

As a Software Engineering Intern on the open source team at Datadog, I contribute to various open source projects using Datadog tools to track down bugs and performance related bottlenecks.
One of the tools I use is Application Performance Monitoring (APM). APM allows you to instrument your code with a client tracing library, letting you view the breakdown of method performance across your application. It’s effective at finding performance bottlenecks, and for comparing the performance of mutually exclusive implementations when making a design decision.
Homebrew
The first open source project I contributed to at Datadog was Homebrew: a popular package management system for macOS. Being a macOS user for many years, I’ve used Homebrew on numerous occasions; I wanted to give back to the project which saved me countless hours of installation and configuration headaches.
Homebrew is used extensively by the engineering teams at Datadog, as it’s part of the standard developer toolkit. Because of this, improving the performance of Homebrew saves engineers time across the entire organization.
brew linkage is a development-specific Homebrew command used to check the library links of an installed formula (Homebrew’s term for a package).
There was an open GitHub issue with a help-wanted label seeking to make brew linkage faster. A performant brew linkage command could be run automatically to detect when a brew reinstall is needed because the user is using an optional dependency.
From the GitHub issue, the requirements for the solution were:
Ideally on an SSD and modernish hardware it should be able to scan ~50 packages (with some large ones like
boost) in under 5 seconds.
Investigation of performance bottleneck
I instrumented Homebrew’s code using Datadog’s ddtrace gem for Ruby.
Gem usage
The gem allows users to track the performance of blocks of code they trace:
require "ddtrace"
def some_function
# The time spent to complete this 'block' is tracked by the APM
Datadog.tracer.trace("some_function", service: "my_app") do
sleep 2
Datadog.tracer.trace("some_expensive_operation") { sleep 3 }
sleep 1
end
end
From here, users may navigate to the APM user interface to view traces in a flame graph:

Usage in Homebrew
To pinpoint the bottleneck, I instrumented Homebrew from the ‘root’ point of execution (in Library/Homebrew/dev-cmd/linkage.rb) to account for the command’s total execution time and all the subsequent methods called by the linkage function.
Analyzing the trace data in a flame graph, I was able to pinpoint the source of the performance issues to the check_dylibs function in the LinkageChecker class.

Flame graph showcasing the breakdown of time spent for methods instrumented during execution.
Optimization solutions
I investigated a solution utilizing multi-threading to speed up the processing of the LinkageChecker::check_dylibs function. I used Ruby’s Thread primitives to see if concurrency would get the desired performance. However, the limitations of the GIL made this solution inviable and did not meet the required performance specification.
I looked into viable alternatives to improve performance and decided to implement a caching mechanism using SQLite3: an on-disk light database used for persistent storage.
Initial solution
SQLite3 caching implementation
The most expensive operation for the brew linkage command was the processing required in the LinkageChecker::check_dylibs function. The function appends path locations to arrays corresponding to the type of library or dependency (i.e., system_dylibs, broken_dylibs, undeclared_deps, etc.).
I modeled a single-table schema for caching relevant linkage information required by the LinkageChecker. The data fetched could be post-processed to meet one of the two formats expected by the printer function. The schema was defined as follows:
CREATE TABLE IF NOT EXISTS linkage (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
path TEXT NOT NULL,
type TEXT NOT NULL CHECK (type IN (
'system_dylibs', 'variable_dylibs', 'broken_dylibs', 'undeclared_deps',
'unnecessary_deps', 'brewed_dylibs', 'reverse_links')),
label TEXT CHECK (label IS NULL OR (type IN ('brewed_dylibs', 'reverse_links'))),
UNIQUE(name, path, type, label) ON CONFLICT IGNORE
);
Internally, the application could insert, mutate or fetch data from the cache using a SQL-syntax:
db = SQLite3::Database.new "#{HOMEBREW_CACHE}/linkage.db"
# Storing path data in the cache for a particular key and linkage type
db.execute(
<<~SQL
INSERT INTO linkage (name, path, type)
VALUES ('key', 'path_name', 'linkage_type');
SQL
)
# Fetching path data from the cache for a particular key and linkage type
db.execute(
<<~SQL
SELECT path FROM linkage
WHERE type = 'linkage_type'
AND name = 'key';
SQL
).flatten
Performance enhancements
I noticed significant performance gains with the caching in-place. Below are two flame graphs showcasing the breakdown of execution time for the command with 106 packages (including larger packages such as boost). The command ran in under 5 seconds with the caching mechanism utilized, as requested in the requirements.
Flame graphs
Without the optimization
Without the caching, the command took 11.5 seconds to complete processing 106 packages. The library boost took 1.01 seconds to complete checking the dynamic libraries.

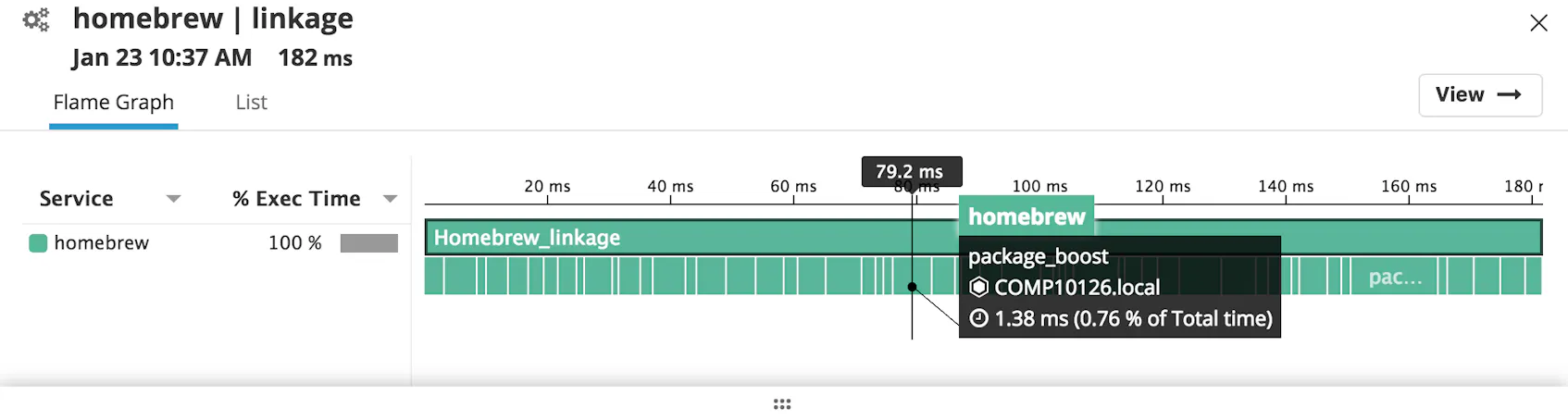
With the optimization
With the caching, the command took 182 milliseconds to complete processing 106 packages. The library boost took 1.38 milliseconds to complete checking the dynamic libraries.
Second solution
pstore caching implementation
After the initial implementation, I submitted a Pull Request to Homebrew, asking for a code review from the maintainers. It was recommended I try a different implementation using Ruby’s pstore, a file-based persistence mechanism based on Ruby’s Hash. The principle advantage of using pstore over SQLite3 is that it doesn’t require a third-party gem dependency.
I created a branch off of my SQLite3 implementation to compare the performance of using pstore over SQLite3 as the caching mechanism. The abstractions from the first implementation made it easy to swap out the SQLite3-coupled database code for the new pstore implementation.
My goal was to keep the public interface of the LinkageStore class as similar as possible for the pstore implementation for comparison reasons. However, I did not need to define a schema for the cache since pstore stores Ruby objects to the data store file with Marshal: a library which converts Ruby objects into a byte stream.
Below is an example of fetching and mutating data for the pstore implementation:
db = PStore.new "#{HOMEBREW_CACHE}/linkage.pstore"
# Storing path data in the cache for a particular key and linkage type
db.transaction do
db["key"] = { "linkage_type" => "path_name" }
end
# Fetching path data from the cache for a particular key and linkage type
db.transaction do
db["key"]["linkage_type"]
end
Comparison of SQLite3 and pstore
The pstore implementation has nicer syntax for storing and fetching data using Ruby, since pstore transactions have a similar syntax to Ruby’s native Hash get/set syntax, whereas the SQLite3 implementation uses a SQL syntax.
However, the biggest downside to the pstore implementation is the performance for fetching and persisting data. Using pstore caching is slower than the original implementation without any caching. Persisting the Marshaled byte-stream data on-disk and fetching the data then loading it into a Ruby object are expensive operations.
With caching, the command took 42.2 seconds to complete for just two packages! One fetch_path_values! method call (illustrated in the graph below) took 3.51 seconds total. For comparison, this took more time fetching information from two packages than the SQLite3 implementation took fetching information from 106 packages.

I recommended to the maintainers we use SQLite3 over pstore for the caching mechanism, as I believed the tradeoff of installing another gem was worth the performance benefits of using SQLite3 for caching.
Third solution
DBM caching implementation
After investigating the performance differences of the pstore and SQLite3 implementations, it was recommended by the maintainers to look into an implementation using a Berkeley DB. A Berkeley DB is another on-disk persistent storage database which is commonly used for caching. Ruby provides a module for interfacing with a Berkeley DB called DBM, which like pstore, doesn’t require a third-party gem dependency.
Inserting and mutating data from the cache was similar to the pstore implementation, but with some extra parsing needed for fetching, since all Ruby hashes and arrays are persisted as strings:
db = DBM.open("#{HOMEBREW_CACHE}/#{name}", 0666, DBM::WRCREAT)
# Storing path data in the cache for a particular key and linkage type
db["key"] = { "linkage_type" => "path_name" }
# Fetching path data from the cache for a particular key and linkage type
JSON.parse(db["key"].gsub("=>", ":"))["linkage_type"]
Comparison of SQLite3 and DBM
origin/master
Without the optimization
The baseline without caching (i.e., the time it takes for brew linkage to complete on origin/master) took 8.04 seconds to complete for 99 packages. The library boost took 704 milliseconds to complete checking the dynamic libraries and printing the output.

SQLite3
Without the optimization
Without the caching, the command took 10.3 seconds to complete for 99 packages. The library boost took 777 milliseconds to complete checking the dynamic libraries and printing the output.

With the optimization
With the caching, the command took 180 milliseconds to complete for 99 packages. The library boost took 1.77 milliseconds to complete checking the dynamic libraries and printing the output.

DBM
Without the optimization
Without the caching, the command took 8.14 seconds to complete for 99 packages. The library boost took 686 milliseconds to finish checking the dynamic libraries and printing the output.

With the optimization
With the caching, the command took 208 milliseconds to complete for 99 packages. The library boost took 2.15 milliseconds to complete checking the dynamic libraries and printing the output.

Summary
I’ve summarized the performance comparison between the SQLite3 implementation and the DBM implementation below:
| Implementation | No Optimization | Cache Optimization |
|---|---|---|
origin/master | 8.04 seconds | N/A |
SQLite3 | 10.3 seconds | 180 milliseconds |
DBM | 8.14 seconds | 208 milliseconds |
Observations
- It took longer to build the cache (i.e., the No Optimization column) for both
SQLite3andDBMimplementations than it currently takes onorigin/master - The
DBMimplementation built the cache faster than theSQLite3implementation - It’s much faster to run the
brew linkagecommand when the values are cached (i.e., the Cache Optimization column forDBMandSQLite3) - The
SQLite3implementation is faster at accessing values from the cache than theDBMimplementation (but not by much) - The implementation met the requirements specification, by processing > 50 packages in under 5 seconds
Recommendations
I recommended proceeding with the DBM implementation due to the following:
- The
DBMsolution doesn’t require a vendored gem like theSQLite3implementation - The
SQLite3gem requires building native extensions from C withrake/extensioncompiler - Setting the cache is slightly faster than the
SQLite3implementation, and while theSQLite3solution is faster at fetching data from the cache, it’s not faster by much - Cleaner to read the code and understand the cache structure/schema
- Fetching and mutating data uses Ruby’s
Hashget/set conventions over a SQL syntax
Conclusion
When most people think of Datadog, they probably think of cloud infrastructure monitoring, metrics, or alerting. Application Performance Monitoring opens up a variety of different use-cases including performance benchmarking, bug squashing, and finding bottlenecks in your applications.
Making data-driven decisions is an essential part of being an engineer. The performance data collected from the APM helped to guide my engineering judgment when implementing features and making design decisions.
APM provides a means to show both technical and non-technical stakeholders how an application performs. The graphs in the user interface make it easy to see which parts of your application take the most time, allowing for an engineer to optimize and compare the performance of their changes.
Update: Andrew returned to the University of Waterloo following his internship, but continued to work on caching in Homebrew. We’re thrilled to announce that his Pull Request was merged and should be included in the upcoming release of Homebrew (1.6.5).
Datadog 💜 open source
Datadog is a proud user of and contributor to many open source projects. As part of our continued commitment to open source, we’re always looking for ways we can give back to the community.
If you have an open source project or initiative that you feel would benefit from application performance metrics discussed in this article, we’d like to help. You may apply here for free access to Datadog.
