

In Part 1, we looked at the key metrics for monitoring the health and performance of your HashiCorp Vault deployment. We also discussed how Vault server and audit logs can give you additional context for troubleshooting issues ranging from losses in availability to policy misconfiguration. Now, we’ll show you how to access this data with tools that ship with Vault. In particular, we will look at how to:
- Query Vault’s HTTP APIs for telemetry data
- Run the
vault debugcommand for a quick overview of your cluster’s health and performance - Use Vault’s web-based UI to inspect your cluster
- View Vault server and audit logs
- Forward Vault data to a third-party monitoring solution for more detailed analysis
Query Vault’s HTTP APIs for telemetry data
Vault exposes HTTP APIs that allow operators to perform configuration tasks and gain insight into how their clusters are performing. In this section, we will briefly discuss a few endpoints that are particularly useful for monitoring.
Check on Vault’s health with /sys/health
First, you can invoke the /sys/health endpoint to view the health status of your Vault server in a JSON response:
$ curl http://127.0.0.1:8200/v1/sys/health
{
"initialized": true,
"sealed": true,
"standby": false,
"performance_standby": false,
"replication_performance_mode": "disabled",
"replication_dr_mode": "disabled",
"server_time_utc": 1600787470,
"version": "1.5.3",
"cluster_name": "vault-cluster-0da5669c",
"cluster_id": "d5638002-c2cd-f6d6-8548-dd2575af1af6"
}The response provides a high-level overview of your Vault server’s health, including its seal status, the cluster it belongs to, and the version it is running. In this example, the Vault is sealed, meaning that all its data is encrypted and it will not be able to respond to any incoming client requests.
Ensure your clusters are properly replicated with /sys/replication
In Part 1, we discussed how Vault supports performance replication to enhance scalability as well as disaster recovery replication to minimize downtime during a failure. To recap, a cluster assumes the leader role (primary) and has a number of followers (secondaries). Changes on the primary cluster are recorded as Write-Ahead Logs (WALs), which are then shipped to the secondary clusters and synchronized to create a replica. By querying the /sys/replication endpoint, you can identify the mode of the replicated cluster (i.e., primary or secondary) as well as the progress of WAL synchronizations.
curl http://127.0.0.1:8200/v1/sys/replication/statusThe output for a performance primary cluster should resemble the following:
{
"performance": {
"cluster_id": "1598d434-dfec-1f48-f019-3d22a8075bf9",
"known_secondaries": ["2"],
"last_wal": 291,
"merkle_root": "43f40fc775b40cc76cd5d7e289b2e6eaf4ba138c",
"mode": "primary",
"primary_cluster_addr": "",
"secondaries": [
{
"api_address": "https://127.0.0.1:49253",
"cluster_address": "https://127.0.0.1:49256",
"connection_status": "connected",
"last_heartbeat": "2020-06-10T15:40:46-07:00",
"node_id": "2"
}
],
"state": "running"
}
}Similarly, calling the endpoint on a performance secondary cluster would return something like the following:
{
"performance": {
"cluster_id": "1598d434-dfec-1f48-f019-3d22a8075bf9",
"known_primary_cluster_addrs": ["https://127.0.0.1:8201"],
"last_remote_wal": 291,
"merkle_root": "43f40fc775b40cc76cd5d7e289b2e6eaf4ba138c",
"mode": "secondary",
"primaries": [
{
"api_address": "https://127.0.0.1:49244",
"cluster_address": "https://127.0.0.1:8201",
"connection_status": "connected",
"last_heartbeat": "2020-06-10T15:40:46-07:00"
}
],
"state": "stream-wals"
}
}Comparing the responses from your primary and secondary clusters can help you determine if they are in sync. If they are, you should expect to see that:
stateof the secondary isstream-walslast_remote_walon the secondary matches thelast_walon the primary after writing replicated datamerkle_rooton the primary matches the secondary
Run the vault debug command for a deeper look at your cluster
Vault also comes with a command line interface (CLI) that lets you manage your clusters and retrieve telemetry data. The vault debug command is particularly useful for monitoring, as it allows you to gather a wide range of information about your Vault cluster over a given period of time, without having to make multiple API calls. The -target flag lets you specify the type of information to collect (e.g., metrics, runtime profiling data, replication status). If you do not specify any targets, Vault will collect all information by default. You can also configure how long you want the command to run (with the -duration flag) as well as how often you want to poll information (with the -interval flag for server status and profiling data, and the -metrics-interval flag for metrics). The following command configures Vault to collect data every 30 seconds for 30 minutes.
vault debug -interval=30s -duration=30mVault saves all the data it collects in a vault-debug-<TIMESTAMP>.tar.gz file. After unpacking the file, you should see the following collection of files:
$ tree vault-debug-2020-09-22T15-13-33Z
vault-debug-2020-09-22T15-13-33Z
├── 2020-09-22T15-13-33Z
│ ├── goroutine.prof
│ ├── heap.prof
│ ├── profile.prof
│ └── trace.out
├── 2020-09-22T15-14-03Z
│ ├── goroutine.prof
│ ├── heap.prof
│ ├── profile.prof
│ └── trace.out
├── 2020-09-22T15-14-33Z
│ ├── goroutine.prof
│ └── heap.prof
├── config.json
├── host_info.json
├── index.json
├── metrics.json
├── replication_status.json
└── server_status.json
[...]Except for profiling data, Vault writes all the data it gathers from each of the specified targets over the collection period to a single file. Profiling data—which includes goroutine, heap, and CPU profiles, as well as traces—is saved to a timestamped folder at each polling interval. You can inspect these files to check if your clusters are resourced well and running properly. config.json shows you how your cluster is set up, such as its configured storage backend, metrics sink, and logging level, while host_info.json provides host CPU, disk, and memory statistics. server_status.json contains the health and seal status of your cluster, which you can also obtain by querying the /sys/health and /sys/seal-status endpoints. Similarly, replication_status.json can help you identify if your clusters are replicating properly.
You can find metrics collected over the sampling interval in the metrics.json file. The example output below shows, in milliseconds, the time taken by GET operations at the barrier (vault.barrier.get) and the time taken by the core to perform token checks (vault.core.check_token). For each metric, Vault aggregates the datapoints collected during the sampling interval and outputs the aggregated values (max, mean, min, rate, stddev, and sum). Note that the available aggregations are dependent on the type of metric.
metrics.json
{
"Count": 12,
"Labels": {},
"Max": 0.012732000090181828,
"Mean": 0.005875916685909033,
"Min": 0.0034360000863671303,
"Name": "vault.barrier.get",
"Rate": 0.007051100023090839,
"Stddev": 0.002518771111541759,
"Sum": 0.0705110002309084
},
{
"Count": 8,
"Labels": {},
"Max": 0.05063299834728241,
"Mean": 0.0371350001078099,
"Min": 0.0298870000988245,
"Name": "vault.core.check_token",
"Rate": 0.02970800008624792,
"Stddev": 0.00721039418254755,
"Sum": 0.2970800008624792
}Alternatively, you can spot check metrics via the Vault HTTP API by sending a GET request to the /sys/metrics endpoint. Note that this call only returns data from the most recent metric collection and does not let you specify a custom interval. As you might recall, Vault aggregates metrics every 10 seconds and retains them in memory for one minute.
Use the built-in Vault web UI
Vault comes with a web-based UI that lets operators easily interact with and manage their clusters. To activate the UI, set the ui option in your Vault server configuration to true. Then, configure Vault to listen on at least one TCP port in the listener stanza.
config.hcl
ui = true
listener "tcp" {
address = "10.0.1.35:8200"
}The UI will now be accessible at https://<VAULT_ADDRESS>/ui/.
From the top bar, you can navigate to various tabs to perform operations, such as:
- Creating and deleting secrets
- Configuring authentication methods, entities, groups, and leases
- Managing access control list policies
- Wrapping, rewrapping, and unwrapping tokens using built-in tools
Besides displaying configuration information, the UI also provides some basic monitoring functionalities. For instance, you can view the seal status of your server along with a list of Raft peers to quickly identify any issues with availability. And from the Metrics view, you can get a quick summary of your Vault’s HTTP request volume, as well as the current count of entities and tokens:
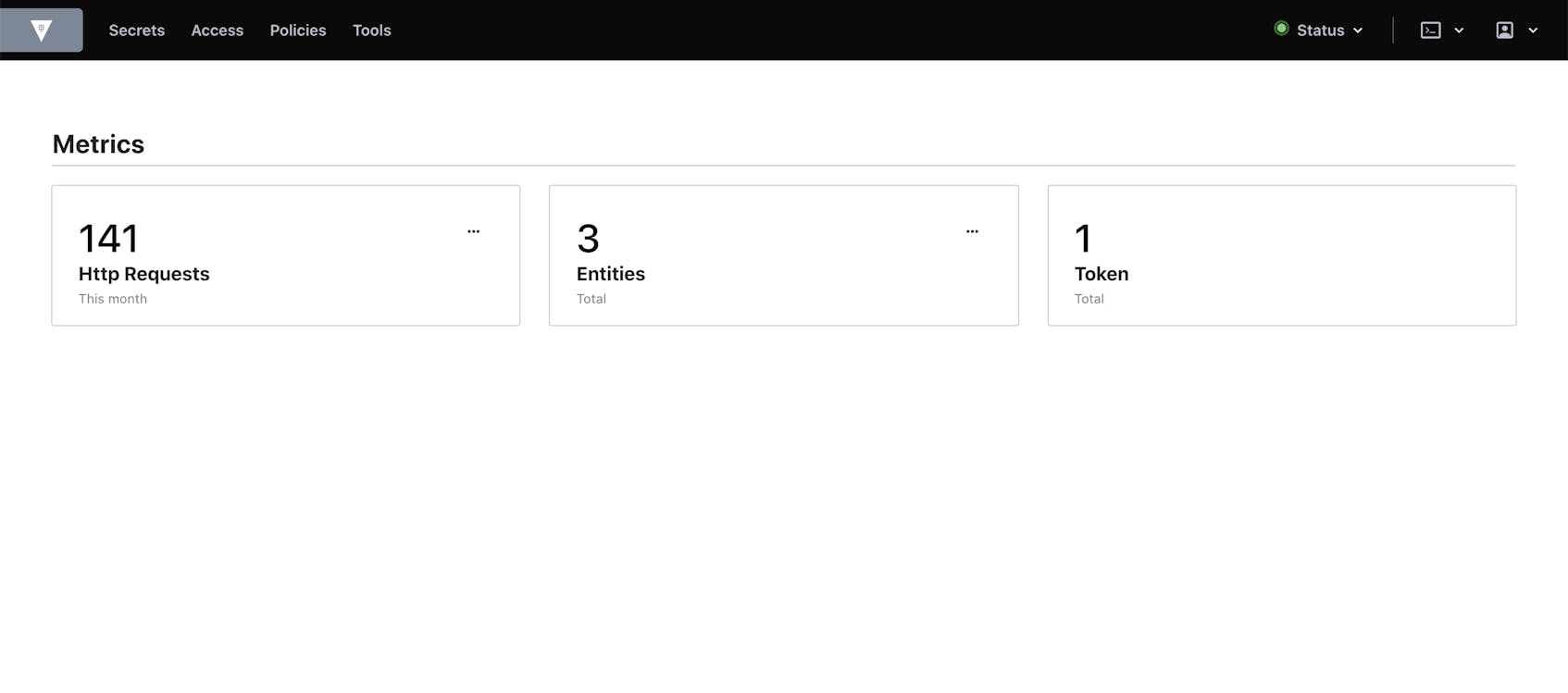
In general, the web UI is useful for simple configuration tasks but is insufficient for comprehensive monitoring. For instance, the UI only displays a small subset of the metrics we introduced in Part 1 and does not offer the rich visualization and graphing capabilities provided by external monitoring platforms, as we will explore later in this post.
View Vault server and audit logs
While metrics can alert you to anomalies in Vault’s behavior, you need logs to properly identify the root causes of these problems in your system. If your cluster’s throughput has plummeted, your audit logs will reveal if, for instance, a client was denied because it didn’t have the right permissions for a path. With this additional context, you can determine your next course of action, which might be to check your policies to see if they were misconfigured. In this section, we’ll dive into two types of logs that Vault generates: server logs and audit logs.
Server logs
Server logs are operational logs that contain information about the processes that occur internally as Vault runs. When your Vault server is starting up, for instance, you can expect to see a stream of logs that resemble the following:
$ vault server -dev
==> Vault server configuration:
Api Address: http://127.0.0.1:8200
Cgo: disabled
Cluster Address: https://127.0.0.1:8201
Go Version: go1.14.7
Listener 1: tcp (addr: "127.0.0.1:8200", cluster address: "127.0.0.1:8201", max_request_duration: "1m30s", max_request_size: "33554432", tls: "disabled")
Log Level: info
Mlock: supported: false, enabled: false
Recovery Mode: false
Storage: inmem
Version: Vault v1.5.3
Version Sha: 9fcd81405feb320390b9d71e15a691c3bc1daeef
...
==> Vault server started! Log data will stream in below:
2020-09-22T10:44:24.955-0400 [INFO] proxy environment: http_proxy= https_proxy= no_proxy=
2020-09-22T10:44:24.956-0400 [WARN] no `api_addr` value specified in config or in VAULT_API_ADDR; falling back to detection if possible, but this value should be manually set
2020-09-22T10:44:24.957-0400 [INFO] core: security barrier not initialized
2020-09-22T10:44:24.957-0400 [INFO] core: security barrier initialized: stored=1 shares=1 threshold=1
2020-09-22T10:44:24.960-0400 [INFO] core: post-unseal setup startingThe output begins with a summary of Vault’s logs configuration, including its cluster address, listener ports, log level, and storage backend type. The server then streams log entries continuously until it is explicitly stopped. Each entry contains a timestamp, log level, log source, and log message.
Choosing an appropriate logging level can help you isolate high-priority events and troubleshoot issues faster. To do this, you can either add the -log-level flag to your vault server command, set a log level using the VAULT_LOG_LEVEL environment variable (e.g., VAULT_LOG_LEVEL=debug), or include the log_level parameter in your Vault configuration (config.hcl). The default log level is INFO and setting a logging level configures Vault to log events that are of that priority level or higher. At any time, you can also use the vault monitor CLI command to output real-time server logs. The command will write logs to STDOUT until it is manually terminated.
Audit logs
In addition to server logs, Vault records every client interaction with Vault as audit logs. With audit logs, security operators can see which users or services requested access to Vault data—and why their requests were authorized or rejected. This is crucial for keeping your applications safe by ensuring that only legitimate recipients of secrets gain access to Vault. To collect audit logs, you will need to enable an audit device. Vault supports audit devices that write to a file, syslog, or a socket (e.g., TCP, UDP, UNIX). For example, you can enable the file audit device from the command line, as such:
$ vault audit enable file file_path=/vault/vault-audit.log
Success! Enabled the file audit device at: file/In the command above, we also specified the path of the file to write to
Datadog Cloud SIEM continuously monitors your Vault audit logs for potential threats. In Part 4 of this series, we’ll show you how to use Datadog to secure your Vault cluster.
Forward Vault telemetry data to a monitoring solution
Querying metrics via the command line can give you quick insight into the current health and performance of your Vault cluster. However, these metrics are only retained in-memory for one minute, making it difficult to track overall trends and perform long-term historical analysis. By exporting your telemetry data to a third-party monitoring solution, you can not only retain your data for a longer period of time but also correlate them with metrics and logs from other parts of your infrastructure, giving you greater visibility into your Vault cluster. Vault uses the go-metrics package to expose metrics—and you can choose to publish them to aggregation services, such as StatsD, DogStatsD, and Prometheus.
You can also configure a monitoring service to gather metrics from Vault’s HTTP APIs and correlate them with server and audit logs. In Part 3, we’ll show you how to use Datadog’s built-in integration to visualize and alert on key metrics and logs within minutes.
Monitor it all in one platform
With Vault’s built-in tools, you can get quick insight into the health and performance of your cluster. But as we saw in Part 1, Vault is composed of many moving parts—and also integrates with numerous third-party services—which means that you need comprehensive visibility across all this data in one place. Datadog integrates with more than 850 technologies, so you can monitor Vault side-by-side with the rest of your environment. Learn more in Part 3 of this series or get started with a free 14-day trial.
Acknowledgment
We would like to thank our friends at HashiCorp for their technical review of this post.
