

Deploying microservice-based applications with Kubernetes can be a complex process—more services translate to more Kubernetes resources, pipelines, and service dependencies. Without the proper tools and practices in place, it can be difficult to dynamically manage API endpoints and databases that your services rely on during deployments, understand how your Kubernetes resources and configurations differ across environments, and ensure that the live state of your clusters aligns with your desired state. In response to these challenges, many organizations have adopted GitOps, a declarative approach to continuous delivery (CD). In GitOps, declarative refers to defining the desired state of your infrastructure and applications within a Git repository; this state is then monitored by CD tools such as Argo CD and Flux, which apply real-time changes to your clusters to ensure that they’re up to date.
GitOps isn’t a product or platform that you use on top of existing deployment workflows; it’s an operational framework composed of best practices that brings familiar developer workflows to infrastructure management. By storing configuration files and other deployment artifacts in a central Git repository, teams can apply version control and peer review to all infrastructure changes—including physical infrastructure, application source code, and the mapping of application version to infrastructure—and gain visibility into the current state of their clusters via a single source of truth.
In this blog post, we’ll discuss:
- The evolution of infrastructure deployment using Kubernetes
- How GitOps addresses pain points in the development lifecycle
- How GitOps works in practice
- The various components that drive a GitOps workflow
- How GitOps helps promote releases across environments
Kubernetes and the evolution of infrastructure automation
When engineers began deploying infrastructure to the cloud, they quickly realized that cloud APIs could boost productivity and reliability compared to traditional deployment workflows. Using shell scripts, they could launch virtual machines (VMs) with pre-installed software and connect the VMs to load balancers that passed traffic into their environments. In addition, new declarative tools such as AWS CloudFormation and Terraform enabled them to deploy using infrastructure as code (IaC).
As opposed to procedural deployments that execute a series of step-by-step commands, IaC tools flexibly make changes to infrastructure resources to achieve the desired end state expressed in configuration files. Giving the tool control over the execution specifics enables it to run tasks in parallel and intelligently resolve errors and resource failures commonly encountered when handling deployment shell scripts.
As organizations began to migrate their infrastructure to container platforms, Kubernetes emerged as the natural extension of these ideas for container deployments. Using Kubernetes, engineers can manage application resources and deployments by declaratively specifying the objects they want using YAML files. Various Kubernetes controllers that are in charge of different object classes (deployments, services, etc.) are then responsible for creating these objects and deploying them within a cluster. The only action on the engineer’s part is to declare these changes within the configuration file—the rest is left up to the controllers. For instance, if an engineer increases a deployment’s number of set replicas, a controller is notified of this change and automatically creates a new pod—the scheduler then considers resource requests and other constraints to assign the pod to an available node for it to start running.
Kubernetes pain points and the role of GitOps
As teams shift to high-velocity development cycles that focus on shipping smaller deliverables more frequently, service and application components are constantly being updated, and these updates need to be reflected in Kubernetes. Without a GitOps workflow, this process needs to be manually executed—typically by running kubectl apply at the end of each build job or using a package manager such as Helm to upgrade a release. This manual deployment process introduces a few pain points:
- Procedural operations such as
kubectl applyneed to be applied to the cluster each time a component changes, and direct changes to your cluster (such as manual pod scaling) that aren’t reflected in your configuration files can create configuration drift—when the actual state of your clusters differ from what is defined in your manifests. This can lead to inconsistencies across environments that break deployments and may cause failed recovery attempts when recreating a cluster. Since Kubernetes provides no built-in versioning, fixing these issues requires you to dig through build logs and piece together a history of when objects were updated and when these updates ran. - In most Kubernetes deployments, promoting releases across environments (e.g., from development to staging to production) requires you to run additional build jobs on the tail end of your CI/CD pipeline that are responsible for tagging and deploying images and other artifacts. This slows down pipelines and feedback cycles.
Kubernetes monitoring tools and logs help you visualize and understand the live state of your clusters. However, without any tooling to check and reconcile this live state against your desired state, you can never be fully sure that your cluster is deployed correctly.
GitOps aims to address these issues by expressing the desired state of your infrastructure declaratively and storing it outside of the Kubernetes cluster, in a way that enforces immutability and provides version control. Additionally, any changes made to the desired state should be automatically applied, and the system should self-correct if it detects that the actual state of your environment drifts from the desired state.
In a correctly implemented GitOps workflow, the declaratively expressed desired state is the central piece that addresses the pain points of Kubernetes-based development life cycles. CD tools monitor and update your clusters to reflect this desired state, while version control via Git provides a transparent history of the changes made to the cluster over time and enables you to confidently roll back to previous infrastructure setups if needed. And by referencing your images within each environment’s configuration files, you can promote changes across environments without rebuilding the image in multiple environments.
So how does GitOps work in practice?
Your organization most likely already uses Git repositories to store and version-control your application code. A GitOps workflow extends this practice to infrastructure—configuration files such as Kubernetes manifests are stored in a separate GitOps repository that is updated whenever your application code changes. By defining infrastructure for your cluster and for each service, Git operates as the single source of truth for managing both application code and infrastructure.
At a high level, a GitOps workflow operates as follows:
- A developer that makes changes to application code pushes those changes to its Git repository.
- The changes are then built in CI, and the updated image version is pushed to the container registry.
- In a typical CI pipeline, a CI job would run
kubectl applyafter the updated image is pushed to the container registry to update the live state of your cluster. In a GitOps workflow, instead of mutating your cluster via a build job, a CI job automatically commits changes to the GitOps repo, updating its YAML files to reflect the latest changes made in your application code (e.g., update our service version from 1.0 to 1.1). - At this point, we’ve only updated our Kubernetes manifests, and our changes still have yet to be applied to our clusters. To apply these changes, we enlist the aid of a GitOps operator such as Argo CD or Flux. Once an operator has been installed in a cluster, it will continuously monitor the cluster’s live state by querying the Kubernetes API and compare it against the desired state declared in our GitOps repository. If it detects any deviations between the two states, it will automatically apply changes to the cluster via the API server to ensure that the cluster matches the desired state.
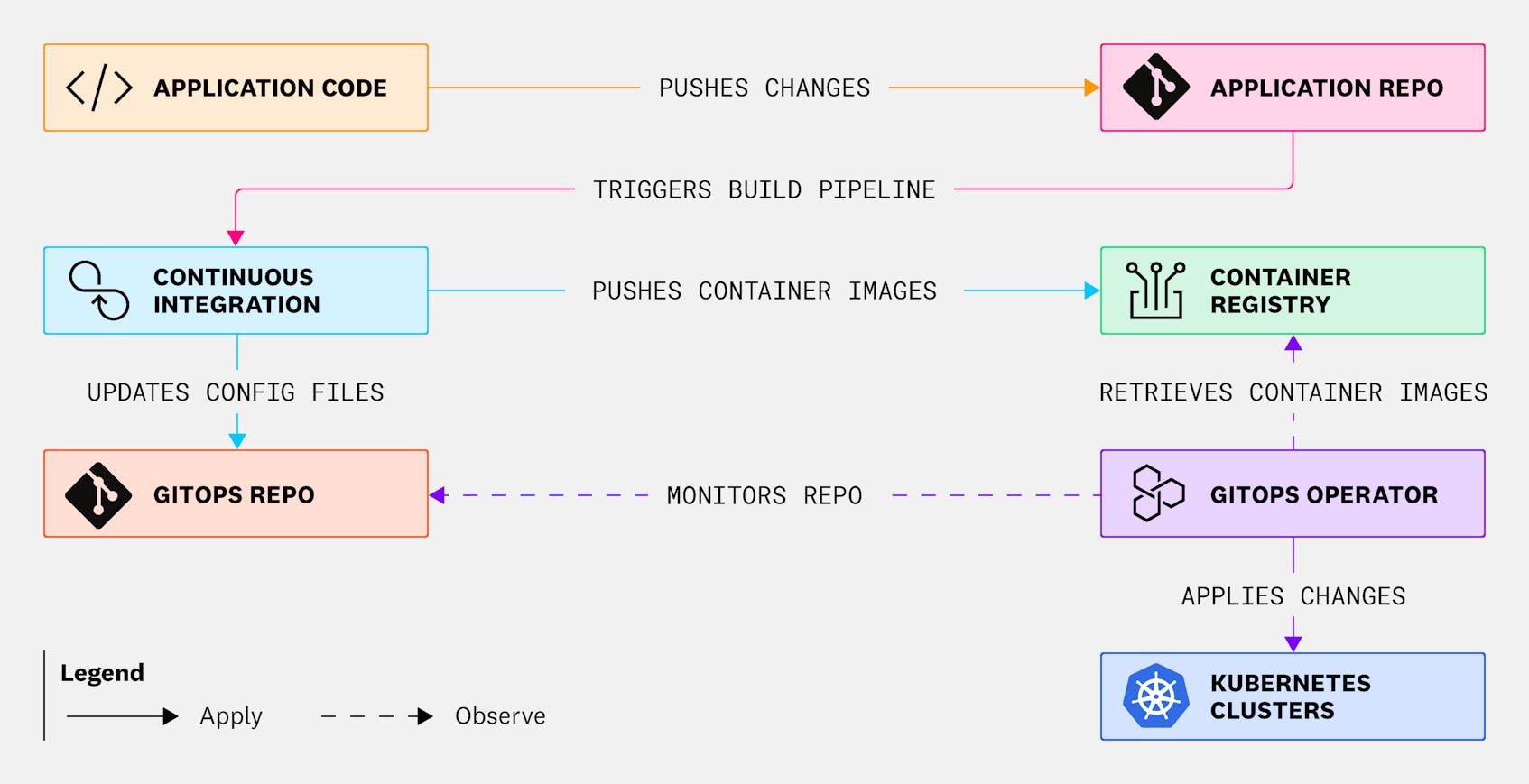
In the example above, after the the build pipeline pushes an update to a new version of a container image referenced in our GitOps repository, the operator will detect this change and reconcile our cluster by redeploying our application using the reference to the new image version in stored in our image registry. GitOps operators will also emit events—for instance, via webhooks—so that the actions they are taking on your cluster can be easily monitored with tools such as Datadog Continuous Delivery Visibility to provide insights into the performance and results of your deployments.
The components of a GitOps workflow
In this section, we’ll discuss in more detail each component within the GitOps workflow, as well as additional tools that you can implement to enhance your build and deployment pipeline. We’ll be using a sample repository, which you can clone for a complete, end-to-end demo of a Golang/Java stack that can be deployed to Kubernetes.
You need applications and services
Maintaining a performant service using Git goes beyond functioning application code. While GitOps introduces a declarative expression to the state of your infrastructure, it builds on an existing continuous integration and delivery system that has automated checks, a build and release pipeline, and static analysis tools to identify code vulnerabilities prior to runtime.
This typically includes CI scripts for your service that perform checks on each pull request, autorelease code that builds your service and releases the image to your container registry, and a container registry that stores the images alongside other container artifacts (such as image signatures for verification). Adding a docker-compose.yml in each service folder also enables you to quickly spin up and destroy test environments, as well as validate your changes locally before committing them to your repo. Using tools such as Datadog Code Analysis, you can scan your repository for vulnerabilities within open source libraries imported through package managers such as npm and quickly apply static analysis to your repository with our out-of-the-box rulesets.
You need a Kubernetes cluster instrumented with a GitOps operator
Whether you choose to self-host your Kubernetes clusters or deploy infrastructure with cloud-provider options such as Amazon Elastic Kubernetes Services, Azure Kubernetes Services, or Google Kubernetes Engine, you’ll need to install a GitOps operator within your clusters. Operators are third-party extensions to Kubernetes that are allowed to manage applications and other components within your cluster—in our case, monitoring the cluster and making the necessary changes to ensure that its live state reflects the desired state declared in our GitOps repository. You may already be familiar with the Datadog Operator, which is used to deploy and configure the Datadog Agent, Cluster Agent, and Cluster Checks Runners in your Kubernetes environment.
While implementation details may vary depending on the operator of your choice, the typical installation process installs the operator and its resources within a Kubernetes namespace and creates a service account that grants it access over the target cluster. You’ll then need to create an operator application that is configured with the paths to your GitOps repository, as well as the Kubernetes namespace on the cluster you want to monitor. You can also run your GitOps operator in a remote cluster separate from the clusters it deploys applications to. This enables you to use a single control plane to monitor your services across different regions and environments. After this link has been created, the operator will begin to reconcile the state of the cluster with its environment, similar to any other Kubernetes resource controllers. To see an example, we’ve added Argo CD manifests to bootstrap our sample app—you can check it out here.
You need a GitOps repository
Your configuration files should be stored in a dedicated GitOps repository as a best practice for a few reasons. Firstly, creating a separate GitOps repo decouples the management of infrastructure and deployments from application code. It also enables developer teams and operation teams to have strictly defined areas of product ownership and a clear method of implementing access controls within these areas. (Note: The sample stack provided above does not follow this best practice and was made to be self-contained for demonstration purposes.)
In the following section, we’ll discuss a few different approaches to structuring your GitOps repository depending on your organization’s scale and priorities and how these approaches can help you manage releases across environments.
How GitOps helps promote releases across environments
To decide which approach is correct for your organization, you should consider how highly you prioritize independent team workflows, environment security, and centralized management. Many organizations that rely on Git may use different branches to separate their environments. This is known as the Gitflow model, and it was a popular workflow adopted by teams in the 2010s during the early days of GitOps. By separating environments by branch, you could simply merge code changes from your dev branch into your staging branch or from staging into production, making promotions a quick and easy process.
However, as GitOps practices matured, the shortcomings of this workflow became more apparent. These included:
- Configuration drift: Changes to downstream production environments may not be backported to staging and dev, and environment-specific configurations that are hardcoded into each branch can create inconsistencies.
- Lack of role-based access controls (RBAC): Most Git platforms do not natively support branch-level access controls, and it’s much easier to implement RBAC at the repository level where users are restricted to specific actions based on their roles.
- Merge conflicts: These can occur when different teams push changes to different environments within the same time frame.
- A large number of branches required: Teams need many branches to account for different data centers and cluster variations.
In a folder-per-environment structure, you can separate these files into configurations that remain constant across different environments (which are stored in the base directory shown below) and those that differ between environments (stored in the overlays directory shown below). This centralized architecture makes it easy to search for and compare configurations (using diff) across environments. It also simplifies the configuration of your GitOps operator, since it only needs to monitor a single repository using paths to each environment folder.
However, the folder-per-environment approach also suffers from access control limitations—e.g., limiting developer write access to the production folder—and it can result in a bloated repository if you scale to additional regions each with their own environments.
For organizations that operate under strict compliance and regulation requirements, a repo-per-environment structure enables you to configure more granular access control to your production environment and reduce the risk that it accidentally gets modified. This also provides scaling benefits—repositories remain lightweight and can trigger independent pipelines, while enabling you to implement more robust testing in production. The obvious downside to this is that you’ll need to manage several repositories in tandem, which can require more management overhead and advanced tooling to synchronize commits that span multiple environments.
Triggering the release promotion can be conducted in a few different ways. The simplest method is to trigger a manual promotion within your CI. This will run a CI action that promotes changes from one environment to another—e.g., by copying the relevant changes from the dev environment directory to the prod environment directory. However, for a more fluid, automated workflow, consider using policy-based promotions, which can automatically trigger once your set criteria have been met (e.g., all tests and checks pass, peer approval required, CI images have been signed, etc).
Tools such as Kargo work with your GitOps operator and enable you to define promotion criteria in configuration files that are stored in your Git repository. This adds an additional declarative, continuous promotion layer that helps you automate the GitOps lifecycle across multiple environments. Using Kargo, you can visualize different application instances across different environments and map promotion workflows between these instances. Once these workflows trigger based on your defined promotion policies, Kargo will automatically update your GitOps repository to ensure that each environment’s resources are updated according to the promotion. If your organization’s CI scripts that manage promotions are error-prone or you’re looking to centralize management and visibility into promotion processes, we’d suggest exploring Kargo and other continuous promotion tools.
Introduce GitOps best practices to your Kubernetes environment
GitOps introduces declarative infrastructure management into your Kubernetes environment, giving teams tools to quickly manage and make operational changes to infrastructure that can be peer-reviewed and version-controlled. You can leverage these practices with Datadog CI Pipeline Visibility to gain deeper insights into your CI/CD workflow or monitor tools such as Argo CD, Flux, and GitHub Actions with metrics, dashboards, and more that come with our integrations. To track your deployments using Datadog, request access to Continuous Delivery Visibility, now available in Preview. If you’d like to see GitOps in action, try cloning our sample stack and get started with our demo service, or make some minor modifications to integrate it into your test environment.
If you don’t already have a Datadog account, sign up for a free 14-day trial today.
