

On April 19, 2024, Datadog’s US5 website (app.us5.datadoghq.com) started experiencing elevated error rates, though they were low enough that most of our users didn’t notice them. For the next few days, we worked around the clock responding to multiple episodes of this mysterious attack, which gradually unfolded as we investigated. We also implemented several measures to reduce the impact on our customers.
What at first seemed like a minor incident turned out to be a meticulously crafted denial-of-service (DoS) attack that targeted several Datadog regions. Eventually, we were able to fully understand and reproduce the attack as well as mitigate its root cause.
In this post, we’ll provide a deep dive into the most interesting technical details of the attack and how we responded to it.
Establishing a baseline: how clients reach Datadog
As part of an ongoing migration effort unrelated to this incident, we had set up L4 GCP External Network Load Balancers in various environments, shifting traffic towards them by using DNS weights. However, these were not set up for app.us5.datadoghq.com when the incident occurred, so an L7 GCP Classic Application Load Balancer served all traffic at that time.
This workflow is illustrated in the following diagram:
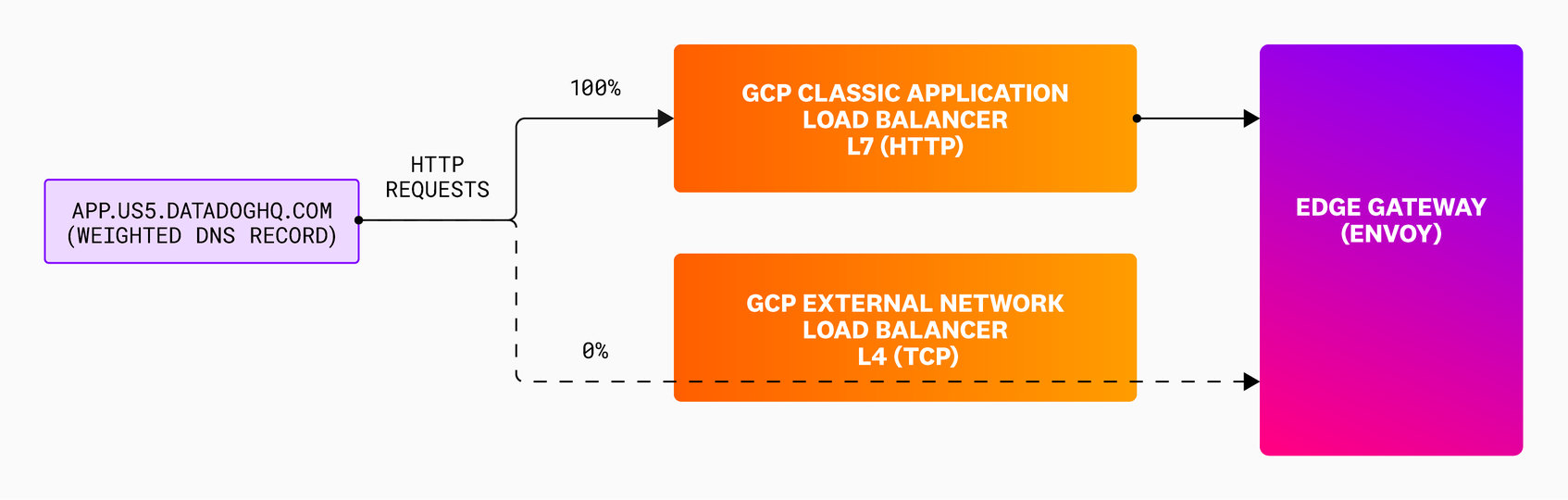
When a client (e.g., a browser) makes a request to the US5 endpoint, its DNS query will resolve to the IP of the existing L7 load balancer. After DNS resolution, the client sends an HTTP request to the L7 load balancer, which reconstructs it (e.g., adding more HTTP headers before sending it to a backend). Like other HTTP proxies, the L7 load balancer maintains a shared TCP connection pool towards its backend, which allows requests to be queued and dispatched on a single TCP connection. The L4 load balancer, on the other hand, only understands TCP (not HTTP) so it will pass the request through without modification. In this case, further HTTP processing is done directly on our Envoy proxies. For both L4 and L7 load balancers, Envoy will route the request to the correct backend, like one of our web applications, as a final step.
The incident unfolds: a sudden influx of unusual requests and responses
On April 19, 2024, at 18:45 UTC, we received a high-severity page due to an approximate 2 percent drop in the availability SLI for our website endpoint in US5. The issue was detected within five minutes of it starting, and an incident was immediately called to investigate. However, it lasted for approximately an hour before auto-recovering.
This kind of alert is uncommon, and is usually related to either a code regression or a transient network issue. We quickly ruled out a code regression since no deployments on our Edge infrastructure were running at the time.
As part of our monitoring, we continuously run Datadog Synthetic tests against all our public endpoints, hitting a simple service behind our Envoy proxies that always returns HTTP 200 responses. During the incident, we noticed that the tests were failing and receiving HTTP 400 (Bad Request) responses. This was the first alarm bell that something unusual was going on, because we know that our Synthetic tests send legitimate requests and our backend should not return HTTP responses like this as a general rule.
At this point, we started to realize that this event was more serious than a transient network issue, so we started digging into Envoy access logs, which uncovered some interesting clues. First, we saw a spike of “OPTIONS / HTTP/1.1” requests to the website within the same time window as the incident. However, all of these requests received HTTP 404 responses as expected, so they couldn’t directly explain the HTTP 400 responses for other legitimate requests.
By searching Envoy logs for the requests that received HTTP 400 responses, we confirmed that the errors were generated by Envoy itself due to a “Downstream Protocol Error.” This means that the request that Envoy received from the client (the cloud load balancer in this case) was malformed.
On April 21 (two days later), while our investigation was still ongoing, we were paged again for the same issue. However, this time the mysterious OPTIONS requests were simultaneously targeting different environments hosted in AWS, Azure, and GCP. But the key difference in this case was that we were only seeing HTTP 400 responses in US5. This made it clear that the issue was specific to our GCP setup.
To dig deeper into Envoy access logs, we used the Geo IP parsing feature in Datadog Logs. This revealed that all OPTIONS requests were originating from a specific range of 100+ IPs associated with the same cloud hosting provider. The origin IPs also changed on every episode of the attack. At this moment, we realized that we were dealing with a complex DoS attack that was impacting our user experience, and we had to move fast to mitigate it.
All hands on deck: a coordinated incident response
Up until this point, customer impact was limited, and none of our customers had reported errors. However, the attacker was escalating the attack by targeting more environments, so we decided to treat it as an “all hands on deck” situation. Several infrastructure and security teams became involved in the incident response, and we organized our efforts into the following workstreams:
- Escalate to the cloud hosting provider that owned the IPs where the attacks originated from, and provide them with the needed information to file an abuse report.
- Research the potential security vectors and impact of the attack, and then reproduce it based on the forensic data we gathered from the two previous occurrences.
- Prepare to gather more forensics the next time the attack happened and share our findings with GCP.
When the attack occurred again on April 23, our preparation enabled us to take packet captures on incoming traffic and dive deeper into Envoy trace logs. We discovered that Envoy received a request that looked like the following snippet:
OPTIONS / HTTP/1.1
Host: app.us5.datadoghq.com
Connection: Keep-Alive
some-gcp-headers: some-values
"some-payload"Envoy started parsing the OPTIONS verb until it reached the final header. At this step, Envoy found an empty newline, finished parsing the request, and sent it upstream for further processing. Because the upstream resource did not exist, Envoy eventually received a 404 response from its backend and passed it back to the client as expected.
One big clue in this scenario was that the OPTIONS request didn’t contain “Content-Length” or “Transfer-Encoding: chunked” headers, so Envoy assumed the request didn’t have a body in accordance with RFC 9112. This meant that Envoy’s buffer for this connection was still not fully processed, so Envoy kept the connection open to receive another request from the load balancer. This is valid behavior because, according to HTTP 1.1, all connections were persistent and a “Connection: keep-alive” header was present.
At this point in the process, the load balancer reused the same TCP connection to forward another request from a legitimate client to Envoy. This resulted in Envoy’s buffer appending the new legitimate request to the “some-payload” content from the previous OPTIONS request. Because of this new but malformed request, Envoy failed to parse the buffer contents, causing it to return an HTTP 400 error to the legitimate client.
We focused our reproduction efforts on sending similar requests (i.e., OPTIONS requests with a payload and no “Content-Length” headers) to our website. But in our tests, the load balancer rejected these requests and never forwarded them to Envoy. This result led us to believe that the attacker was sending something special in the requests, but we didn’t know what it was quite yet.
Cracking the puzzle: discovering the payload of the malicious requests
We reached a dead end with the information we had so far. Our last hope was to capture the requests sent by the attacker as they arrived at the load balancer. Since GCP engineers were a part of the investigation, we asked if they could take a packet capture from the load balancer itself. Unfortunately, this wasn’t possible, so we had to get creative in how we captured that traffic.
As mentioned earlier, we had the capability to spin up L4 load balancers and shift traffic to them using DNS weights. We decided to create one for our US5 website endpoint and shift 5 percent of the traffic to it before the next attack. This step enabled us to capture the unmodified attack requests since the L4 proxy doesn’t intercept the HTTP client requests.
When the attack happened again on April 24, we were finally able to see the original requests that the attacker crafted. They looked like the following snippet:
OPTIONS / HTTP/1.1
Host: app.us5.datadoghq.com
Connection: Keep-Alive
Transfer-Encoding: chunked
some-headers: some-values
ff
"some-payload"
0We were quickly able to reproduce the attack against one of our staging environments by sending OPTIONS requests with a chunked payload. We concluded that for these specific requests, the load balancer removed the chunk encoding without adding a “Content-Length” header. This tricked Envoy into thinking that the request had no body, which left the payload unprocessed in the connection buffer.
For every malicious request, we were able to break another random request that followed it in the same TCP connection. This test efficiently achieved DoS because it relied on seemingly normal HTTP requests with tiny payloads, without the need to establish a new connection. This particular technique is called HTTP smuggling.
Stopping the attack: mitigation steps to stop malicious traffic
Now that we figured out the issue, we began two mitigation streams in parallel. First, we confirmed that the percentage of traffic that we diverted to the L4 load balancer was not impacted by the issue introduced by the L7 Classic Application Load Balancer. We decided to gradually shift more traffic to the L4 load balancer to mitigate the issue on our side. Because this was a significant change, we didn’t want to increase the risk by rushing it.
At the same time, we worked with the GCP team to block the malicious traffic using Google Cloud Armor. We couldn’t initially create a rule that blocked all OPTIONS requests that have a body, so they provided us with custom request headers that made this possible. This new Cloud Armor rule effectively blocked all malicious traffic to the US5 website.
On April 26, GCP rolled out a permanent fix for the Classic Application Load Balancer vulnerability globally. We haven’t identified any additional instances of the attack since then, which confirms that the issue has been fully mitigated.
Lessons learned
There were several lessons learned from this attack, which affected multiple aspects of incident management.
Detection
We were able to detect the problem almost immediately using Datadog SLOs and monitors. This visibility helped us launch investigations quickly as well as quantify customer impact and the overall severity of the problem. When we began investigating, we had a sufficient number of logs in place to get a general picture of what was going on.
We also benefited from using Synthetic API testing to continually assess the operational health of services, which allowed us to proactively identify and address issues before they impacted end users.
Escalation
This was an unusually nuanced and hard-to-understand DoS attack that led us down several different investigation paths. This emphasizes the need to engage a wide array of teams (e.g., infrastructure, security, and product) to work on the problem together to explore different hypotheses. There is also a need for effective incident management processes and tooling to track incidents that span multiple days.
Remediation
Having established, effective runbooks is essential for fast identification and remediation in incidents. For example, one of the follow-ups to this incident was to augment our runbooks with more detailed instructions for gathering forensics so we can perform them faster in the future.
Prevention
Even though this issue was unique to GCP, similar vulnerabilities may happen in the future in other environments. To be ready for that, we have implemented critical rules in Datadog Cloud Security Management (CSM), such as ELB scanner detection and AWS ELB ensuring connection draining.
We are also now able to detect similar malicious requests in the future by using Datadog Application Security Management (ASM) in all Datadog regions, and stop them using our In-App WAF.
Investigate and respond to attacks with confidence
The mystery of what happened between April 19–25 is now solved: a meticulously crafted DoS attack targeted multiple Datadog regions by taking advantage of a load balancer vulnerability. Though DoS attacks are not new, they have evolved in the way they target systems. In complex environments like ours, they can be difficult to detect and investigate. Responding to this incident required cross-team and cross-vendor collaboration, as well as some creativity in how to find the requests that the attacker crafted. In the end, the ability to inspect malicious requests passing through impacted load balancers enabled us to replicate and mitigate the attack.
You can learn more about how Datadog Security can help you mitigate attacks by checking out our documentation. You can also sign up for a free 14-day trial if you don’t already have a Datadog account.
