

In a previous blog post, we introduced our Husky event store system. Husky is a distributed storage system that is layered over object storage (e.g., Amazon S3, Google Cloud Storage, Azure Blob Storage, etc.), with the query system acting as a cache over this storage. We also did a deep dive into Husky’s ingestion pipelines that we built to handle the scale of our customer data. In this post, we’ll cover how we designed Husky’s underlying data storage layer.
When designing a data storage system, there are different tradeoffs available depending on the scale of the system and how it is used. Questions you have to answer are: How often do you compact the data, what file size do you target, how do you sort the data, and which indexes do you build on the data. In our case, we needed to build a system that could process and store trillions of events per day sent from a huge range of data sources. Husky is built to store observability data, meaning that the typical pattern of use is a large write load of new data with little to no updates of existing records. Queries are biased toward the youngest edge of data, with some analytical queries reaching into older data. So, our system has to respond to both a high rate of queries of short duration, and analytic queries that may need to scan billions of events.
How Husky executes queries
When Husky ingests event data, it aggregates it into files—called fragments—that it then saves to object storage. Husky generates and separately stores metadata for each fragment. When Husky executes queries, it uses this metadata to discover all fragments relevant to a query and then distributes the work to a pool of workers. Each worker scans the fragment assigned to it. The results of all worker scans are then merged together. This means that the cost of executing queries is proportional to 1. the number of fragments that must be fetched from object storage, and 2. the number of events within those files that must be scanned. To solve these problems, we designed Husky’s storage system to:
- control the number of files in the system by efficiently compacting them using a streaming merge approach, and
- organize and spread the data in files in a way that limits the number of events scanned per query.
The compaction Goldilocks problem
The principle of a compaction is quite simple: take many small fragments and combine them to create a new, bigger one that contains exactly the same data. Then, atomically swap the old fragments with the new one so that the query system always sees the same data at any time, before, during, and after a compaction. It can now process one big fragment instead of many small ones.
Because we are serving data for observability purposes, data needs to be queryable by users as soon as possible after it is ingested. Writers in the data ingest pathway buffer events for each tenant. This helps ensure the writers don’t write very tiny fragments to object storage, but adds a delay to the availability of that data. So, the writers typically cap the amount of time any event can wait in one of these buffers before they are flushed to object storage, one fragment per buffer. These fragments each contain a subset of events for a logically contiguous database table, where each row represents a single event.
To keep track of the individual fragments for a given table, Husky stores metadata for each fragment in a metadata repository, backed by FoundationDB. We use FoundationDB because its transaction mechanism provides the atomicity guarantee described above—an update to a table for a compaction will make the compacted fragments visible and the old fragments invisible in a single transaction. When a metadata scan for a query finds relevant fragments, the scan only sees the state of the table either before or after the transaction.
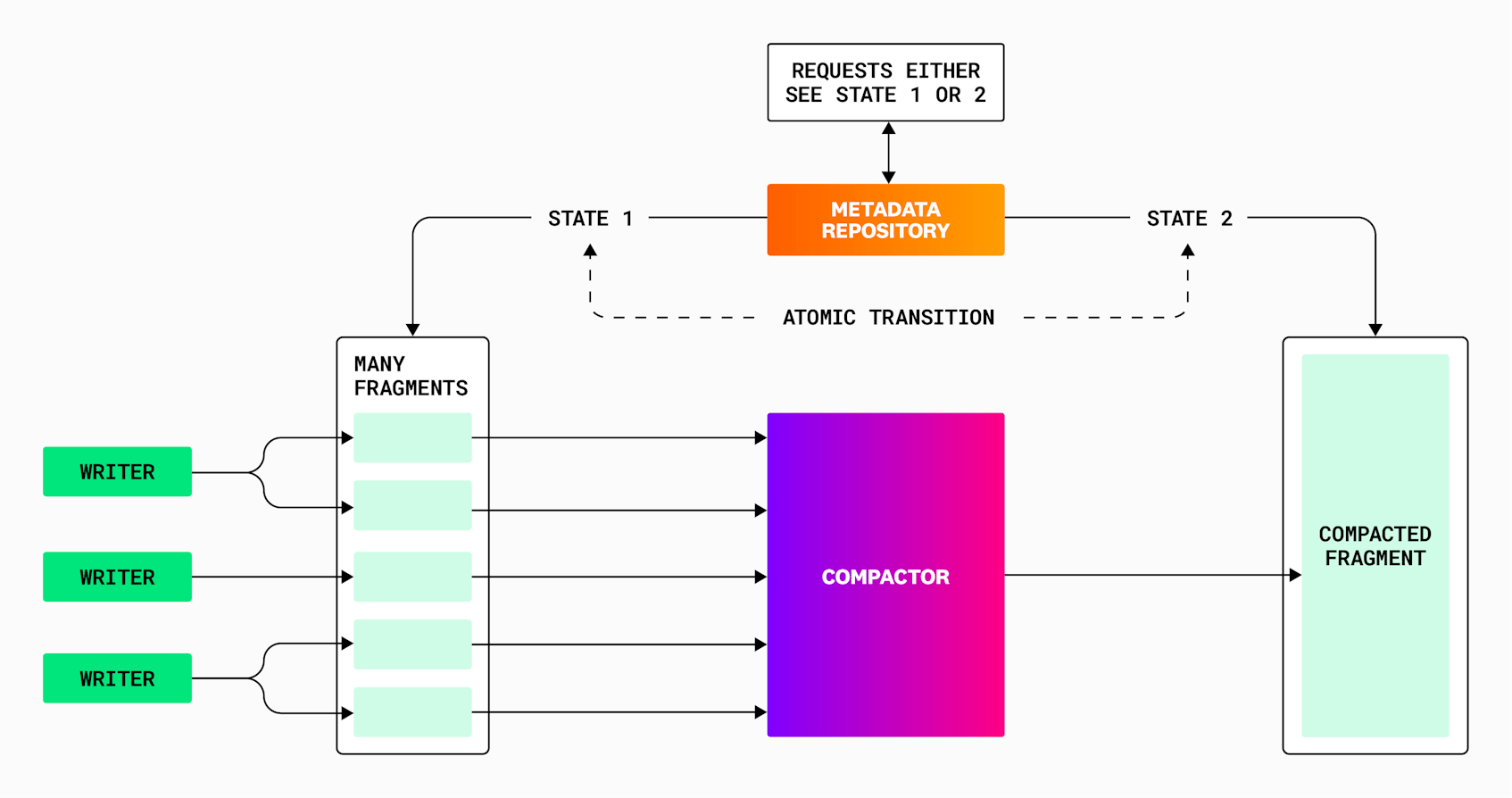
New fragments are created frequently as new events arrive. These fragments are small, containing a maximum of a few thousand events. Queries that need to run fetches across many small objects and lots of file metadata items are not efficient. We need to merge—or compact—these small fragments together so that Husky doesn’t have to read many thousands of them during a query.
Ensuring that this compaction system gives us the performance we need is all about finding the right fragment size that maintains a good balance among the following concerns:
- For object storage fetches and metadata storage, fewer fragments are better.
- For compaction, less work is better, both for CPU used in compaction and the number of PUT/GET requests to object storage.
- For queries, where each fragment relevant to the query is read concurrently by a pool of query workers, the trade-off is a somewhat complex one between having fewer, larger fragments while maintaining high parallelism. We’re balancing the speed at which a single worker can scan the rows in a fragment with the overhead of distributing a query to many workers, which can scan many fragments in parallel for larger queries. There is an optimal fragment size to balance between scan speed and distribution overhead.
- Compaction can affect storage layout in a positive way, but at the cost of doing more work. Given a particular common query pattern, events can be laid out in the fragments, both in the time dimension and in spatial dimensions (i.e., by tags), so that events that would be relevant to a given query can be close together. Keeping similar events close together improves compression, but it is in tension with “less work is better” as compaction will work harder to achieve this layout, and some analysis of queries must be done to determine the layout for the best system-wide outcome.
In short, fragments that are “too small” are inefficient for queries because many small fetches pay an object storage latency penalty and aren’t as efficiently processed by the query workers, which implement vectorized execution to scan many rows quickly. Fragments that are “too large” drive down parallelism for larger queries, causing those queries to take longer. Compaction attempts to find a fragment size that is just right for typical query patterns to minimize query cost and latency, while at the same time keeping similar data together.
Running efficient compactions
Husky relies on being able to compact data efficiently and cheaply. From the beginning, we had to ensure that we could do it at scale.
It would be expensive to merge files together as soon as they are queryable by the users; most of the time, compactors would merge only two files together: a large one accumulating everything for the current time window and a small one recently created by a writer. For that reason, compactions of recent files are done in a lazy way: they are delayed until the resulting compactions are deemed “efficient enough.”
In order to get the best possible outcome, Husky uses multiple “efficiency” criteria to accommodate for the different fragments’ shape, but the main idea is to wait until a few dozen fragments are available to merge together. This keeps the number of files to query for the read path small, while simultaneously being cheaper in CPU and object store API costs—by an order of magnitude as compared to the naive approach. When the probability of receiving more data becomes low, a (presumably) final compaction is triggered. This makes sure that we eventually reach a state where data is stored in its most compact form, suitable for long-term retention.
While each compaction needs to be efficient individually, the key scaling criteria are:
- Issue only 1 GET request to storage per input fragment, then stream the data in parallel.
- Saturate the CPU while processing the data.
- Use a fixed amount of memory that is less than the memory available for one CPU.
To do that, we built our own storage format for efficient streaming.
The fragment file storage format
Fragments use a columnar storage format that works similarly to Parquet—with one row group and many pages—but that is specially designed for use with observability data. A single fragment contains many columns, each preceded by a column header. This header allows compaction to stream input fragments from a single GET request, discovering columns as the streaming progresses.
Because we don’t control how customers send us their data, fragments must be able to support a huge variety of events, with individual tables containing data from any number of services. It’s not unusual for Husky to have fragments that, after compaction, contain hundreds of thousands (if not millions) of columns. Our custom serialization format gives us more control over compacting them together. Streaming compaction allows us to process these files efficiently.

A fragment consists of a concatenation of entire columns. Data in each column is split into row groups (similar to pages in Parquet terminology), which are sets of consecutive values from the column. The number of rows in each row group is fixed and uniform across all columns in a fragment file (more on this below). This limits the amount of memory needed both to stream the fragment during compaction as well as during queries—only one row group needs to exist in-memory when reading the column. This format also simplifies query execution when reading multiple columns in the same query by limiting queries to read only the relevant columns. With this layout, compaction can proceed one column at a time, one row group at a time, with a bounded amount of memory being used during the compaction.
But what is a “compaction,” anyway?
A single compaction takes the events from multiple input fragments and merges them into one or more output files. This merge is not a concatenation, it is a k-way merge. The rows of the input files are shuffled together according to a sort order, defined by a sorting schema. This schema consists of a set of zero or more columns plus the timestamp column. These columns define the sort order across all of the events in any given fragment lexicographically, and the ingest and compaction systems maintain this ordering invariant for all fragments. The writers sort the events before writing them to individual fragments. Compactors then maintain this sorting order when merging the events from multiple files together by reading the sorting columns from all of the input files, constructing the global sort order for the output files, and then streaming each column from all of the input files simultaneously, writing the rows of each column in the output according to the global sort order. The output is a set of one or more fragments that maintain the sorting. In the case of more than one output file, they are disjoint with respect to the sorting order. More discussion of this below.
In the above diagram, two fragments, F and G, are compacted into one. The sort order that is maintained during compaction is generated from the columns in the sorting schema: service and time. The sequence of the rows within the other columns, host and message, is generated from this sort order, and the rows within those columns are written one by one in the output fragment.
The layout of the fragments facilitates this process. Each column may be read and written in its entirety before moving on to the next column. In addition, because the columns are divided into row groups, the amount of memory used during the merge is bounded to one row group per input fragment.
Row group size
When compacting, we are very careful to control the maximum size of a row group in the output files. This is due to the underlying variability in the data we are ingesting and processing with Husky. For example, depending on the event that generated it, the “message” column for logs can vary wildly in size and potentially be very large. We allow up to 75 KiB for the message field in logs. As we place similar logs close together (more on that in the Sort schema part), it can happen that multiple 75 KiB log messages are part of the fragment and even the same row group. Just 15,000 such events require more than 1 GiB of memory to process the column, and we more often target millions of events in a fragment. This means it is not feasible to handle a whole column without row groups.
The compactor endeavors to keep the amount of memory used per row group relatively constant, so it chooses a row group size for a particular output file based on the maximum size of the data in the most heavyweight column among the input files in order to control the upper bound of memory usage. If the compactor detects the fragment it is currently writing exceeds the maximum row group size, it will restart from scratch with a smaller row group size.
Now that we know how Husky’s custom fragment storage format lets us run efficient compaction, we can look at how the compaction process organizes the resulting fragments globally in order to improve query performance.
Time bucketing
Datadog traffic is ephemeral, meaning we know that when we receive an event, we will have to delete it eventually. We mostly receive events that are close to the current time, and queries use time as a primary filter. Because of this, Husky places customer events into time-dimension buckets based on their timestamps, so that queries only have to examine the buckets relevant to the query. Fragments in a particular table contain events for a single time window.

Husky splits the dataset into a distinct set of tables and time windows, and the compactor only merges fragments in the same bucket—same table and time window. We keep track of which buckets received new data recently to determine where compaction may be needed. Regardless of its age, all data is ingested the same way: it is just another bucket with modified data to be compacted.
Size-tiered compaction
The compaction service’s primary goal is to minimize the number of small fragments so that the total number of object storage GET requests are minimized and the number of fragments tracked by the metadata service is reasonable. Compaction uses a relatively standard size-tiered scheme to reduce the resulting number of fragments by merging them together in groups of exponentially increasing size classes. Within each size class, a set of fragments is selected, so that the merged fragment is in the next size class. A fragment is written to object storage containing these merged rows, and then the metadata service is updated, removing the old fragments and inserting the new fragment in a single atomic transaction. This happens at every size class, eventually yielding fragments containing roughly one million rows, compared with the thousand-row-size fragments at writer output.

So, in addition to reducing the data in the time dimension by bucketing it into windows, we are also reducing the overall number of fragments by the size-tiering. However, within a given time window, a query must still scan every row of every fragment to make sure that any rows relevant to the query are found. If we could have a way to quickly discard a fragment by only looking at its metadata, that would be an extra improvement to reduce the amount of data to scan.
Sort schema
Queries tell Husky what rows are relevant via predicates over tags. For example, a query looking for error logs from the compactor service might be of the form service:compactor env:prod. In this case, it makes little sense for Husky to scan rows for the env:test environment, or look for logs tagged service:kafka—these aren’t relevant. So the question is, how can we avoid visiting these rows and thus optimize query performance?
The answer: we pick a set of tags relevant to the query, sort the rows using this set, then avoid using fragments that can’t possibly contribute a relevant row to the query.
For deciding the relevant tags and their precedence, some analysis of query patterns on a product level suffices to yield a reasonable sort schema. To give an example, this is what we use for typical logs tables:
service,status,env,timestamp
As we can see, the most important is service, followed by status, which makes sense. Users want to search for logs for their particular service that have interesting status codes.
So how do we sort by this? If we were just sorting a complete set of rows in a single time window, we could just do a single distributed sort and leave it at that. However, in our case new rows are constantly arriving. To solve this, we use a log-structured merge (LSM), which is the typical solution for a high-write-throughput system such as ours. As Husky’s writers produce each fragment at ingest time, they combine the values of each of these fields, in the given order, into a row key. Then, they sort the rows (events) by this key and write them to the fragment, recording the schema used to sort the fragment in its header, along with the minimum and maximum row keys, which define the lexical “space” the fragment occupies.

In the above diagram, four fragments are spread across the lexical space service,status,env. For example, the minimum and maximum row keys for Fragment W are enough to conclude that it can only contain events with service:compactor. A query requesting service:reader can immediately skip this fragment.
Locality compaction
Writers receive events spread across the entire lexical space. To make the best use of the sort schema and be able to efficiently prune fragments when serving queries, compactors should generate fragments that are as lexically narrow as possible. This is the role of locality compactions.
Locality compaction works by dividing fragments from a table and time window bucket into individual, exponentially larger “levels.” New fragments that have completed size-tiered compaction enter at level 0. The compaction service uses the minimum and maximum row keys of each fragment to determine which ones overlap. For those that overlap, the compaction service performs a k-way merge of the overlapping fragments, replacing a set of fragments that overlap at that level with fragments that do not overlap.
Each level has a row limit. New data arrives in a level until it grows over its limit. At that point, fragments are selected and “promoted” to the next higher level, and the process repeats.
As the levels increase exponentially in size, while the size of the fragments is held constant, at higher and higher levels, each individual fragment’s minimum and maximum row keys are “closer together” than those at lower levels. There is a higher chance we can prune these high level fragments as the lexical space each one covers is smaller relative to those at lower levels.

In this diagram, the area of each fragment is roughly equal, meaning they contain the same number of events. As the level increases, fragments cover a narrower portion of the lexical space. Larger levels also contain more fragments.
A good description of these sorts of LSM compaction methods is here. As we’ve described in this article, Husky uses what they call a hybrid approach: size-tiering the fragments until they are of a certain size, and then locality-compacting them in a “best-effort” LSM manner to optimize for query execution.
Pruning
But how would we leverage this approach at query execution? We want to exclude or include a given fragment based on whether it could be relevant to a particular query or not. The first way to do this that comes to mind would be to leverage the row keys to see whether, for example service:foo fits within the minimum and maximum row key values. However, this becomes more complicated and less effective the farther the tag is from the “front” of the key.
Instead, we can leverage the observation that, often, the values of common tags are of relatively low cardinality. For example, service may only have tens or hundreds of values in a medium or large system being monitored. The status tag may only have a handful of values (think log level info, error, etc.). And env may just be prod or staging or dev. Even higher-cardinality tags can have regular structure, particularly when machine generated.
Taking this observation, when Husky creates a fragment, it creates a finite-state automaton for each column in the sort schema that can match all the values in the column. This automaton is then “trimmed” to limit the total number of state transitions. This is done in a special way in order to preserve the property that, when a value is presented to the automaton, either:
- It matches, in which case the value could be in the column.
- It doesn’t match, in which case the value definitely cannot be in the column.
This is similar to a bloom filter, or a superset regular expression that matches more than the exact expression, but that doesn’t produce false negatives and is much smaller and faster to evaluate. A mechanical transformation turns the automaton into a regular expression, and this is stored in the fragment metadata in our metadata service.
When a query is run, the metadata for all the fragments in the time buckets that overlap the query range are fetched by the metadata service. Then, the regular expressions in each fragment are evaluated against the relevant query predicates to decide whether the fragment will participate in the query.
So, for example, say a particular sorted fragment contains rows for services compactor,reader,writer. The regular expression generated for the fragment could be ^(compactor|reader|writer)$. For a query that has service:reader, this fragment would match and we’d fetch it and scan it. For a query for service:assigner, we would not.
Interestingly, for a query for service:metadata, we would also not scan this fragment, as metadata doesn’t appear in the service column in any row in this fragment. If, however, we were using just minimum and maximum row keys, we would have scanned the fragment, as metadata lexicographically sorts in the interval [compactor,writer].
So, by dividing rows into separate time windows, merging smaller files into larger ones, and finally by enforcing a “best effort” sorting across the rows, we can effectively limit the number of rows the system must scan for a given query, and the number of fragments the system must fetch for that query.
Conclusion
In this post, we went into details about how Husky’s compactor service tries to find the right “sweet spot” between the global cost of compaction, query latency, and the trade-off between ingest-to-query delay and query cost. In the end, we were able to build a highly efficient system that runs at Datadog scale, compacting thousands of fragments and processing dozens of GB of data every second. Size-tiered compaction is “table stakes” for system operation. By also using locality compaction—conservatively configured to not use more CPU than size-tiering alone—we were able to downscale our pool of workers responsible for running queries by 30 percent when we first rolled it out.

This reduction in turn saves 30 percent of the cost of the most expensive part of our system, which due to its sheer size has material impact on our overall cloud spend. These savings get larger every year as the usage of our system grows. Moreover, the pruning enables large analytical queries that power our products, which wouldn’t be possible otherwise.
This compaction system is an essential part of Husky, preparing data for efficient querying. On top of that, the query system has multiple interesting features, such as methods for hiding object storage latency and avoiding executing the same query twice. But that’s for another blog post. So stay tuned!
If you find systems and challenges like these as fascinating and exciting as we do, we’d love to meet you!
