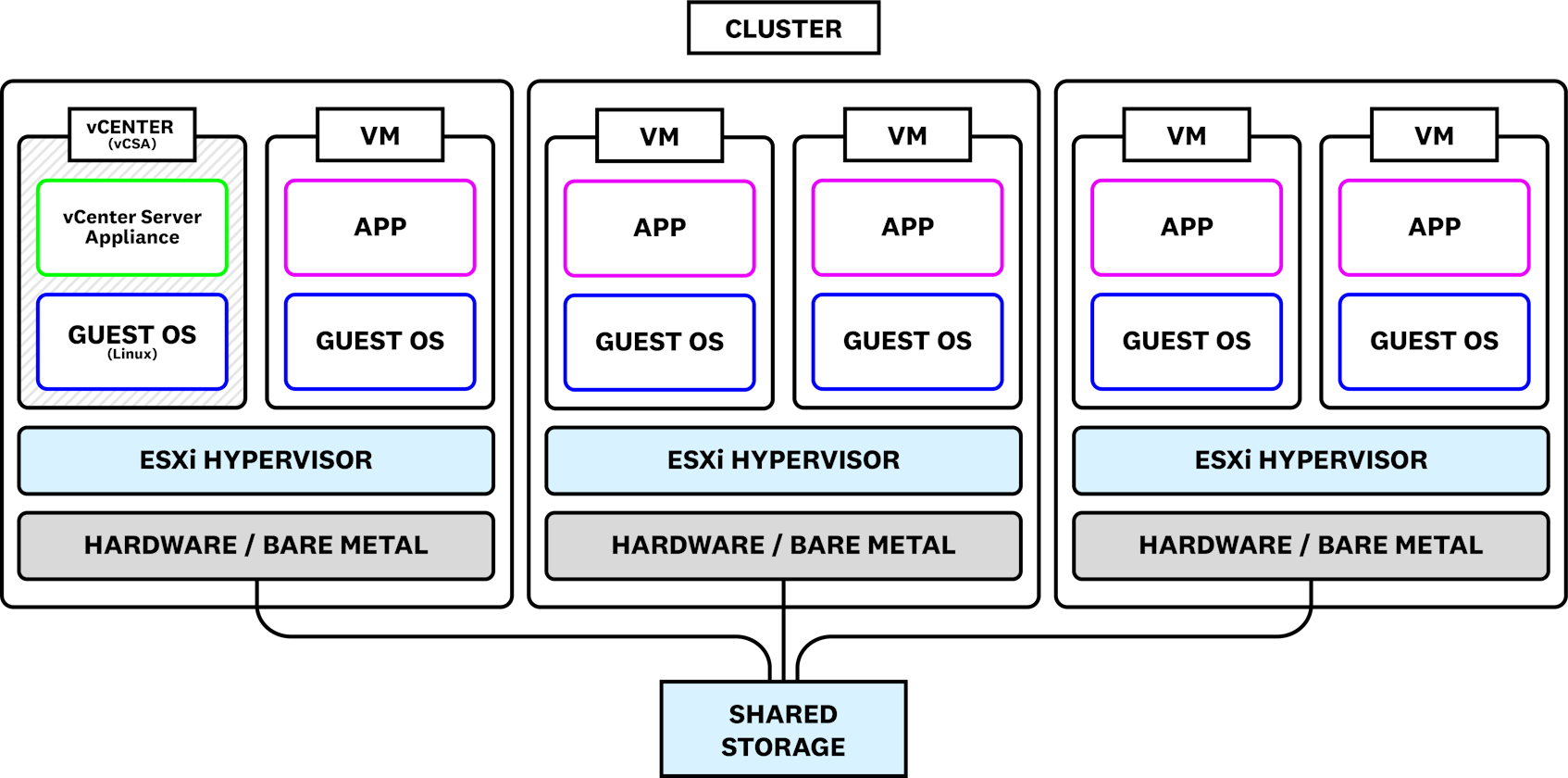
You can deploy the vCenter Server in two ways. You can install and run it on a server (either physical or virtual) running Microsoft Windows Server 2008 SP2 or later, or you can use a vCenter Server Appliance (vCSA), which is a Linux VM optimized to run the vCenter Server. The following diagram shows one cluster of a data center. The cluster is made up of three ESXi hosts, each hosting two virtual machines (including the vCenter Server) running their own applications and guest operating systems.
Key vSphere metrics to monitor
Now that we’re familiar with a few of vSphere’s main components and its general architecture, let’s take a look at the critical metrics you’ll want to pay close attention to in order to monitor your vSphere environment at the VM, host, and cluster levels. While vSphere emits hundreds of metrics, here we’ve identified a few key ones to focus on. As mentioned above, these metrics can be broken down into five broad categories:
- Summary metrics for high-level insight into infrastructure size and health
- CPU metrics pertaining to usage, availability, and readiness
- memory metrics that track swapping, ballooning, and overhead
- disk metrics, which provide visibility into disk health and performance
- network metrics, which track network activity and throughput
We’ll also look at vSphere events that provide insight into cluster activity and the health and status of the components of your virtual environment.
When monitoring vSphere, it’s important to track the status and performance of each layer of your environment, from VMs to the ESXi hosts running them to the clusters that make up your infrastructure. It’s helpful to keep in mind which parts of your infrastructure provide resources and which parts consume them. For example, VMs consume resources from physical resources like ESXi hosts and clusters. Resource pools can both provide and consume resources because they can be assigned the role of parent and child at the same time (i.e., the child of one resource pool can be the parent of another). As you monitor vSphere, you’ll want to ensure resources are readily available, used efficiently, and not over consumed by specific parts of your infrastructure at the expense of the rest of your environment.
This article refers to metric terminology from our Monitoring 101 series, which provides a framework for metric collection and alerting.
Summary metrics
Summary metrics from vSphere provide you with a high-level view of the size and health of your infrastructure, reporting things like a count of clusters in your environment and the number of hosts and virtual machines that are currently running. Keeping track of the size of your vSphere environment can help you make allocation decisions, since you’ll know how many hosts and VMs will request resources.
| Metric | Description | Metric type |
|---|---|---|
| Host count | Total number of hosts in your environment | Other |
| VM count | Total number of virtual machines in your environment | Other |
Metrics to watch: Number of ESXi hosts and VMs
Monitoring total counts of ESXi hosts and virtual machines can provide a high-level overview of the status of your vSphere environment. If there are significant variations in either, or if the reported number of hosts or VMs is significantly different from how many you expect to have, it’s worth investigating. For example, if there’s an unexpected drop in VMs, it could be a sign of misconfiguration or resource contention within the hosts. In the case of VMs, you can check your vSphere logs to troubleshoot the cause.
CPU metrics
In vSphere, there are two layers of CPU metrics to consider: physical CPU (pCPU) and virtual CPU (vCPU). As their names suggest, pCPU refers to the number of processors available on physical hosts while vCPU refers to the number of logical processors available on a host that are assigned to a virtual machine.
While a VM sees vCPU as its own physical processing capacity, any workloads on that VM are run on the pCPU of its host. By default, ESXi hosts schedule VM workloads across all available pCPUs, meaning that all VMs on a host are sharing processor time. If the number of allocated vCPUs across all VMs is equal to or less than the pCPUs available, there is no contention. But, for more efficient resource usage, it’s normal for the number of allocated vCPUs across all VMs to be greater than the number of available pCPUs (i.e., overcommitted) because it’s unlikely that all VMs will require 100 percent of their vCPUs at the same time. But, the more that ratio increases, the more VMs will likely have to wait on each other to run before they can access physical CPU. The more time VMs spend waiting for CPU access, the slower tasks will take to execute and the more degraded overall VM performance will be.
To monitor your vSphere environment effectively, it’s important to collect CPU metrics from both the physical and virtual layers. This includes knowing how much CPU is physically available on your hosts and across clusters and how much your VMs are using, which will help you determine if your virtual environment is running smoothly and whether you need to scale it up or down or adjust CPU allocation to specific VMs by configuring shares or setting reservations and limits.
| Metric | Description | Metric type |
|---|---|---|
cpu.readiness.avg | Average percentage of time a VM is spending in a ready state, waiting to access pCPU | Resource: Saturation |
cpu.wait | Total amount of time (ms) a VM is spending in a wait state (i.e., VM has access to CPU but waiting on additional VMKernel operations) | Work: Performance |
cpu.usage.avg | Percentage of an ESXi host’s pCPU capacity being used by the VMs running on it | Resource: Utilization |
cpu.TotalCapacity.avg | Total pCPU capacity (MHz) of an ESXi host available to VMs | Resource: Availability |
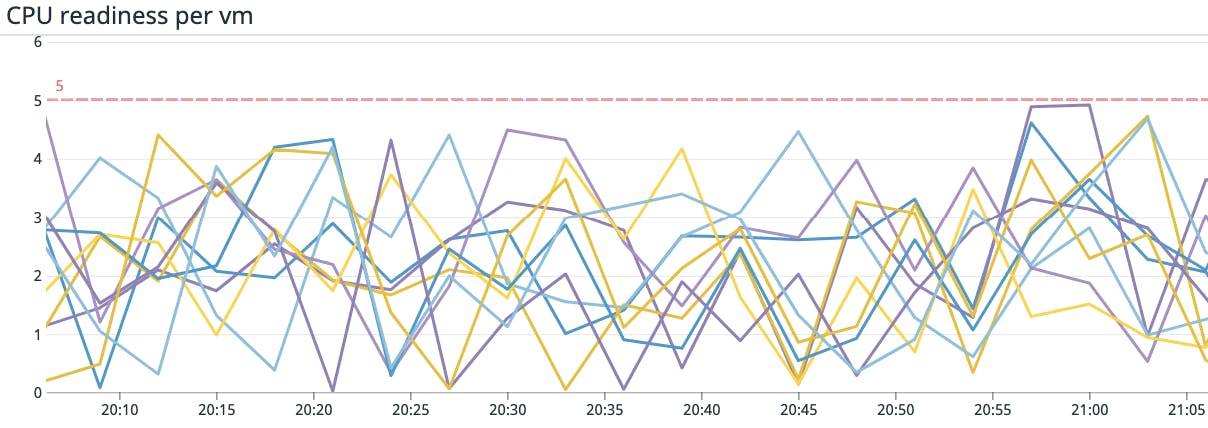
Metric to alert on: CPU readiness
The CPU readiness metric tracks the percentage of time a virtual machine is ready to run a workload but has to wait on the ESXi host to schedule it due to there not being enough physical CPU available. Monitoring CPU readiness time can give you a good idea of whether or not your VMs are running efficiently or spending too much time waiting and unable to run their workloads.
While some CPU readiness time can be normal, VMware recommends setting an alert to let you know if this metric surpasses 5 percent. VMs that spend a significant percentage of their time in a ready state will be unable to execute tasks, which can lead to poor application performance and possibly timeout errors and downtime.
The main cause of long readiness times is too many VMs contending for CPU on the same ESXi host. But other factors can contribute as well. For instance, you may be using CPU Affinity, which lets you assign VMs to a specific subset of processors on the ESXi host. In some cases, CPU Affinity can help optimize applications by guaranteeing that VMs running certain workloads run on specific physical processors. But enabling CPU Affinity on too many VMs may lead to high CPU readiness values as those VMs contend to run on the same processor. You can avoid this by limiting the number of VMs with CPU Affinity enabled.
CPU readiness may also be a result of placing overly restrictive CPU limits on VMs. Though limits may help avoid over allocating CPU, if those limits are too low to provide enough headroom for spikes in usage, it could prevent the ESXi host from scheduling a VM’s workload if it’s requesting access to more CPU than its limit.
Metric to watch: CPU wait
Whereas CPU readiness is the percentage of time a VM is waiting for available CPU, the CPU wait metric tells you how much time, in milliseconds, a VM that has been scheduled by the ESXi host is idle or waiting for VMKernel activity to complete before running. VMkernel activities that can contribute to increased CPU wait time include I/O operations and memory swapping.
A high CPU wait doesn’t necessarily indicate an issue. Since the CPU wait metric combines a VM’s idle time (cpu.idle) with time spent waiting on the VMKernel to complete separate tasks, a high value in this metric may just mean the VM has completed its tasks and is thus idle. To determine if high wait times are a result of waiting on I/O operations and memory swapping, you can look at the difference between the reported CPU wait time and CPU idle time.
If you’ve determined that high CPU wait times are a result of waiting on VMKernel activity, this could lead to degraded VM performance and you should further investigate the memory and disk metrics we look at later in this post to identify a possible cause.
Metric to watch: CPU usage
CPU usage can be a key indicator for general performance of your vSphere environment and it’s important to monitor it at different levels. At the host level, cpu.usage.avg metric lets administrators track what percent of an ESXi host’s available physical CPU is being used by the VMs running on it. If VMs begin to use a large portion of a host’s CPU (e.g., above 90 percent), they may start to experience increased CPU readiness and subsequent latency issues as VMs start to contend for resources.

You should also monitor CPU usage at the VM level. Depending on the type of workload your VMs are running, it might be common for the VMs on certain hosts to utilize CPU near capacity (e.g., for scheduled heavy workloads), so it is important to monitor this metric to establish a baseline and then to look out for anomalous behavior.
Monitoring CPU usage both of your hosts and the individual VMs can help identify issues like underutilized hosts or poorly placed VMs. For example, if you see that your VMs are consistently using high CPU, you will need to either scale up your ESXi hosts, adjust the CPU allocation settings of your VMs, or, if VMs are running on a standalone host, add the host to a cluster for access to more CPU.
Metric to watch: CPU total capacity
Virtual machines running on the same host or cluster all share pCPU, so overall capacity can be a common resource bottleneck and is often a good place to investigate performance problems. In vSphere, total capacity describes the total amount of pCPU, measured in megahertz, that’s available to be scheduled to VMs. This depends on the physical capacity of your ESXi hosts (that is, the number of processors and cores) and their specifications (for example, whether they support hyperthreading).
You can view this metric either at a per-host or, for a broader view of available CPU resources, a per-cluster level. If you’ve been notified of high CPU readiness, it may mean that there’s a lack of total available capacity on your host and, as consequence, VMs have been forced to wait longer for CPU access. You can remedy this by, for example, adding your ESXi host to a cluster with greater CPU capacity.
Memory metrics
As with CPU, memory can often be a leading resource constraint in virtual environments where many VMs must share a limited underlying capacity. In vSphere, there are three layers of memory to be aware of: host physical memory (the memory available to ESXi hypervisors from underlying hosts), guest physical memory (the memory available to operating systems running on VMs), and guest virtual memory (the memory available at the application level of a VM).
Each VM has a configured amount of its host physical memory that the guest operating system may access. This configured size is different, however, from how much memory the host may actually allocate to it, which depends on the VM’s need as well as any configured shares, limits, or reservations. For example, though a VM may have a configured size of 2 GB, the ESXi host might only need to allocate 1 GB to it based on its actual workload (i.e., any running applications or processes). Note that, if no memory limit has been set on a VM, its configured size will act as its default limit.
When a virtual machine starts, the ESXi hypervisor of its underlying host creates a set of memory addresses matching the memory addresses presented to the guest operating system running on the virtual machine. When an application running on a VM attempts to read from or write to a memory page, the VM’s guest OS translates between guest virtual memory and guest physical memory as if it were a non-virtualized system. The guest OS, however, does not have access to and so cannot allocate host physical memory. Instead, the host’s ESXi hypervisor intercepts memory requests and maps them to memory from the underlying physical host. ESXi also maintains a mapping (called shadow page tables) of each memory translation: guest virtual to guest physical, and guest physical to host physical. This ensures consistency across all layers of memory.
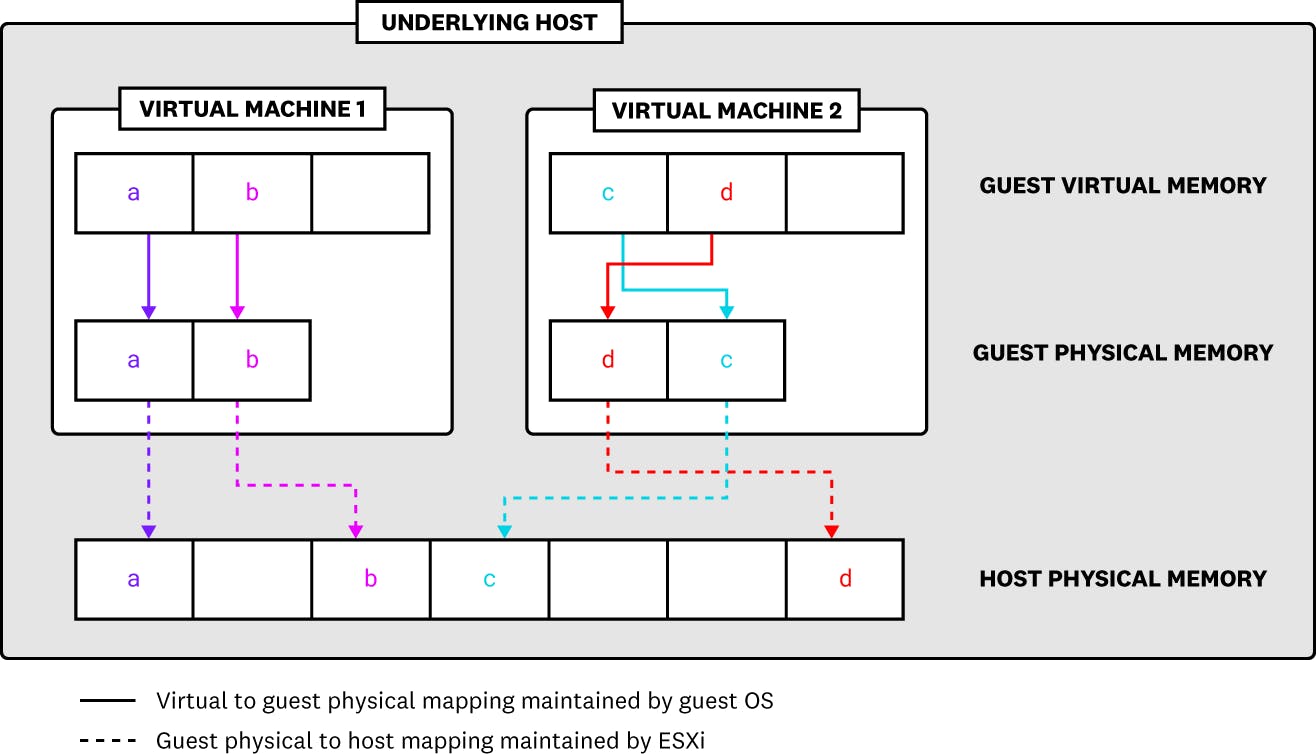
This approach to memory virtualization means that each VM only sees its own memory usage while the ESXi host can allocate and manage memory across all running VMs. However, the ESXi host cannot determine when a VM frees up, or deallocates guest physical memory. Nor does a VM know when the ESXi host needs to allocate memory to other VMs. If guest physical memory across all running VMs (plus any necessary overhead memory usage) is equal to the host’s physical memory, this is not a problem. But, in cases where memory is overcommitted (i.e., aggregate guest physical memory is greater than the host physical memory), ESXi hosts will resort to memory reclamation techniques such as swapping and ballooning in order to reclaim free memory from VMs and allocate it to other VMs. Resource overcommitment and memory reclamation strategies help optimize memory usage, but it’s important to monitor metrics that track ballooning and swapping because excessive use of either can result in degraded VM performance. We’ll cover these processes in more detail in the relevant metrics sections below.
| Metric | Description | Metric type |
|---|---|---|
mem.vmmemctl | Amount of memory (KiB) in the memory balloon driver that the host will reclaim when it’s low on memory | Resource: Saturation |
mem.swapin | Amount of memory (KiB) an ESXi host swaps in to a VM from disk (physical storage) | Resource: Saturation |
mem.swapout | Amount of memory (KiB) an ESXi host swaps out from a VM to disk (physical storage) | Resource: Saturation |
mem.active | Amount of allocated memory (KiB) a host’s VMkernel estimates a VM is actively using | Resource: Utilization |
mem.consumed | Amount of memory of host physical memory (KiB) that is actually allocated to a VM | Resource: Utilization |
mem.usage.avg |
| Resource: Utilization |
mem.TotalCapacity.avg | Amount of memory of physical host (MiB) reserved for and available to VMs | Resource: Utilization |
Metric to alert on: Balloon driver (vmmemctl) capacity
Each VM in vSphere can have a balloon driver (named vmmemctl) installed on it. If an ESXi host runs low on physical memory that it needs to allocate (i.e., less than 6 percent free memory), it can reclaim memory from the guest physical memory of virtual machines. However, because ESXi hypervisors have no knowledge of what memory is no longer in use by VMs, they send requests to the balloon drivers to “inflate” by gathering unused memory from the VM. The ESXi host can take that memory from the “inflated” balloon driver and deallocate the appropriate mapped host physical memory, which it can then allocate to other VMs. This technique is known as memory ballooning.
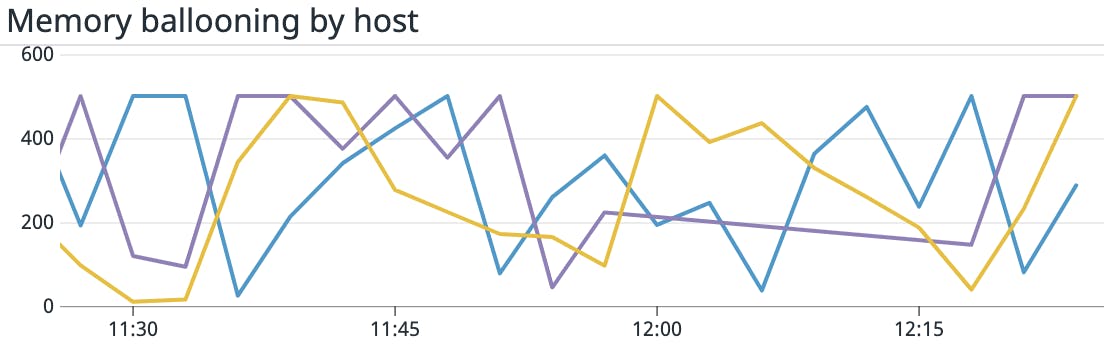
While ballooning can assist ESXi hosts when they are short on memory, if done too often it can degrade VM performance if the guest operating system later can’t access memory that’s been stored by the balloon driver and reclaimed by the host. And, if ballooning isn’t sufficient, ESXi hosts may begin to use swap memory to meet the memory demands of VMs, which will result in a severe degradation in application performance.
If your environment is healthy and virtual machines are properly rightsized, memory ballooning should generally be unnecessary. Therefore, you should set up an alert for any positive value for mem.vmmemctl, which would indicate that the ESXi host is out of available memory.
Metrics to alert on: Memory swapped in/out
When an ESXi host provisions a virtual machine, it allocates physical disk storage files known as swap files. Swap file size is determined by the VM’s configured size, less any reserved memory. For instance, if a VM is configured with 3 GB of memory and has a 1 GB reservation, it will have a 2 GB swap file. By default, a VM’s swap files are collocated with its virtual disk, on shared storage.
If host’s physical memory begins to run low, and memory ballooning isn’t reclaiming sufficient memory to meet demands quickly enough (or if the balloon driver is disabled or never installed), ESXi hosts will begin using swap space to read and write data that would normally go to memory. This process is called memory swapping.
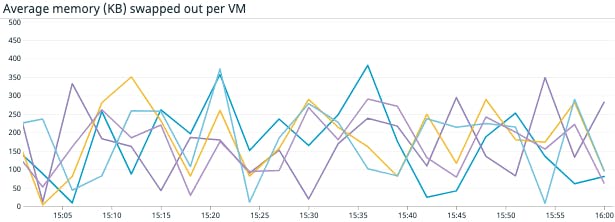
Reading and writing data to disk takes much longer than using memory and can drastically slow down a VM, so memory swapping should be regarded as a last resort. Ensure that swapping is kept at a minimum by setting alerts to notify you of any spikes and you can decide how to resize virtual machines if necessary. If you notice an increase in swapping, you might also want to check on the status of VM balloon drivers as swapping may indicate that ballooning has failed to reclaim sufficient memory.
Metrics to watch: Active memory versus consumed memory
In order for a VMKernel to accurately discern how much memory is actively in use by VMs, it would need to monitor every memory page that has been read from or written to. This process, however, would require too much overhead. Instead, the VMKernel uses algorithmic learning to generate an estimate of each VM’s active memory usage. The VMKernel reports this estimate, measured in KBs, as the mem.active metric. Consumed memory, measured by the mem.consumed metric, represents the amount of an underlying host’s memory that’s allocated to a VM.
Active memory is a good real-time gauge of your VMs’ memory usage, and monitoring it alongside consumed memory can help you determine if virtual machines have sufficient memory allocated to them. If a VM’s active memory is consistently significantly below it’s consumed memory, it means it has more memory allocated to it than it needs and, as a consequence, the host has less memory available for other VMs than it could. To amend this, consider changing your VM’s configured size or memory reservation.
Metric to watch: Memory usage
At the VM level, the mem.usage metric measures what percentage of its configured memory a VM is actively using. Ideally, a VM should not always be using all of its configured memory. If it is consistently using a large portion of its configured memory, the VM will be less resilient to any spikes in memory usage if its ESXi host cannot allocate additional memory. If this is the case, consider reconfiguring VM memory size, updating its memory allocation settings (shares, reservations, etc.), or migrating the VM to a cluster with more memory.
At the host level, memory usage represents the percentage of an ESXi host’s physical memory that is being consumed. If memory usage at the host level is consistently high, it may not be able to provision memory to the VMs that need it and it will need to run memory ballooning more often or may even begin to start swapping memory.
Disk metrics
Virtual machines use large files (or groups of files) called virtual disks (also called VMDK or, Virtual Machine Disk files) to store their operating system files and guest applications. VMs start with one virtual disk by default, but you can configure them to have more. Virtual disks are located in datastores, which can reside in a variety of shared storage locations, depending on configuration. Storage options for datastores include local and networked storage, storage area networks (SANs), and logical unit number (LUN) storage devices.
VSphere reports disk I/O and capacity metrics at different levels, including datastores, virtual machines, and ESXi hosts. Because multiple hosts and VMs can share datastores, monitoring at the datastore level can provide you with a high-level, aggregated view of disk performance. However, to track the health of a specific VM or host, make sure to monitor the performance of both your virtual disks (i.e., what your guest operating systems experience) and physical disks (i.e., what your hosts experience). Tracking disk metrics at each of these levels can help provide a more complete picture of cluster health and troubleshoot where issues are occurring.
VMs use storage controllers to access the virtual disks in a datastore. Storage controllers let VMs send commands to the ESXi host they’re running on, which then redirects those commands to the appropriate virtual disk. Because VMs send commands to datastores through ESXi hosts, monitoring metrics that provide insight into command throughput and latency can help you ensure that hosts and VMs are able to access physical storage effectively and without interruption.
| Metric | Description | Metric type |
|---|---|---|
disk.commandsAborted | Total number of I/O commands aborted by the ESXi host | Work: Error |
disk.busReset | Number of disk bus reset commands by the virtual machine | Work: Error |
diskspace.provisioned.latest | Amount of storage (KB) available in a datastore | Resource: Utilization |
virtualDisk.actualUsage | Amount of datastore storage (KB) that is actually being used by the VMs running on a host | Resource: Utilization |
disk.totalLatency.avg | Average amount of time (ms) it takes an ESXi host to process a command issued by a VM | Work: Performance |
<component>.readLatency.avg | Average amount of time (ms) it takes the specified component to process a read command | Work: Performance |
<component>.writeLatency.avg | Average amount of time (ms) it takes the specified component to process a write command | Work: Performance |
disk.queueLatency.avg | Average amount of time (ms) each I/O command spends in VMkernel queue before being executed | Work: Performance |
<component>.read.avg | Average amount of data (KB/s) read by the specified component | Work: Throughput |
<component>.write.avg | Average amount of data (KB/s) written to a specified component | Work: Throughput |
disk.usage.avg | Average disk I/O (KB/s) of a specified component | Work: Throughput |
Metric to alert on: Disk commands aborted
In vSphere, a single storage device cluster may hold datastores that serve many virtual machines. If there is a surge of commands from virtual machines to the storage hardware where datastores are located, that storage may become overloaded and unresponsive. If that occurs, the ESXi host that sent those commands will abort them. Because aborted commands can cause VMs to perform slowly and even crash, you will want the disk.commandsAborted metric to remain at zero. If an ESXi host begins to abort commands, and you’ve determined the cause is overwhelmingly high VM command traffic to the datastore, you can migrate VMs across more storage backends to avoid sending all requests to a single datastore.
Metric to alert on: Disk bus resets
If a storage device is overwhelmed with too many read and write commands from an ESXi host, or if it encounters a hardware issue and fails to abort commands, it will clear out all commands waiting in its queue. This is called a disk bus reset. Disk bus resets are a sign of a disk storage bottleneck and can cause slower VM performance, as VMs will need to resend those requests. Disk bus resets typically do not occur in healthy vSphere environments, so you should investigate any VM with a positive value for the disk.bus.reset metric. To resolve this issue, administrators may need to use Storage vMotion to redistribute VMs and virtual disks across different datastores to optimize performance.
Metrics to alert on: Datastore provisioned capacity and actual VM usage
Storage is a finite resource. The diskspace.provisioned.latest metric tracks how much storage space is available on the datastores that the ESXi host communicates with, while virtualDisk.actualUsage lets you monitor how much disk space the VMs running on that host are actively using. Correlating these metrics can help you monitor if you have provisioned a reasonable amount of disk space for what your VMs need.
Using close to all of a datastore’s disk capacity can cause out of space errors and degrade VM performance. To prevent this, you can set up an alert when VM usage of your datastore’s provisioned storage capacity becomes excessive (e.g., over 85 percent). If datastore usage is at or near capacity, consider extending its capacity, migrating VMs to another datastore, or removing idle VMs with virtual disks taking up storage space.
Metric to watch: Disk latency
Monitoring latency is key to ensuring that your VMs are communicating with their virtual disks efficiently and without delay. Total disk latency measures the time it takes, in milliseconds, for an ESXi host to process a request sent from a VM to a datastore. Monitoring the total disk latency can help you determine whether vSphere is performing as expected. Latency spikes or sustained high latency are good indicators that there is an issue in your environment, but they can have a variety of causes, including resource bottlenecks or application-level problems.
If you notice an issue with total latency, you can also check the average latency of read (disk.readLatency.avg) and write (disk.writeLatency.avg) operations to determine if one or the other is contributing more to the overall latency. Similarly, you can break down read and write latencies at the VM, host, and datastore level to determine what inventory objects are contributing to the increase in total latency.
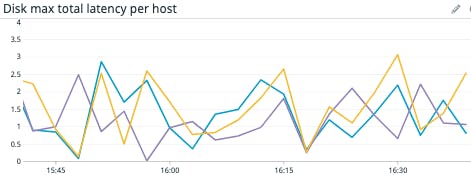
Correlating high disk latency with other resource usage metrics can be helpful in determining if the root cause is a lack of available memory or CPU. In that case, you can identify which virtual machines on your host or cluster have the highest resource consumption, and either allocate more resources to those machines or migrate them to datastores with greater capacity. You can also look at queue latency to determine whether an increase in requests sitting queued without being processed preceded the increase in latency.
Metric to watch: Queue latency
Depending on their configuration, storage devices like LUNs have a limited number of commands they can queue at any one time. When the volume of virtual machine commands sent from an ESXi host exceeds what a storage device can queue itself, those commands will begin to queue in the VMKernel. The disk.queueLatency metric tracks the average amount of time that commands from a VM spend waiting in a VMkernel’s queue. The longer a command waits in a queue to be processed by the disk, the worse the VM that sent that command will perform. High queue latency is closely tied to high total latency, as commands usually have to wait in a queue because the storage device is taking a long time to process current commands.
Monitor queue latency alongside disk.usage.avg for a better understanding of your environment’s performance. For example, you can determine if a rise in queue latency corresponds to an overall drop in throughput. Similarly, you can see if heightened throughput preceded a spike in queue latency because your datastore was unable to process the pressure increase.
Like total latency, queue latency can be resolved by migrating VMs to a datastore with greater disk capacity, increasing queue depth of your datastore, or enabling storage I/O control. With storage I/O control enabled, you can grant VMs resource shares of storage and a command latency threshold that, once passed, will tell vSphere to start allocating storage to VMs based on their shares. This can help relieve I/O pressure and reduce queue latency.
Metric to watch: Disk throughput
To ensure that your datastores, ESXi hosts, and VMs are processing read and write commands without interruption, monitor their I/O throughput for visibility into their activity. Monitoring throughput at multiple levels and correlating it with other metrics can help you spot bottlenecks and pinpoint where an issue may be occurring. For example, if a spike in VM read commands issued to an ESXi host preceded a spike in total latency, it could indicate that the ESXi host struggled to process the flood of requests.
While there may be various causes for a sustained spike in throughput, you can mitigate the issue with actions like provisioning more memory to your VMs. This will enable VMs to cache more data and rely less on swapping.
Network metrics
A vSphere environment is made up of a network of physically connected servers running the ESXi hosts, and one or more networks of logically connected virtual machines running on the same host. It’s important to collect usage and error metrics from both the physical and virtual networks across your environment to ensure healthy connectivity. Network connectivity issues can prevent you from executing key vSphere tasks, like VM provisioning and migration, that require network communication.
Monitoring the network throughput of your hosts and virtual machines will help you establish whether your network is behaving as expected or whether it’s necessary to reconfigure your network settings (e.g., adding another network adapter to a VM).
| Metric | Description | Metric type |
|---|---|---|
net.received | Average rate of data (KB/s) received by an ESXi host or VM | Work: Throughput |
net.transmitted | Average rate of data (KB/s) received by an ESXi host or VM | Work: Throughput |
net.usage.avg | Average network throughput (KB/s) of an ESXi host or VM | Work: Throughput |
Metric to watch: Network received and network transmitted
These metrics track the network throughput, in kilobytes per second, of the object you’re observing whether it’s a host or a VM. These metrics, along with the total network usage metric (net.usage.avg) can provide a baseline understanding of network traffic between your ESXi hosts or VMs. If you’ve determined a baseline for network behavior, you can then set up an alert to notify you of deviations (i.e., spikes or drops) that may point to issues in your underlying hardware (e.g., a lost host connection) or a misconfigured Windows or Linux VM.
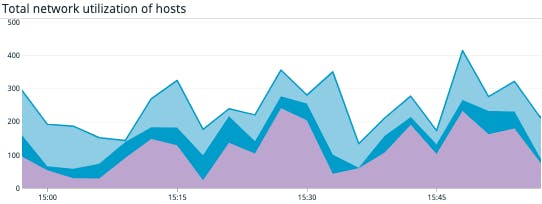
Tasks and events
By default, vSphere records tasks and events that occur in the VMs, ESXi hosts, and the vCenter Server of your virtual environment. These can include user logins, VM power-downs, certification expirations, and host connects/disconnects. Tasks and events from vSphere give you a high-level view of the health and activity of your virtual environment, reporting things like failures and errors to notify you when your environment is unhealthy.
Since tasks can be scheduled, checking their status will tell you where they are in their execution cycle. Monitoring tasks and events can also help clue you into how changes in your environment, like VM startups, can affect resource usage and lead to contention.
Each ESXi host records tasks and events in log files saved in various locations. A few important files include the following:
/var/log/vmkernel.log: VMKernel logs that include data on device discovery, storage and network events, and VM startups/var/log/syslog.log: System message logs that include data on scheduled tasks and interactions with ESXi hosts/var/log/auth.log: Authentication logs that include data on user logins and logouts/vmfs/volumes/datastore/<virtual machine>/vwmare.log: Virtual machine logs that include data about specific VMs, such as migrations and virtual hardware changes
Monitoring the events in these log files can help you stay aware of overall activity within your vSphere clusters and also perform audits and investigate any issues that occur in your environment.
Get visibility into your virtual environment and its supporting hardware
In this post we discussed the major components of vSphere and highlighted some key metrics you can use to help ensure your environment has the resources it needs and is performing as expected. We’ve also discussed how monitoring events in tandem with key metrics can give you a high level view of your environment’s status. In the next post of this series, we’ll explore some of the tools VMware offers to help you monitor both metrics and events.
