

Here’s an error that no developer wants to see in their Postgres server logs:
server process was terminated by signal 11: Segmentation fault. When our team was paged about one of our Postgres clusters crashing with this error, we were quite surprised, and quickly activated our incident response. The failing cluster was a new workload freshly deployed on our reliable internal Postgres-on-Kubernetes platform. What could possibly be causing this new and scary failure mode? Why was Postgres crashing with segmentation faults?
The problem was manifesting on multiple EC2 nodes, so we quickly ruled out hardware issues. We had core dumps from the crashes that appeared corrupted but provided little hint as to why. Looking more broadly, we correlated our query logs and pinpointed a query pattern that was occurring right before each crash. Following this lead, we jumped into a psql terminal to test the suspicious query and indeed found that running it triggered a segfault. We were taken aback to discover that we had a Postgres cluster—up to date with the latest minor version—that was crashing after running an innocuous-looking “query of death”!
Ultimately, by successfully isolating and debugging the crashes down to the assembly level, we were able to identify an issue in Postgres JIT compilation, and more specifically a bug in LLVM for Arm64 architectures. This post describes our investigation into the root cause of these crashes, which took us on a deep dive into JIT compilation and led us to an upstream fix resolution.
Isolating the issue
We started our investigation by looking at the cluster as a whole, where we confirmed that only a few queries were crashing Postgres. On a promising note, the ones that failed were triggering the segmentation fault in a consistent way. We started by examining one of these queries, and simplified it down to the following trivial reproducer:
postgres=# SELECT repo_id FROM repository;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to server was lostInspecting our collection of core dumps more closely, we were able to find some with salvageable frames:
#0 0x0000fff7353141cc in ?? ()
#1 0x0000fff7a1ad3754 in ?? ()
#2 0x0000fff7a2016720 in ExecRunCompiledExpr (state=0xaaaafffe4c88, econtext=0xaaaafffe46d8, isNull=0xaaaafffe5928) at ./build/../src/backend/jit/llvm/llvmjit_expr.c:2483
#3 0x0000fff7a2016720 in ExecRunCompiledExpr (state=0xaaaafffe5928, econtext=0xaaaafffe47e8, isNull=0xfffffcef70f7) at ./build/../src/backend/jit/llvm/llvmjit_expr.c:2483
#4 0x0000aaaadaad5bd0 in ?? () at executor/./build/../src/backend/executor/nodeSort.c:430A typical Postgres backtrace should have at least 20 frames, with the main entry point at the bottom. This backtrace only had four frames, with the last frame being ??, suggesting that the stack was corrupted. We weren’t sure if we could trust the frames, but they seemed to indicate an issue within Just-in-Time (JIT) execution.
A crash course on JIT in Postgres
Postgres needs to handle arbitrary SQL expressions like WHERE a=1 or 1+1, which are executed by a general-purpose interpreter that can handle all types of operations. When processing millions of rows, the overhead that results from the interpreter repeatedly evaluating expressions can add significant CPU load.
JIT can mitigate this overhead by compiling a native version of these expressions during the query’s execution (hence the moniker “Just-in-Time”). For example, using JIT, the 1+1 expression can be compiled into a machine code function that directly returns 2. Another key JIT optimization is tuple deforming, which natively transforms on-disk tuples (containing all of the columns) into their in-memory representation. Postgres uses the popular LLVM Project to handle all JIT compilation.
While JIT offers an execution speed boost over the query interpreter, there’s no free lunch—it takes additional processing cycles to compile code on the critical path of query execution. Additionally, Postgres doesn’t support reusing JIT-compiled functions, so they must be re-compiled for every query. Thus, Postgres relies on heuristics and tunable cost thresholds to invoke JIT only for expensive queries where the benefits are more likely to offset the compilation overhead.
Our query of death was expensive: it scanned a table ”repository” that had 64 partitions and more than 1.6 million rows, as seen in the query plan:
QUERY PLAN
------------------------------------------------------------------------
Append (cost=0.00..111412.66 rows=1682444 width=29)
-> Seq Scan on repository0 (cost=0.00..1615.99 rows=26399 width=29)
-> Seq Scan on repository1 (cost=0.00..1610.13 rows=26313 width=29)
...
-> Seq Scan on repository62 (cost=0.00..1597.72 rows=26072 width=29)
-> Seq Scan on repository63 (cost=0.00..1598.26 rows=26126 width=29)
JIT:
Functions: 128
Options: Inlining false, Optimization false, Expressions true, Deforming trueThe query plan indicated that JIT was used to compile 128 functions. Given all of the focus on JIT, as an investigative step, we tried running the query with JIT disabled:
postgres=# SET jit = off;
SET
postgres=# SELECT repo_id FROM repository;
repo_id
-------------------------------------
github.com/DataDog/datadog-agent
github.com/DataDog/integrations-core
github.com/DataDog/dd-trace-go
...With JIT disabled, the query ran without triggering a segfault. As an immediate mitigation, we disabled JIT for the entire cluster, which stopped the crashes completely and without any noticeable impact on query latencies. It was time to relax and grab a cup of coffee.
So far, the only information we had was that the crash was happening during JIT execution. We still needed to find the root cause to prevent the issue from recurring in other production clusters with different trigger conditions. Because the impacted cluster was running a release version of Postgres, it didn’t provide much debugging capacity or flexibility. To further debug the issue, we needed to reproduce it in a dedicated test environment.
Our initial attempts at reproducing the crash by simply copying the data to a local Postgres instance (using pg_dump or pg_basebackup) were unsuccessful. Simply replicating the data wasn’t enough, so we looked into replicating the exact characteristics of the original cluster: memory, instance type, CPU, architecture, and so on.
One of the differences turned out to be very important: the production cluster was running on Arm64 cloud instances (whereas our initial test environment was running on AMD64). By switching to Arm64 and trying again, we were able to successfully reproduce the issue!
Testing on a Postgres debug build
Now that we could reproduce the crash, we wanted to investigate further using a debug build. Since the crash was related to Postgres’s JIT features, we needed to ensure that we compiled Postgres with LLVM support:
$ git clone --single-branch --branch REL_14_STABLE https://github.com/postgres/postgres.git
$ mkdir postgres/build; cd postgres/build
$ CFLAGS="-O0" ../configure --enable-cassert --enable-debug --prefix /var/lib/postgresql/.local --with-llvm
$ make install -j9We also enabled jit_debugging_support in our postgresql.conf to register generated JIT functions with GDB. Once our debug cluster was up, we discovered that running the query of death resulted in a different set of failure symptoms: the database didn’t segfault anymore, but the process appeared to be stuck using 100 percent CPU, neither crashing nor returning anything. This was confusing.
To figure out what the process was doing, we needed to capture the process’s backtrace. The first step was to identify the correct process to attach to. When a client like psql opens a connection, Postgres forks a new process—called a backend process—that is dedicated to serve the connection. The backend process will show a command with the following format: \$username \$database \$source \$state. We checked the list of Postgres processes to find the process we were interested in:
$ pgrep postgres -a
20111 /var/lib/postgresql/.local/bin/postgres -D /var/lib/postgresql/db_data
20112 postgres: logger
20195 postgres: checkpointer
20196 postgres: background writer
20197 postgres: walwriter
20198 postgres: autovacuum launcher
20206 postgres: postgres postgres [local] SELECTProcesses like logger, checkpointer, and walwriter are system processes, and thus not relevant to the query execution. Our list of processes showed one client, postgres postgres [local] SELECT, connected with the postgres user on the postgres database using a Unix socket and currently handling a SELECT query. We attached GDB using the process with the identified PID:
$ gdb -p 20206Once GDB was attached, we got the following backtrace:
(gdb) bt
#0 0x0000ec53660aa14c in deform_0_1 ()
#1 0x0000ec53660aa064 in evalexpr_0_0 ()
#2 0x0000ab8f9b322948 in ExecEvalExprSwitchContext (isNull=0xfffff47c3c87, econtext=0xab8fd0f13878, state=0xab8fd0f13c50) at executor/./build/../src/include/executor/executor.h:342
#3 ExecProject (projInfo=0xab8fd0f13c48) at executor/./build/../src/include/executor/executor.h:376
...Indeed, this was JIT code and, with the jit_debugging_support parameter enabled, we had more useful frame names to help us understand what the JIT code was: evalexpr_0_0 and deform_0_1.
Spotting an infinite loop in Arm64 assembly
Even though the symptoms changed, we felt that the stuck process was most likely a different manifestation of the same issue and that analyzing it would help us understand the root cause.
Since we were debugging assembly code, we couldn’t use the normal GDB commands and views. Using layout split and layout regs in GDB showed a split view of the assembly dump, along with the state of the registers. Additionally, to advance within the assembly code, nexti and stepi were used instead of the usual next/step commands.
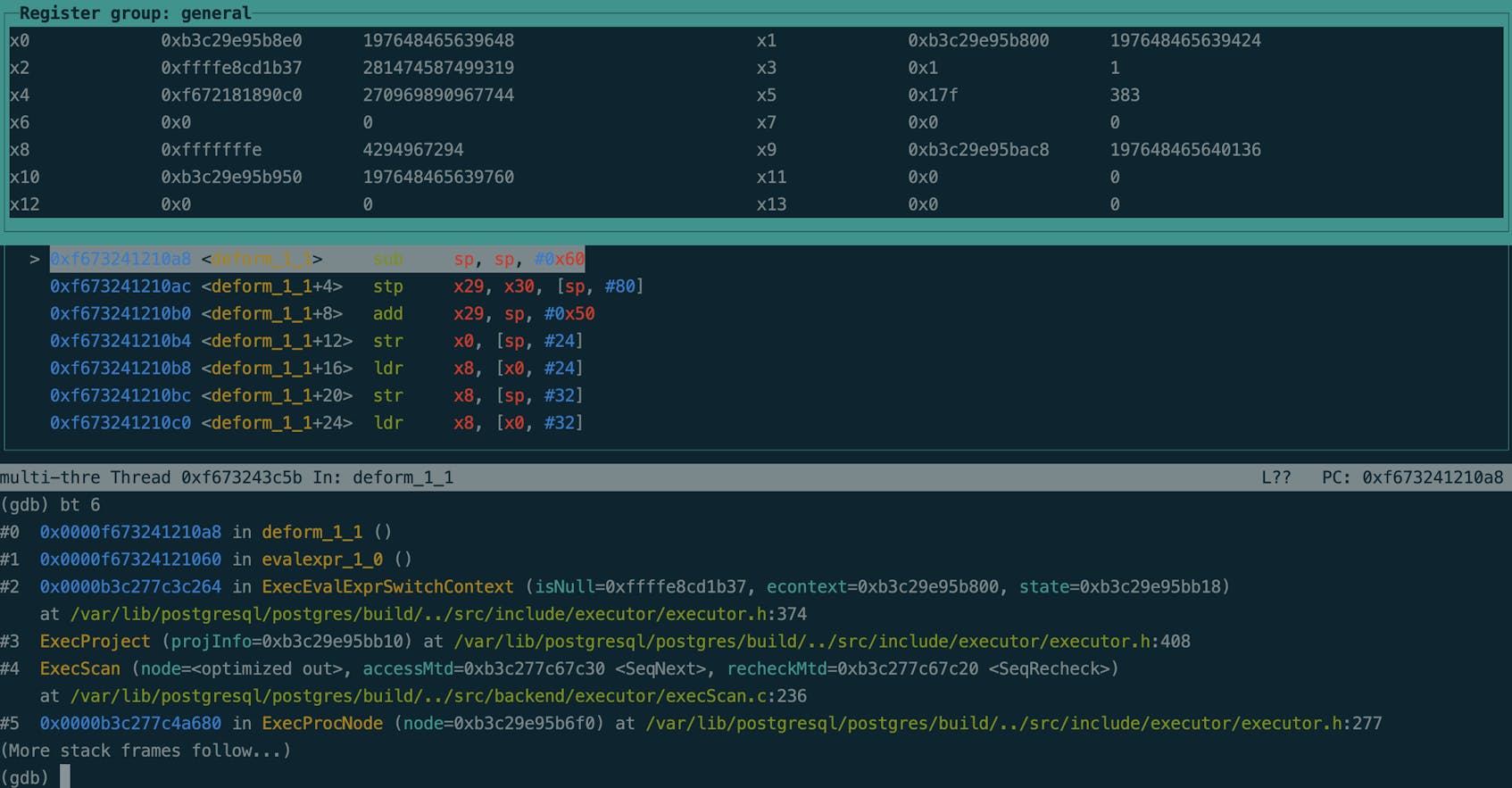
By repeatedly advancing one instruction at a time, we pinpointed the beginning and end of an infinite loop:
- Start:
deform_0_1+140(140 bytes after the start of thedeform_0_1function we saw in the backtrace) - End:
deform_0_1+188
This was the assembly dump for that range:
0xec53660aa130 <deform_0_1+132> adrp x11, 0xec53fd308000
0xec53660aa134 <deform_0_1+136> add x11, x11, #0x0
0xec53660aa138 <deform_0_1+140> adr x8, 0xec53660aa138 <deform_0_1+140>
0xec53660aa13c <deform_0_1+144> ldrsw x10, [x11, x12, lsl #2]
0xec53660aa140 <deform_0_1+148> add x8, x8, x10
0xec53660aa144 <deform_0_1+152> mov x10, x9
0xec53660aa148 <deform_0_1+156> str x10, [sp, #104]
0xec53660aa14c <deform_0_1+160> mov x10, x9
0xec53660aa150 <deform_0_1+164> stur x10, [x29, #-96]
0xec53660aa154 <deform_0_1+168> mov x10, x9
0xec53660aa158 <deform_0_1+172> stur x10, [x29, #-88]
0xec53660aa15c <deform_0_1+176> mov x10, x9
0xec53660aa160 <deform_0_1+180> stur x10, [x29, #-80]
0xec53660aa164 <deform_0_1+184> stur x9, [x29, #-72]
0xec53660aa168 <deform_0_1+188> br x8The loop happened because deform_0_1+188 branched (with the br instruction) to the address stored in x8. However, x8 always pointed back to the start at deform_0_1+140. Carefully tracing the loop step by step helped us come up with a guess for why this was happening:
<deform_0_1+132> adrp x11, 0xec53fd308000
Set x11 to be the address of a 4KB page (0xec53fd308000).
<deform_0_1+140> adr x8, <deform_0_1+140>
Set x8 to be the address of deform_0_1+140 (0xec53660aa138).
This address (and this instruction, in fact) is the start of the infinite loop.
<deform_0_1+144> ldrsw x10, [x11, x12, lsl #2]
Load into x10 the value located at memory address x11+x12*4.
At time of debugging:
- Register x12 was 0, so this loaded the value at memory address 0xec53fd308000.
- The contents of memory address 0xec53fd308000 was 0.
- Therefore, this load instruction set register x10 to be 0.
<deform_0_1+148> add x8, x8, x10
Set x8 = x8 + x10
At time of debugging:
- As x10 was 0, this instruction was a no-op.
- x8 remained the address deform_0_1+140 (0xec53660aa138), which was the start of the “loop.”
<deform_0_1+188> br x8
Branch to address stored in x8.
At time of debugging:
- This branched to the start of the “loop,” on repeat indefinitely!
The key step that felt wrong was the load instruction <deform_0_1+144>, which sets x10 to be zero. If it had loaded a non-zero value, the code might have branched somewhere useful instead. We checked the contents of the memory around the address 0xec53fd308000, and indeed we only observed zeros:
(gdb) x/6 0xec53fd308000
0xec53fd308000: 0 0 0 0
0xec53fd308010: 0 0It took some careful debugging, but we concluded that this assembly code/data was definitely broken. We started to wonder if Postgres was somehow building bad JIT code. We needed to find the JIT builder code in the Postgres source.
Finding the Postgres code that generated the assembly
Thanks to the deform_0_1 name, we could identify the function building the JIT code: slot_compile_deform. This function was more than 700 lines long, and the assembly view in GDB didn’t provide many hints to help us pinpoint the exact part of the function that broke. Fortunately, we discovered that we could generate assembly sources containing additional annotations from the JIT bitcode.
To achieve that, we did the following:
- Enabled
jit_dump_bitcode, which generated$PID.0.bcfiles in the database’sdata_directory. - Compiled the bitcode file into assembly using llc, creating a
$PID.0.sfile with the assembly source:\$ llc -O0 -march=arm64 $PID.0.optimized.bc.
Then, scanning the generated assembly sources, we found the section that we were debugging in GDB:
deform_0_1: // @deform_0_1
.cfi_startproc
[...]
// %bb.3: // %find_startblock
adrp x11, .LJTI1_0
add x11, x11, :lo12:.LJTI1_0
.Ltmp0:
adr x8, .Ltmp0
ldrsw x10, [x11, x12, lsl #2]
add x8, x8, x10
br x8This output gave us a useful find_startblock annotation that pointed us to a specific part of slot_compile_deform:
LLVMPositionBuilderAtEnd(b, b_find_start);
v_nvalid = l_load(b, LLVMInt16TypeInContext(lc), v_nvalidp, "");
/*
* Build switch to go from nvalid to the right startblock. Callers
* currently don't have the knowledge, but it'd be good for performance to
* avoid this check when it's known that the slot is empty (e.g. in scan
* nodes).
*/
if (true)
{
LLVMValueRef v_switch = LLVMBuildSwitch(b, v_nvalid,
b_dead, natts);
for (attnum = 0; attnum < natts; attnum++)
{
LLVMValueRef v_attno = l_int16_const(lc, attnum);
LLVMAddCase(v_switch, v_attno, attcheckattnoblocks[attnum]);
}
}We found the calls to LLVM’s JIT APIs that built this infinite loop assembly. These calls manipulate LLVM Intermediate Representation (IR), which uses blocks to organize instructions:
LLVMPositionBuilderAtEnd: Position the builder at the end of theb_find_startblock. All builder calls will append instructions tob_find_start.LLVMBuildSwitch: Create a switch on the value ofv_nvalidwithnattscases. The switch’s default will target theb_deadblock.LLVMAddCase: Add a case tov_switch, which will jump to the matchingattcheckattnoblocks, depending on the value ofattnum.
The switch statement built by this JIT code can be read as:
switch (nvalid) {
case 0: goto attcheckattnoblocks[0];
case 1: goto attcheckattnoblocks[1];
//...
case natts - 1: goto attcheckattnoblocks[natts - 1];
default: goto dead;
}We didn’t see any issues with this switch statement builder: each “case” targeted an existing block, and the attnum values looked correct.
It didn’t appear that the problem was with Postgres’s JIT usage. What could it be then? We needed to dig a layer deeper into LLVM to understand how this switch statement was compiled into assembly, and how it could have resulted in an infinite loop.
An Arm implementation of a switch statement
As specified by the LLVM switch builder code above, the switch statement wants to jump to one of the attcheckattnoblocks code blocks, indexed by the value of attnum. In the generated JIT assembly, this is implemented by knowing a base address of the code blocks (.Ltmp0) and storing offsets from that base address to the start of each case’s block in memory (.LBB1_**). This offset table is written to read-only memory at .LJTI1_0. There were six attributes (natts=6), which translated to six addresses stored in the offset table:
.LJTI1_0:
.word .LBB1_6-.Ltmp0 // This value in memory is the offset from .Ltmp0 to .LBB1_6
.word .LBB1_11-.Ltmp0
.word .LBB1_16-.Ltmp0
.word .LBB1_22-.Ltmp0
.word .LBB1_28-.Ltmp0
.word .LBB1_34-.Ltmp0Thus, the intended assembly for the switch statement could be read as:
adrp x11, .LJTI1_0 /* Set the start address of the switch offset table */
adr x8, .Ltmp0 /* Set the base address of the switch code blocks */
ldrsw x10, [x11, x12, lsl #2]. /* Load the correct offset from the table in memory (indexed by x12) */
add x8, x8, x10 /* Set the address of the start of the code block: base + offset */
br x8 /* Branch to the start of the code block */You might be able to see the pattern—this is the same assembly code that was in the infinite loop we debugged earlier! The code was for a switch statement. However, in our debug session, the offset table in .LJTI1_0 was filled with zeros instead of useful PC offsets, which explains why we “looped” back to the top of the switch every time.
At that point, we saw a few possibilities:
- The offset table was never set.
- The offset table was set but overwritten by something.
- The offset table was written in a different place.
This was definitely outside of Postgres’s control, since the offset table was managed by LLVM JIT. The next logical step was to investigate how LLVM writes the switch offset table at runtime.
A wild LLVM assertion appears
Digging deeper into LLVM, we decided to compile a version of LLVM with debug symbols and assertions. We only needed the libc project for this, which sped up the compilation time:
$ git clone https://github.com/llvm/llvm-project.git --single-branch --branch release/14.x
$ mkdir llvm-project/build; cd llvm-project/build
$ CXX=clang++-14 cmake ../llvm -DBUILD_SHARED_LIBS=ON -DCMAKE_C_COMPILER=clang-14 -D CMAKE_CXX_COMPILER=clang++-14 -DLLVM_ENABLE_RUNTIMES="libc" -DCMAKE_BUILD_TYPE=Debug -DCMAKE_INSTALL_PREFIX=/var/lib/postgresql/.local -DLLVM_ENABLE_LIBCXX=ON -G NinjaAfter building our debug llvmjit.so, we used it to rebuild Postgres and rerun our query of death. Once again, we saw a totally different failure mode. Instead of a segfault or an infinite loop, we hit a runtime assertion failure while executing the query:
/var/lib/postgresql/llvm-project/llvm/lib/ExecutionEngine/RuntimeDyld/RuntimeDyldELF.cpp:507: void llvm::RuntimeDyldELF::resolveAArch64Relocation(const llvm::SectionEntry &, uint64_t, uint64_t, uint32_t, int64_t): Assertion `isInt<33>(Result) && "overflow check failed for relocation"' failed.Nice—the assertion steered us to the root cause, which was related to resolving address relocation and triggered within LLVM’s RuntimeDyldELF.cpp.
Our next question was: what’s address relocation?
LLVM JIT generates machine code at runtime using the standard ELF format, which contains multiple “sections” of binary data. It writes the code in the .text section, and writes data—like our switch’s offset table—in the .rodata section. For our switch statement code to access the offset table data, the instructions’ position-dependent memory offsets needed to be relocated based on where these two sections were allocated within the process’s memory space.
Relocation is a standard step of code compilation, and happens within a linker. When relocation happens at runtime (such as for JIT or loading a shared library), it is known as dynamic linking (hence RuntimeDyLd).
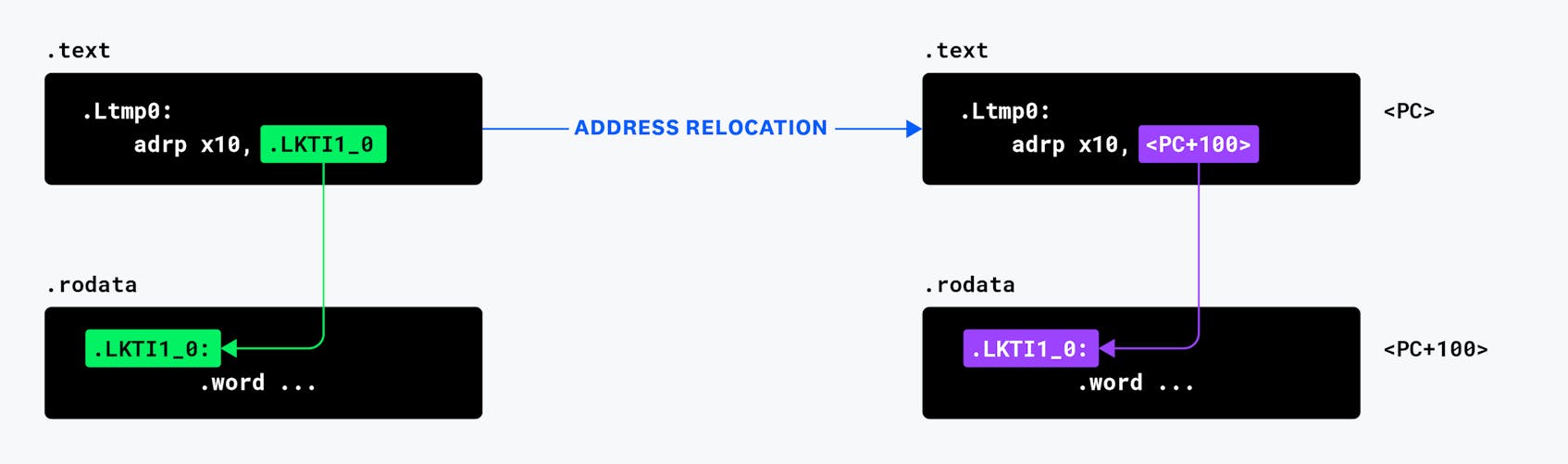
We now understood the basics, but why did an overflow assertion trigger? Arm64 instructions are encoded as 32 bits, whereas memory addresses are encoded as 64 bits. To help access practical memory locations, Arm64 has an ADRP instruction that sets a register to a target memory address that is relative to the current Program Counter (PC). The Address of a Page (ADRP) instruction supports setting the upper 21 bits of a relative 33-bit signed address; the remaining 11 out of 32 instruction bits have other purposes. Thus, ADRP can target a 4KB page of memory located anywhere ±4 GiB from the current PC location.
During the assertion failure, we had the following concrete values:
- ADRP instruction address:
0xf6968298c000 - Switch offset table address (
.LJTI1_0):0xf693ecbca12c - Address relocation distance:
0x000295dc2000(which is ~10.3 GB away)
The distance between the instruction (in the .text section) and the switch offset table (in the .rodata section) is ~10.3 GB. This is clearly greater than the ±4 GiB that the ADRP instruction can “reach”!
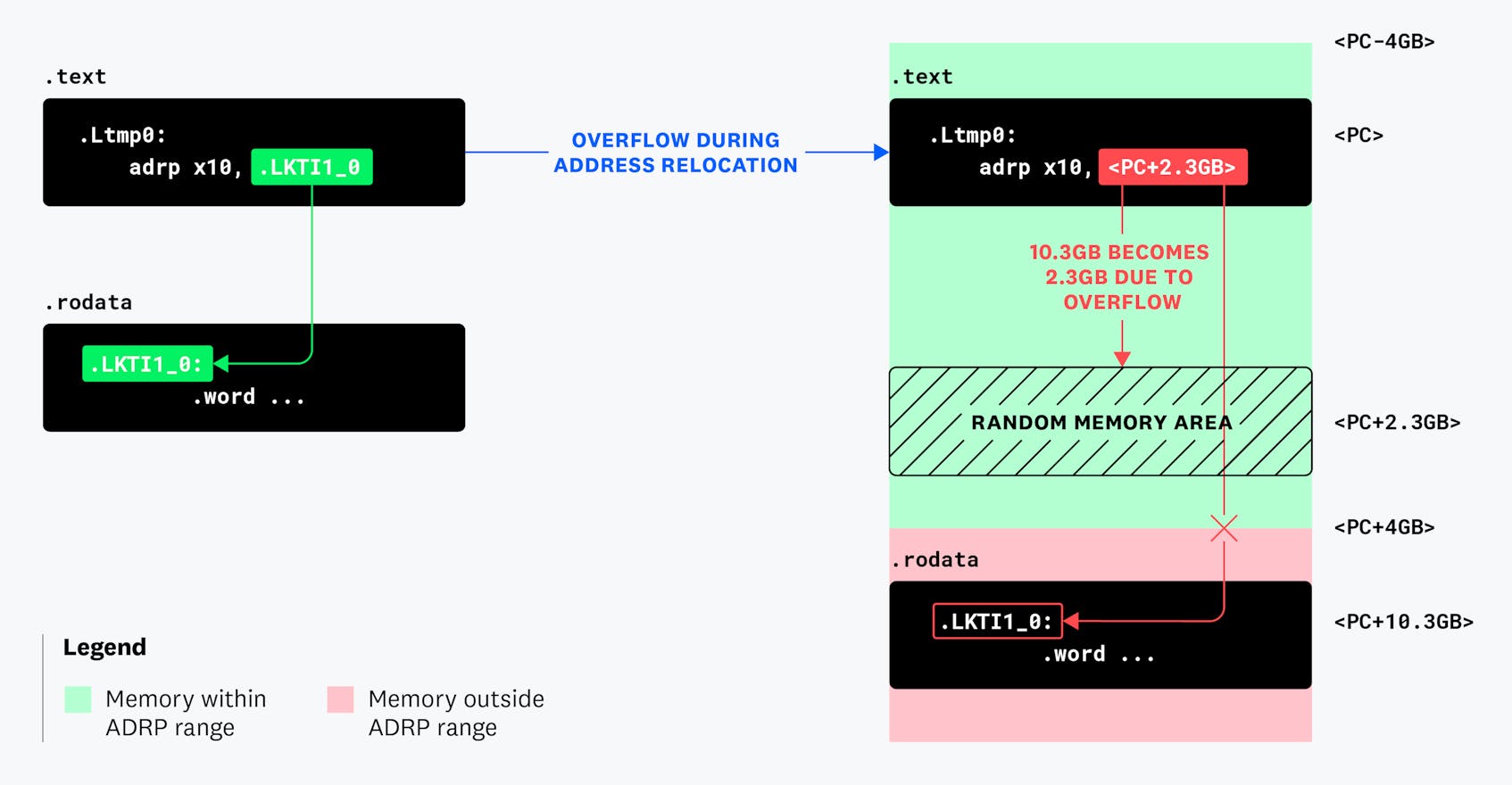
This specific problem also explained why we had different failure symptoms. The release version did not have assertions enabled, and relocated to 0x00000002_95dc2000 & 0x00000001_fffff000 = ~2.3GB (the relocation bitmask dropped upper bits). In the case of the segfault, the targeted memory area was filled with a random value, causing the code to branch to a random location. In the debug mode where we saw the infinite loop, that memory area was filled with zeros.
Our curiosity persisted, and we needed to understand why these locations were so far apart in memory.
JIT section allocations vs. Arm64 ABI requirements
While JIT uses the standard executable ELF format and sections, JITed code isn’t compiled into an executable file on disk. Instead, it’s written directly into memory sections for immediate execution. In our version of LLVM, sections were allocated using the aptly named allocateSection method:
sys::MemoryBlock MB = MMapper.allocateMappedMemory(
Purpose, RequiredSize, &MemGroup.Near,
sys::Memory::MF_READ | sys::Memory::MF_WRITE, ec);To understand where these sections were being allocated at runtime, we re-ran our query of death with a GDB breakpoint on this function. The breakpoint triggered three times to create the following sections:
.textsection allocation:{Address = 0xfbc5b9cea000, AllocatedSize = 90112}.rodatasection allocation:{Address = 0xfbc84fab9000, AllocatedSize = 4096}.eh_framesection allocation:{Address = 0xfbc84fab7000, AllocatedSize = 8192}
Between .rodata and .text, we noticed the familiar distance of ~10.3 GiB.
You may have noticed that the code snippet above has a Near argument. LLVM actually passes the previously allocated section’s address in an attempt to allocate all of the sections near one another. This is the mmap’s first parameter addr, and reading the Linux docs, we see the following:
“If addr is not NULL, then the kernel takes it as a hint about where to place the mapping; on Linux, the kernel will pick a nearby page boundary (but always above or equal to the value specified by /proc/sys/vm/mmap_min_addr) and attempt to create the mapping there. If another mapping already exists there, the kernel picks a new address that may or may not depend on the hint.”
Linux doesn’t provide any guarantee that it will honor the hint or how close the resultant allocation will be. In contrast, the AArch64 ABI large code model has several hard requirements related to code and data locations; notably, the text segment, which contains both the .text and .rodata sections, must not exceed 2 GiB. Given what we’ve learned about the ±4 GiB PC-relative memory range supported by the ADRP instruction, this requirement is not surprising. Other types of relocation have a smaller memory range, bringing down the maximum segment size to 2 GiB.
Comparing these requirements to AMD64 explained why this is an Arm64-specific issue. In the AMD64 ABI (3.5.1, Architectural Constraints), large code models must use the movabs instruction, which supports 64-bit addresses—meaning it does not have this dynamic relocation distance limitation.
Investigation summary
To summarize the findings of our investigation:
To optimize an expensive query, Postgres correctly used LLVM JIT APIs to compile native “tuple deforming” code to scan a database table.
As part of standard JIT compilation, separate code and data sections were allocated in memory. The JIT code and data were written, and position-dependent instructions were adjusted as needed (the “relocation” step).
The bug: LLVM didn’t enforce the Arm64 ABI requirements, and on our machine, the
.textand.rodatasections were allocated 10.3 GiB away in virtual memory (the requirement is within 2 GiB).This ABI violation caused a bad relocation, resulting in the generation of incorrect machine code (silently in LLVM release mode, as assertions are disabled).
Once the JIT code was executed for the SQL query, we saw undefined behavior in Postgres, including segfaults and infinite loops.
The resolution: A fix released in upstream Postgres
Thanks to this investigation, we were able to confirm that the crashes were limited to queries using JIT on Arm64. After our discovery, we disabled JIT on Arm64 hosts (jit = off in postgresql.conf) to prevent the bug from triggering in the short term. We also had the option of migrating to AMD64 instances, but disabling JIT was acceptable.
It turns out that this was a known issue per the LLVM issue tracker, as this bug had also impacted other projects using LLVM JIT, such as Julia, Numba, and CUDA-Q. At time of writing, there’s an open PR by MikaelSmith to fix it, which changes the logic to create all ELF sections within a single mmap allocation, eliminating the possibility of gaps when making multiple mmap calls. However, it turns out that modern versions of LLVM use a new dynamic linker, JITLink, which aims to deprecate RuntimeDyld. JITLink isn’t impacted by this bug, so the PR hasn’t received a lot of attention.
Other Postgres crash reports from recent years (example #1, example #2) also mentioned segfaults on Arm64. Similar to our case, the corrupted stack traces and unclear trigger conditions made them challenging to debug. With our new understanding, we can see that those reports were also related to JIT, although we haven’t confirmed that they were caused by this LLVM section allocation issue.
In August 2024, we opened a pgsql-hackers thread to discuss our findings with the community. We considered nudging the open LLVM PR to be merged, but we realized that many supported Postgres versions were using older versions of LLVM—as old as LLVM 10 for PG12. Even if the PR were merged into LLVM 19, it would be atypical for such a large LLVM version upgrade to be backported into Postgres minor version patches.
Thankfully, LLVM’s APIs are pluggable, and it’s possible to provide a custom SectionMemoryManager to RuntimeDyld. This enabled Thomas Munro, a Postgres developer, to patch MikaelSmith’s work into the Postgres source tree and ship Postgres with a fixed memory manager that respects the Arm64 ABI. The patch was committed on November 6, 2024 and released on November 14, fixing the issue in Postgres versions 17.1, 16.5, 15.9, 14.14, 13.17, and 12.21! We are happy that our work resulted in a reliability improvement for Postgres on Arm64, and we had a lot of fun investigating our system internals.
Interested in diving deep into database performance, managing Postgres at scale, and developing infrastructure control planes? Datadog is hiring!
