

Users expect web applications to be fast and responsive, with smooth scrolling and almost instantaneous rendering. Combining complex UI interactions with frequent data fetching, as many Datadog products do, makes optimizing for good runtime performance a challenge. Dashboards in particular is difficult as, unlike other products, users have complete control over the size of their boards and the complexity of their queries.
This post describes how we developed a new query and render scheduler, conceived initially to optimize Dashboard performance but then generalized for use on any expensive task or fetch-heavy application.
Dashboard scheduling v1
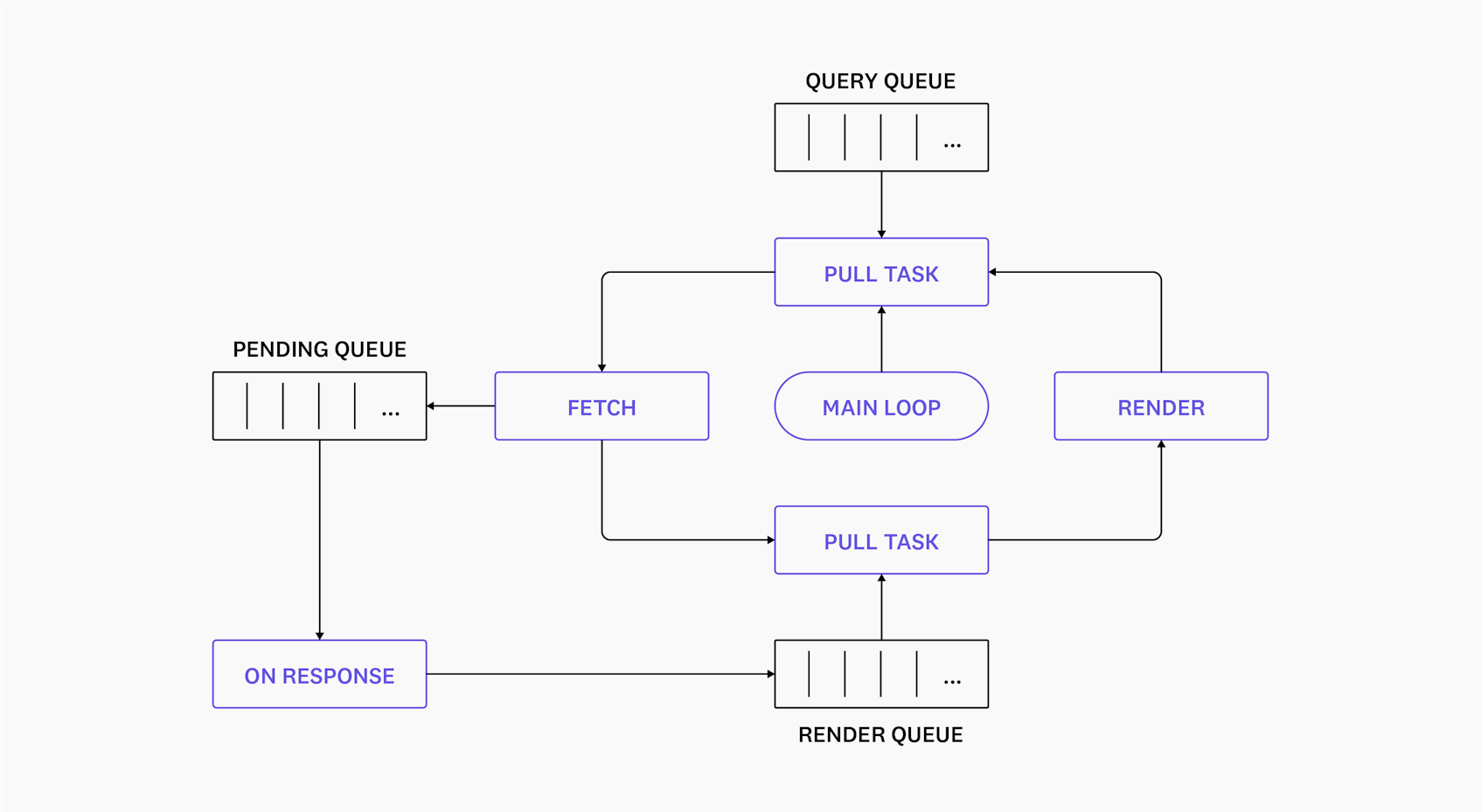
Dashboards had an existing scheduling system used to manage when fetches and renders occurred, composed of the periodic updater and the query and render task queues.
The periodic updater controls how frequently a widget requests fresh data. This cadence is determined by a number of factors - the time frame selected, whether the browser is focused or not, etc.
When a fetch is requested, the scheduler enqueues a new query task that defers when the fetch actually happens. Tasks for visible widgets run immediately; those for offscreen widgets are delayed based on a set of heuristics (number of pending queries, time spent on previous fetches, etc.). The main goal of the query scheduler is to produce a flatter distribution of queries in time, in order to improve browser performance and, across all dashboards, produce a more stable load on our backend services.
When data is returned, a render task is created. Again, renders for visible widgets happen immediately and those for non-visible widgets are delayed according to a new set of rules. The role of the render scheduler is to reduce the load on the browser’s main thread.
We found that this legacy scheduler performed well compared to an unscheduled baseline, minimizing work for the browser by favoring visible widgets and more efficiently distributing fetches within a given time frame.
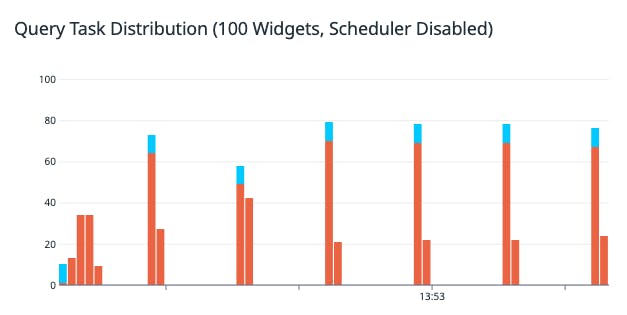
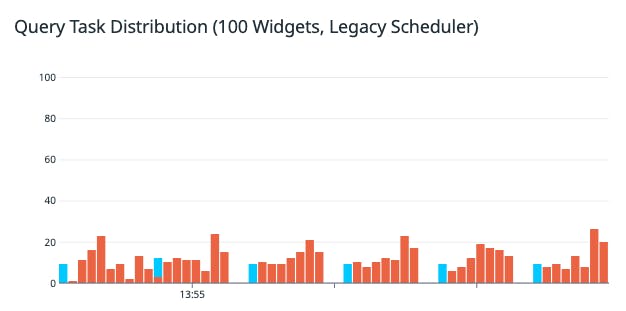
Despite this, there remained some significant issues with this algorithm.
Though initially conceived as a simple set of rules,the scheduler had grown to become a web of interlinked heuristics, with around 20 different parameters controlling its behavior. This produced a complex and dynamic system that made it difficult for developers to reason about how a dashboard updated and rendered its content.
These rules did not clearly separate query from render scheduling. For example, queries were given an extra delay if too many render tasks were pending, a consideration with no obvious link to the goal of throttling fetches. Similarly, renders were delayed if the fetched data was deemed sufficiently large, even when the browser had the resources to perform it. This meant that, although better than baseline, the scheduler was not working as efficiently as it might, particularly with respect to rendering.
Finally, the original scheduler had been written solely for dashboards, and was tightly bound to how a board fetched data and rendered widgets. Since then, our widgets have become more generalized components used across our product suite, with a standard framework for querying and renders.
Building a general-purpose scheduler
We felt it was time to revisit the scheduler, not only to clean up its rules and simplify its logic but to make its benefits more generally available to applications across Datadog, on any page in which a large number of widgets are used.
Changing such a critical code path was risky, with potential impacts on both the user experience and our backend services. So we had to proceed methodically - first by evaluating the utility of the existing scheduler’s rules, then by separating query and render scheduling into discrete modules that could be tested and rolled out separately.
In the following sections, we describe this process. Firstly, how we arrived at a new algorithm for query scheduling, one that works independently of how data is rendered and could be used across Datadog. Next we outline how we implemented a general-purpose render scheduler using the new Browser Scheduling API, allowing us to schedule any sufficiently costly task.
A Simpler Query Scheduler
We began by testing the original scheduler across dashboards of various sizes and under different conditions, to establish the true utility of its heuristics. We found that many could be discarded with no impact on performance. For example, tasks were delayed when a tab was unfocused or occluded by another window. The periodic updater already throttles updates in these cases, and the browser itself pauses JavaScript in unfocused tabs.
Next, we experimented with various scheduling algorithms, testing in the same manner. Our aim was to keep the task distribution sparse with fewer peaks, while still favoring fetches for visible widgets.
We eventually arrived at a simple algorithm that met these goals:
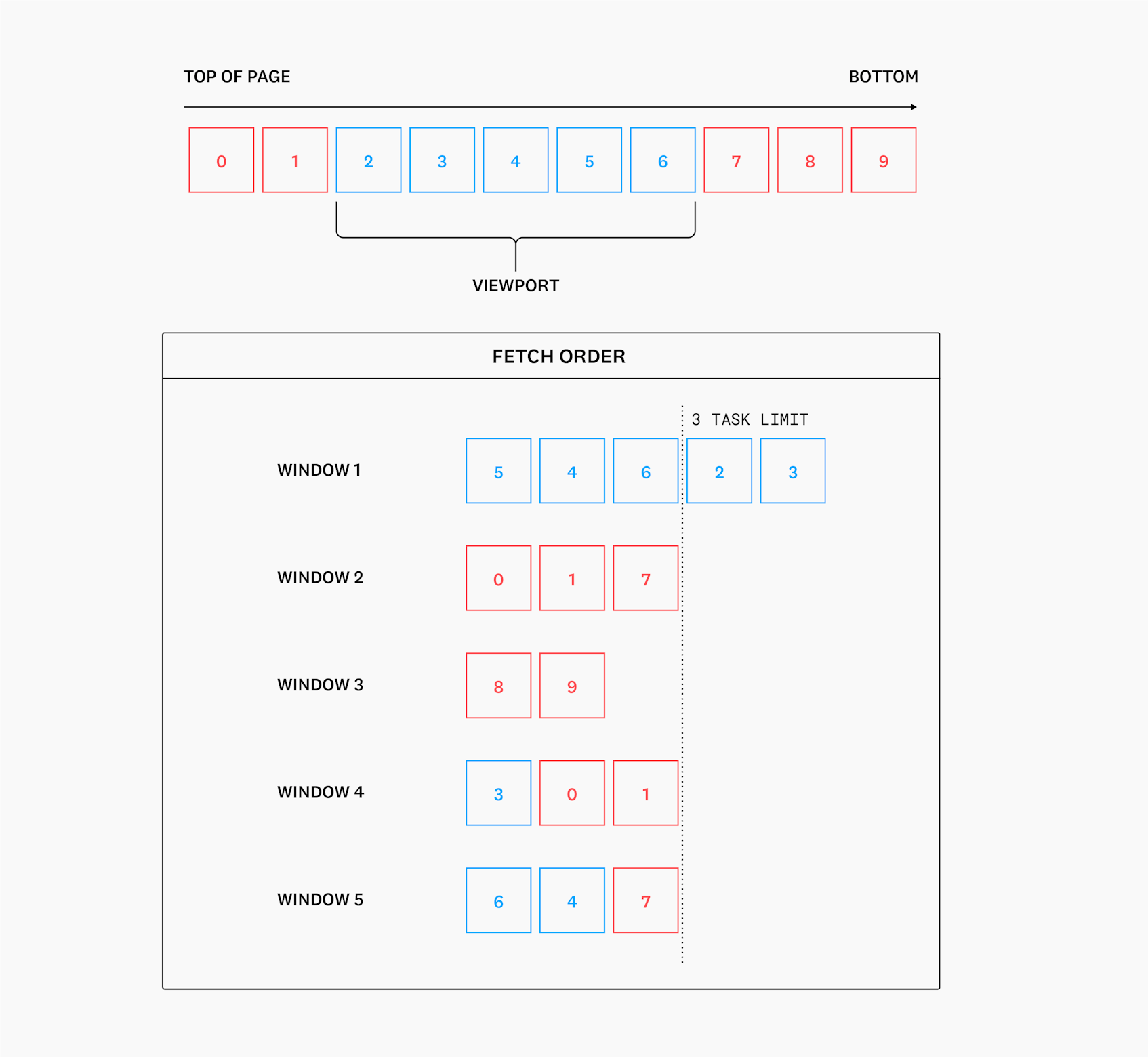
- Fetches for visible widgets are performed as soon as requested;
- Non-visible queries are ranked & as many as possible run per fixed time window, up to a set task limit;
- Task execution is paused if the number of pending fetches is sufficiently elevated.
Variations we tested differed in how the time window was calculated (e.g. scaled based on the time frame) or how offscreen tasks were ranked (e.g. favoring those close to the viewport), but we found that results between these did not differ greatly and thus chose the simplest option: a fixed time window of 2000ms, a 10 task limit, and offscreen tasks ranked by enqueue time (favoring earlier & first requests).
In contrast to the old scheduler, this new algorithm was governed by only 6 parameters (the time window duration, task limit, widget visibility etc.)
These changes were rolled out progressively, starting with dashboards, then deployed more widely by integrating the scheduler into the data-fetching framework used by widgets across Datadog.
We found that the scheduler performed well, with the simpler logic producing a better distribution of tasks compared to the old algorithm.
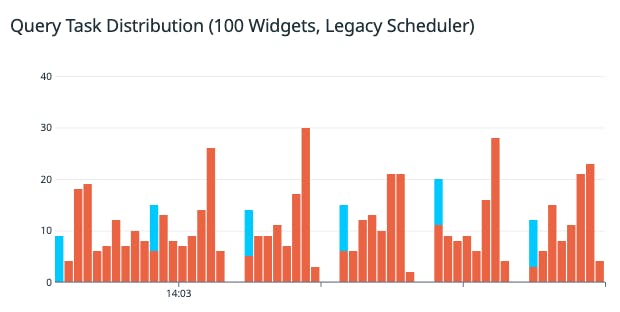
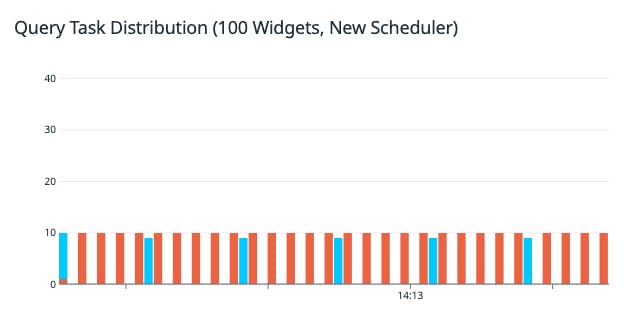
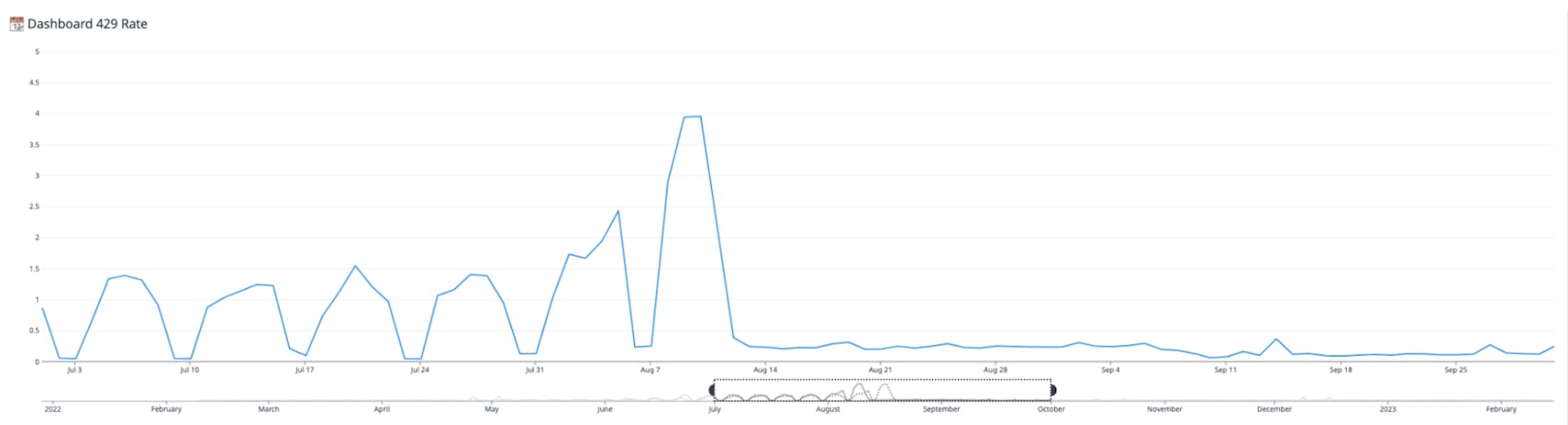
In addition, the number of “429 (Too many requests per account)” errors dropped significantly, due in part to the more efficient task distribution. A 429 response will cause the query to be retried at a later time, so fewer errors of this nature mean data is fetched more quickly.
Render Scheduling with the Browser Scheduling API
Although the original scheduler helped distribute render tasks in time, it was ignorant of the CPU and memory resources available to the browser, meaning that expensive renders could still be inefficiently scheduled.
The Browser Scheduling API is a new API for creating prioritized tasks that are natively scheduled by the browser. This means that the most relevant work can be given a high priority and performed when the browser has sufficient resources, with less important work relegated to a background task, run when the browser is idle.
The API is currently implemented in Chromium and Firefox Nightly, with a polyfill for other browsers.
// Create a TaskController with one of the preset priorities (user-blocking, user-visible or background)
const controller = new window.TaskController({ priority: 'user-visible' });
const signal = controller.signal;
console.log(signal.priority); // Logs 'user-visible'
console.log(signal.aborted); // Logs false
// Schedule a task, passing it the signal i.e. the task inherits the controller's priority
window.scheduler.postTask(() => doSomething(), {
signal: controller.signal
});
// Later we can update the priority for all the controller's tasks en masse ...
controller.setPriority(newPriority);
// ... or abort every task registered with the controller
controller.abort();
This is sample code using the Scheduler API. Tasks are created with either “user-blocking”, “user-visible”, or “background” priority. The controller allows tasks to be updated and aborted en masse.
We used this API to implement a new render scheduling algorithm:
- Renders for visible widgets are scheduled with the second-highest priority (“user-visible”), meaning tasks are run when the browser has sufficient resources;
- Renders for widgets outside the viewport are given the lowest priority (“background”), meaning they are performed once the browser is idle;
- All renders are scheduled, whether they result from a query response or a user interaction (unlike the legacy scheduler, which optimized only renders resulting from a data fetch).
We again integrated this scheduler into the framework used by all widgets, meaning that the benefits of render scheduling were felt across Datadog. Moreover, we realized that the ability to efficiently schedule expensive tasks could be generally useful, so a helper component was built to allow its wider adoption.
// A function with an expensive async task
async function myFn() {
const result = await sendTelemetryMetrics();
// ....
}
// The same function with the task scheduled to run in the background i.e. the browser will only execute the
// function when time is free on the main thread
async function myScheduledFn() {
const result = await scheduler.postTask(() => sendTelemetryMetrics(), {
priority: 'background'
})
// ...
}
This is an example of generalized use of the scheduler API. As postTask returns a Promise, any asynchronous task can be scheduled with only a small change to the code. This kind-of usage was encapsulated in a helper component.
Once deployed, we found that the scheduler significantly reduced the number and duration of widget renders. This improvement was measured wherever widgets were used - not only on dashboards.
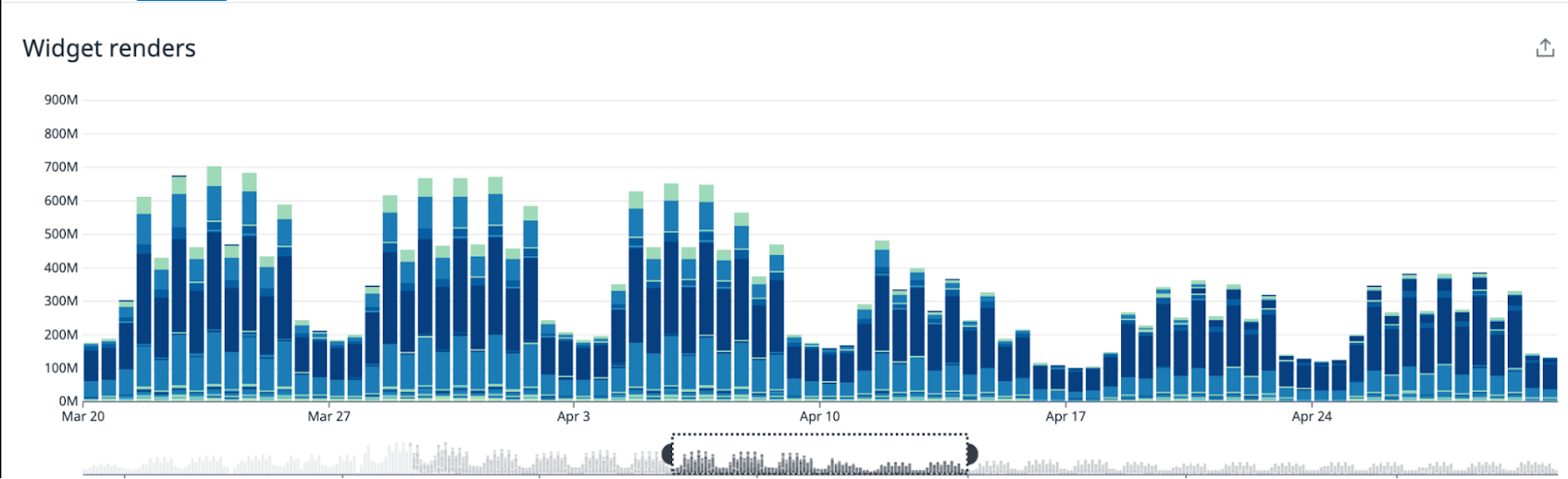
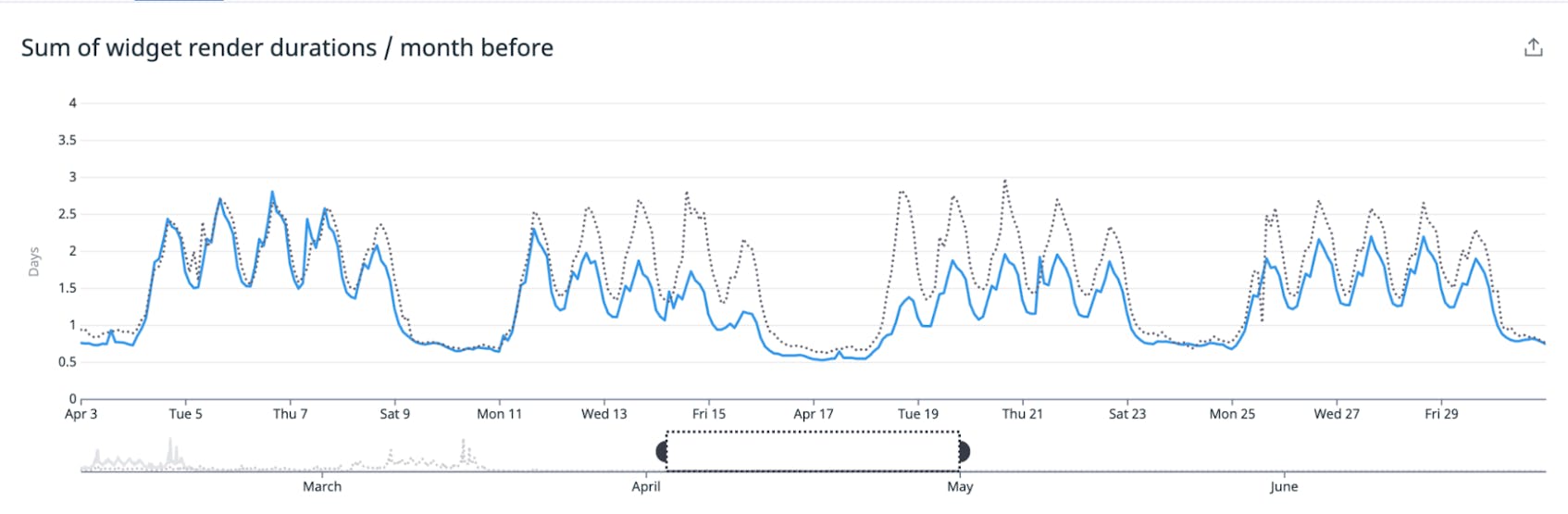
Its effects were also evident in performance-sensitive interactions, such as widget drag-and-drop, where we saw a greatly reduced number of “long tasks” (i.e. tasks that occupy the browser’s main thread for a period greater than 50ms).

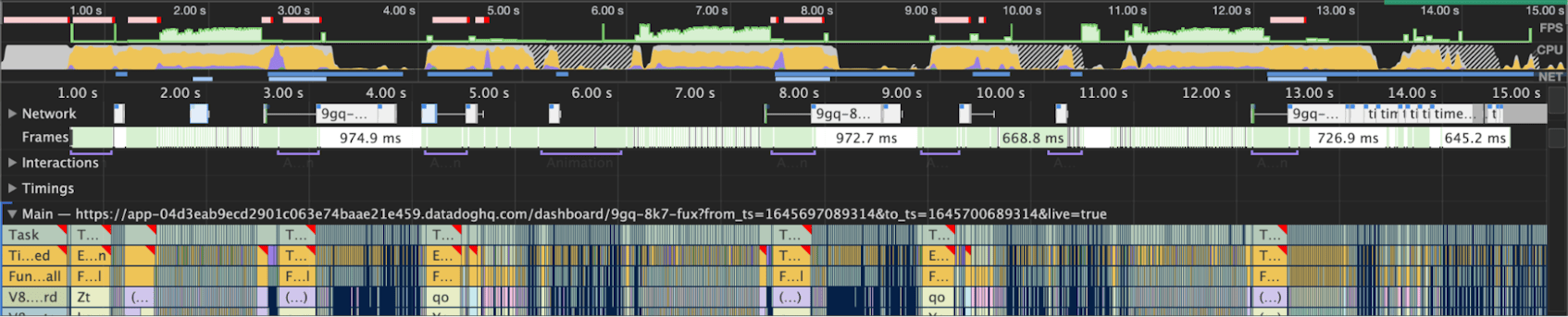
Faster widget renders and fewer long tasks mean fewer occasions when the browser is overloaded, producing a faster and more responsive UI, which we saw both in our performance metrics and experienced in our day-to-day use of Datadog.
What’s next?
We continue to track the performance of the query scheduler in production and, with this data, intend to continue tuning its parameters to further reduce the burden of offscreen fetches without impacting on perceived performance.
The tools that came from the render scheduling work are being increasingly used across Datadog, wherever a particularly expensive task can be delayed until a later time.
