

We introduced Husky in a previous blog post (Introducing Husky, Datadog’s Third-Generation Event Store) as Datadog’s third-generation event store. To recap, Husky is a distributed, time-series oriented, columnar store optimized for streaming ingestion and hybrid analytical and search queries. Husky’s architecture decouples storage and compute so that they can be scaled independently:
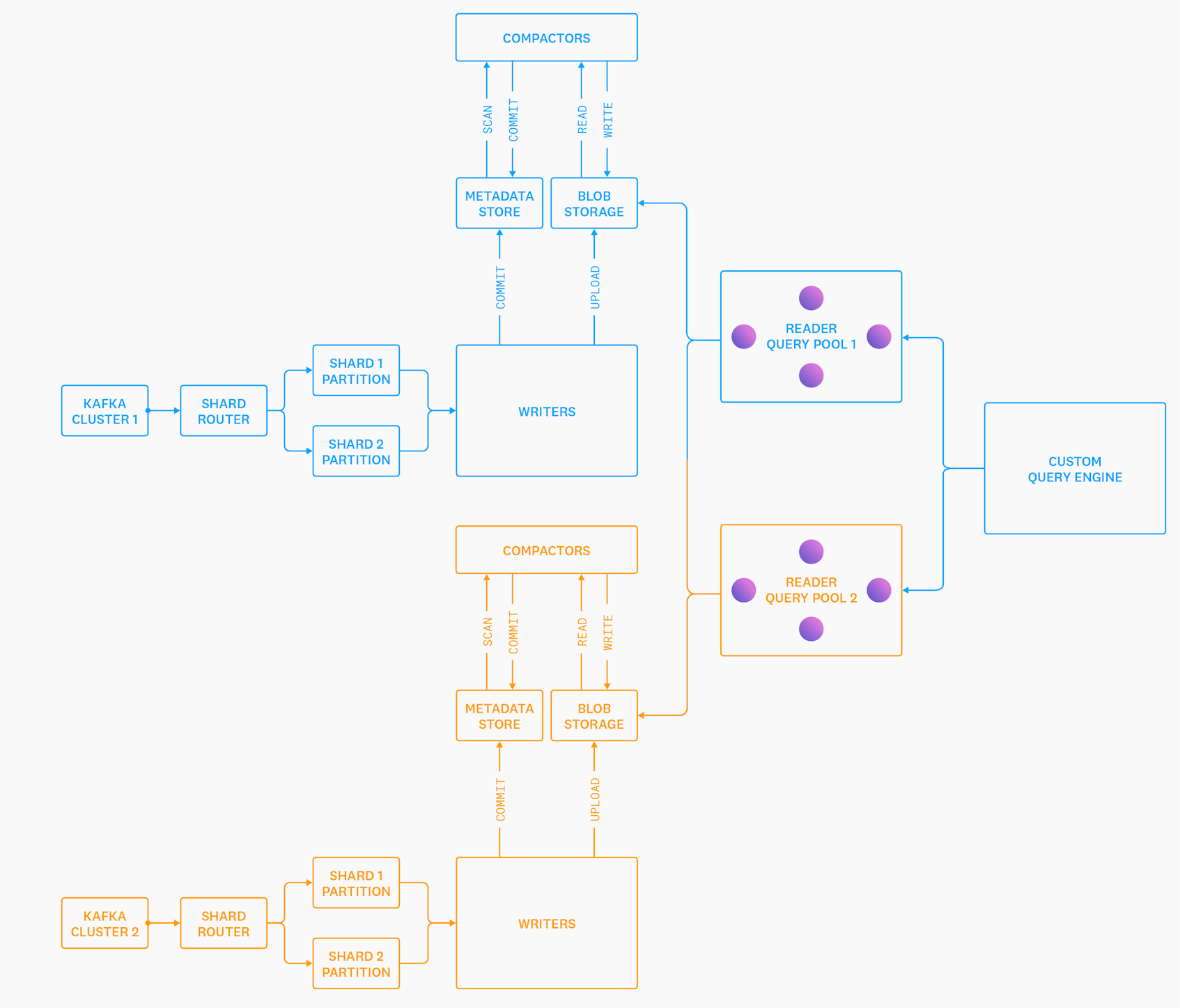
Due to the nature of Datadog’s product, Husky’s storage engine is almost completely optimized around serving large scan and aggregation queries. While it can perform point lookups and run needle-in-the-haystack search queries, it’s not designed to perform point lookups at high volume and with low latency. This design posed a challenge on the ingestion side: how can we guarantee that data is ingested into Husky exactly once, ensuring that there are never duplicate events? At the same time, Datadog is a massive-scale, multi-tenant platform. Our solution would have to work with our existing multi-tenant ingestion pipelines while keeping ingestion latency reasonable and without blowing up costs. It turns out that these challenges are more related than they first appear. In this post, we describe how we overcome these problems to create auto-scaling, multi-tenant data ingestion pipelines that guarantee exactly once ingestion of every event into Husky’s storage engine.
Routing to storage shards
As we described in our previous blog post, when we migrated from our first- to second-generation storage system, we did away with clustering—we replaced large, clustered deployments of a search system with many individual and isolated single-node containers. An important aspect of this migration was minimizing the number of unique tenants and indexes that an individual storage node was exposed to.
We accomplished this with the help of an upstream router service called Shard Router, which introduces a concept of locality into our Kafka pipelines. We introduce locality by deterministically mapping events to groups of partitions we call shards by their ID and timestamp. Without locality, events would be routed randomly.
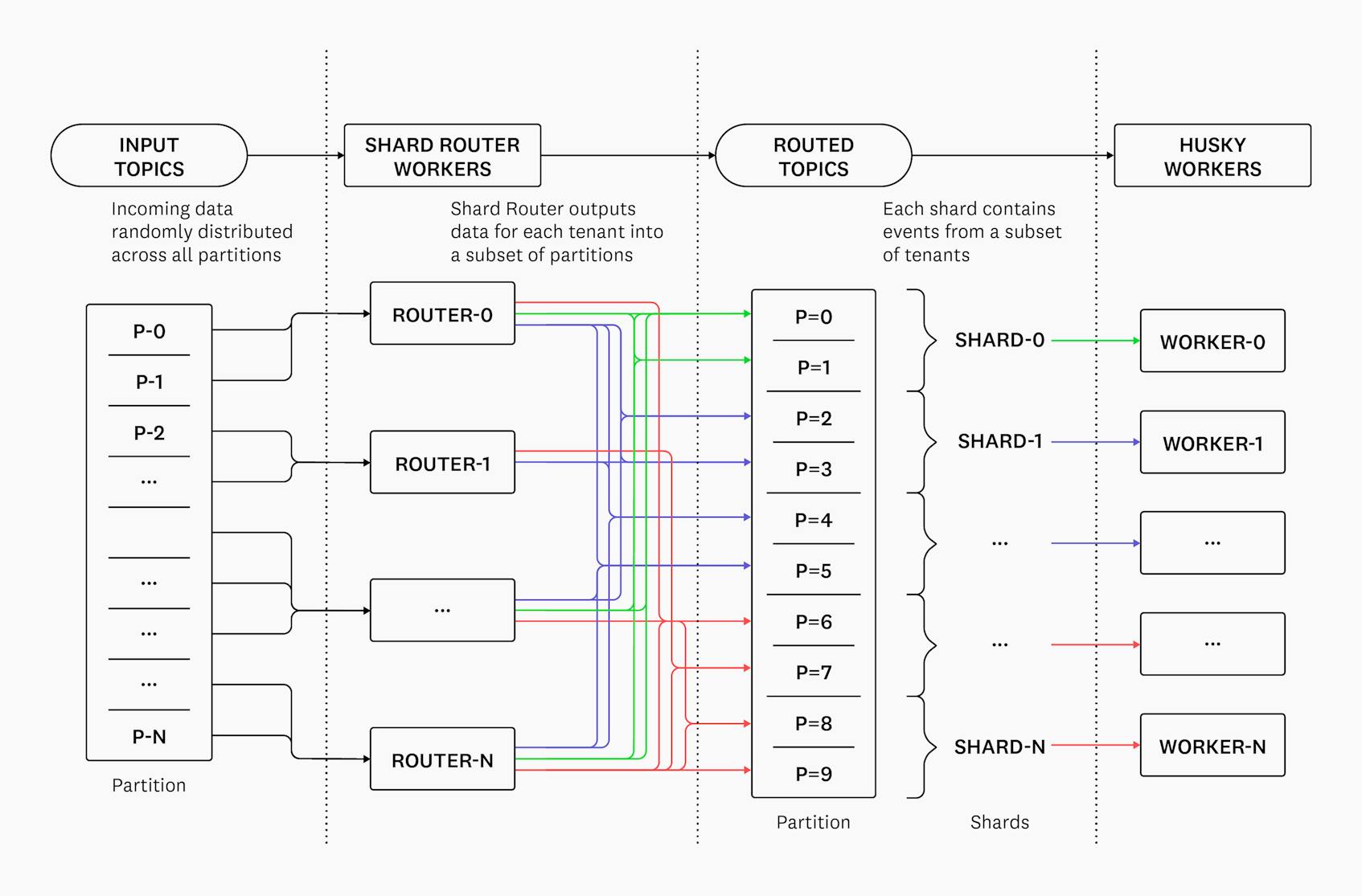
Shard router splits the incoming stream of events into shards for each tenant1. In many routing systems, individual tenants are mapped to a specific shard. By contrast, in our setup, we allocate a list of shards to each tenant, and then deterministically choose a shard from that list for each of a tenant’s events. Essentially: we try to partition each tenant onto a minimum number of shards required, while still trying to keep each shard load-balanced. Downstream workers consume events from one or more shards, and are responsible for exactly-once ingestion into Husky’s storage engine2.
Locality benefits us in a number of ways:
- Ease of deduplication. Events are routed to shards deterministically. Specifically, an event with a given timestamp and ID is always routed to the exact same shard, regardless of when or how often it is ingested. This means that we only need to perform deduplication within a shard. (Additionally, each worker has a smaller set of event IDs than it would otherwise—since these IDs can fit in memory, we can more efficiently perform deduplication.)
- Lower storage costs and better performance. Each shard receives traffic for a (relatively) small subset of tenants. This is important because our storage systems isolate—down to the file level— tenants from each other, using logical namespaces that have non-trivial overhead. Thus, limiting the cardinality of the set of tenants concurrently processed by a worker results in large cost and performance improvements. For example, Husky isolates each tenant’s data into a dedicated table, and we never mix data from different tables in the same file. As a result of this, there is an almost-linear relationship between the number of tenants processed by a Husky Writer node and the number of output files uploaded to blob storage. Since we pay for every file created, having more files leads to increased costs—and introduces more work for the Husky Compactor service.
Of course, introducing deterministic data locality into our Kafka topics wasn’t easy. We needed to ensure that a given event ID would always be routed to the same shard, while still accommodating the unpredictable nature of our customer workloads.
A few of the most challenging problems we had to grapple with were:
- Handling assignment changes. The set of shards that a tenant’s events are routed to may need to change over time—often due to changes in the tenant’s volume of traffic, or changes in the total number of shards available. It’s common for individual tenants to suddenly increase their volume (temporarily or persistently) by one to two orders of magnitude in a short period of time. The set of shards can be changed as a result of a scaling action (adding more shards for a tenant) or a rebalancing action (use different shards for a tenant to balance traffic better).
- Consensus between distributed Shard Router nodes. Specifically, every Shard Router node must always make the same decision about which shard to route a given event to, or we risk introducing duplicate data into the system.
- Load balancing. Each shard should receive a roughly-equal slice of input traffic, so that the ingestion nodes are load balanced.
Handling assignment changes with time-bounded Shard Placements
Given a list of shards and a unique event ID, we can easily come up with a scheme to deterministically map that ID to a particular shard in a cheap and stateless manner:
S = shards[hash(event_id) % num_shards]
As long as each Shard Router knows the set of shards assigned for each tenant, it’s fairly easy to implement consistent and deterministic routing. However, we mentioned earlier how the set of shards that a tenant is assigned to could change over time—because the tenant started emitting ten times as much data, for example. The simple modulo-based algorithm above would break our deterministic routing every time there is a change to the number of shards assigned to a given tenant.
For this reason, we introduce the concept of time-bounded Shard Placements. When we assign a tenant to a set of shards, we make sure that the assignment is only valid for a specific range of time: usually just a few minutes, which is enough to effectively react to environmental updates that might change the ideal set of shards for a tenant. To guarantee deterministic routing, Shard Placements are immutable once they are allocated.
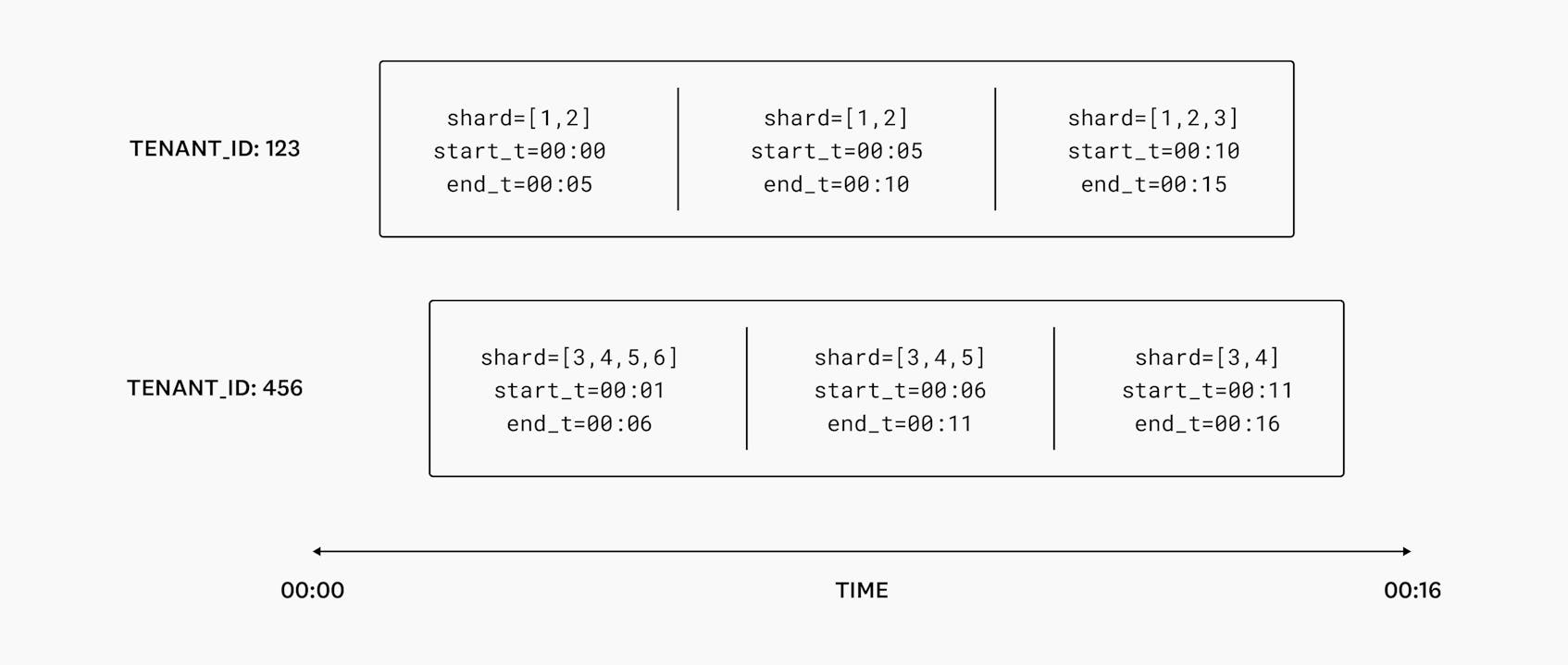
As long as each Shard Router has this history of Shard Placements, it can deterministically route events by first looking up a placement corresponding to an event’s timestamp, and then choosing a shard using the hash modulo approach we mentioned earlier. Each new placement can differ from the last, allowing us to vary the number of shards a tenant is assigned to over time.
Establishing consensus with the Sharding Allocator
To ensure all Shard Router nodes have a consistent view of allocated Shard Placements, we use a central service called the Sharding Allocator. Sharding Allocator implements a simple interface that, given a tenant ID and a timestamp, fetches a placement. This service always returns a placement: if one doesn’t exist already, it is created. More importantly, Sharding Allocator also guarantees that it will always return the exact same placement for any given tuple of tenant ID and timestamp. To accomplish this, Sharding Allocator leverages FoundationDB’s strong transactional guarantees to check for the existence of a placement (and, if it doesn’t already exist, create it) in one atomic transaction.
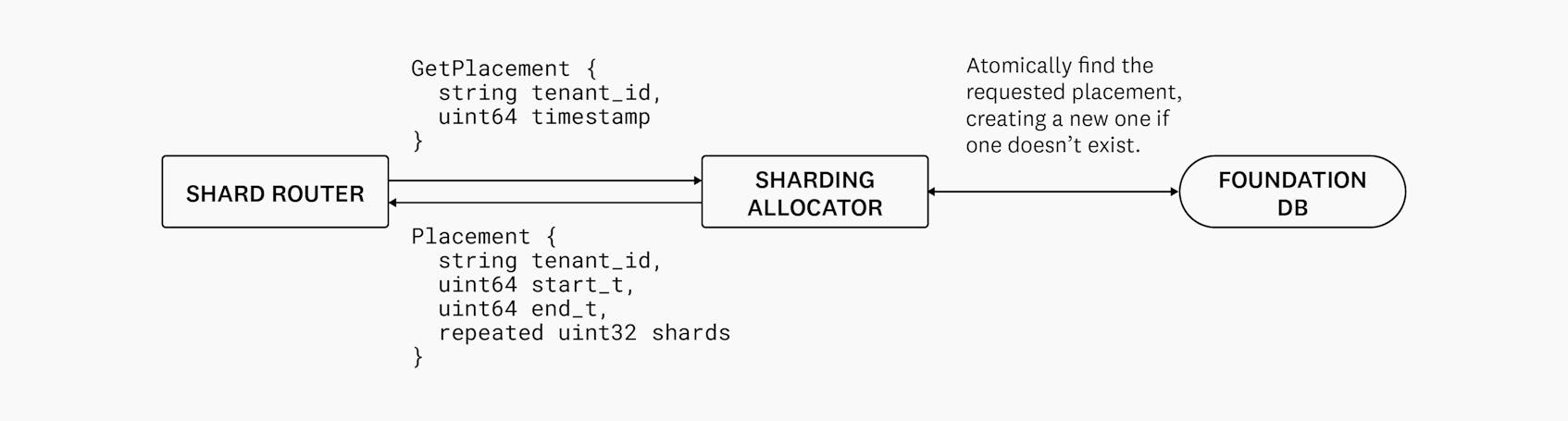
To summarize, Shard Placements are:
- Created for fixed intervals of time.
- Immutable and can never overlap.
- Consistent. A given tuple of tenant ID and timestamp will always map to the same Shard placement.
Sharding Allocator is critical to all data ingestion, so it must be highly available and performant, in addition to being strongly consistent. To satisfy these requirements, Sharding Allocator is itself sharded into multiple isolated deployments, each backed by its own dedicated FoundationDB cluster. We also leverage the fact that placement data is immutable and relatively small, so it can be cached in memory on the Shard Router node to reduce superfluous calls.
Choosing a number of shards for each tenant
How do we choose a number of shards to assign for a tenant’s traffic? The ideal number of shards for a placement depends on the volume of traffic from a particular tenant’s data stream.
So, if we knew the traffic patterns of each tenant in real time, we could make adjustments to a tenant’s shard counts in response to changes in traffic volume.
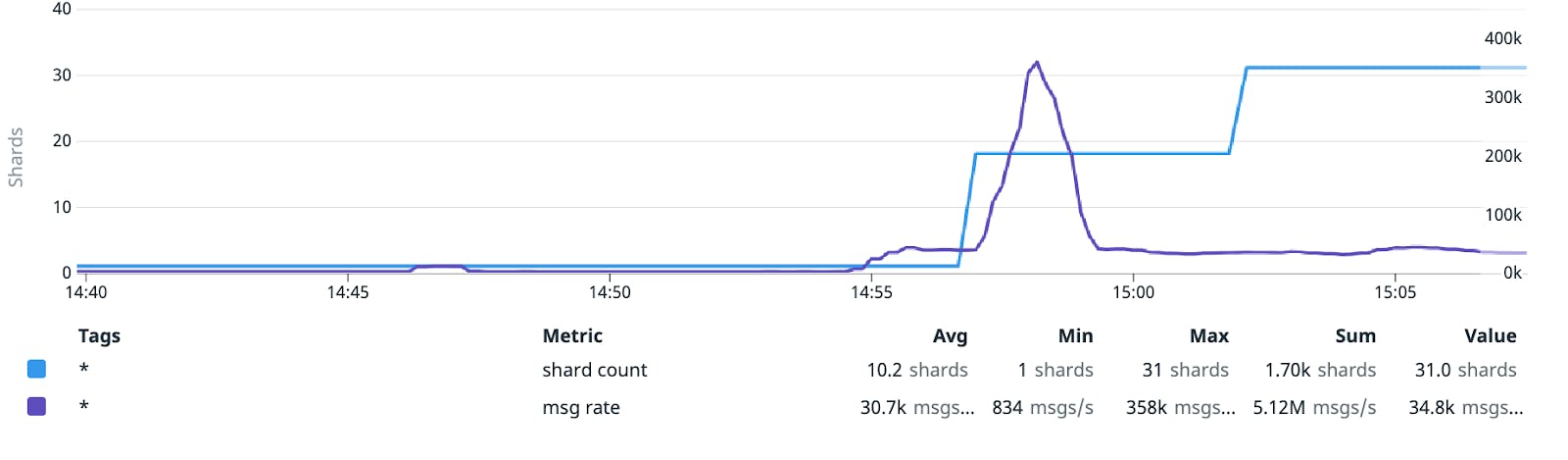
As Shard Router does its work of routing messages to the right downstream shards (groups of partitions), it also continuously publishes throughput data (in the form of Datadog metrics) for each tenant—and if metrics are unavailable, we can keep running by referencing the existing shard count. In our experience, the total number of bytes ingested is a much better predictor of ingestion cost than the number of events, as events can vary dramatically in size. Hence, the “cost” metric that we publish is based primarily on the total number of bytes emitted by the tenant.
The aptly-named Autosharder service periodically fetches those metrics and adjusts configured shard counts on a tenant-by-tenant basis to better fit observed traffic volume. An updated shard count takes effect when the next Shard Placement is allocated. The shard count for each tenant is stored alongside other tenant metadata that is needed on the write path.
How does the Sharding Allocator choose shards?
Sharding Allocator’s job when creating a new placement is basically to choose n shards from k possible ones, where n is the tenant’s shard count (as decided by the Autosharder) and k is derived from the number of partitions in the topics currently being used.
Sharding Allocator has a few constraints that it must keep in mind:
- Sharding Allocator must be fast, reliable and have minimal dependencies.
- We want to minimize shard changes between consecutive placements for the same tenant. For example, if the Shard Router asks for five shards for one interval and six for the next, the ideal placement would reuse the same five shards as the previous placement and add one shard. The same requirement applies when there are changes to the total number of shards – ideally, if we’ve chosen five shards from 100, we should later choose the same five shards when there are 101 shards to choose from.
- It is sometimes useful to exclude shards. We should be able to skip shards that have been marked as excluded—for example to help a lagging consumer catch up.
This sounds like a great application for a consistent hash function. Fortunately, a number of performant consistent hashing algorithms exist for this use-case. Using one might look something like this:
H(key, numBuckets) = bucket
We allocate Shard Placements by tenant, so our key is the tenant ID. Applying a hash function in the following way can give us the first of n shards.
H(tenant_id, totalShards) = tenantShard
To choose our n shards, we add the subsequent n-1 shards, skipping the list of excluded shards, to get our final list of shards. The resulting placement should adhere to all of our previously described constraints:
- Changes in the total number of shards do not result in major changes for Shard Placements.
- Changes in the tenant’s shard count do not result in major changes for Shard Placements.
- When a shard is excluded, it only results in one relocated shard for placements that contain the newly excluded shard.
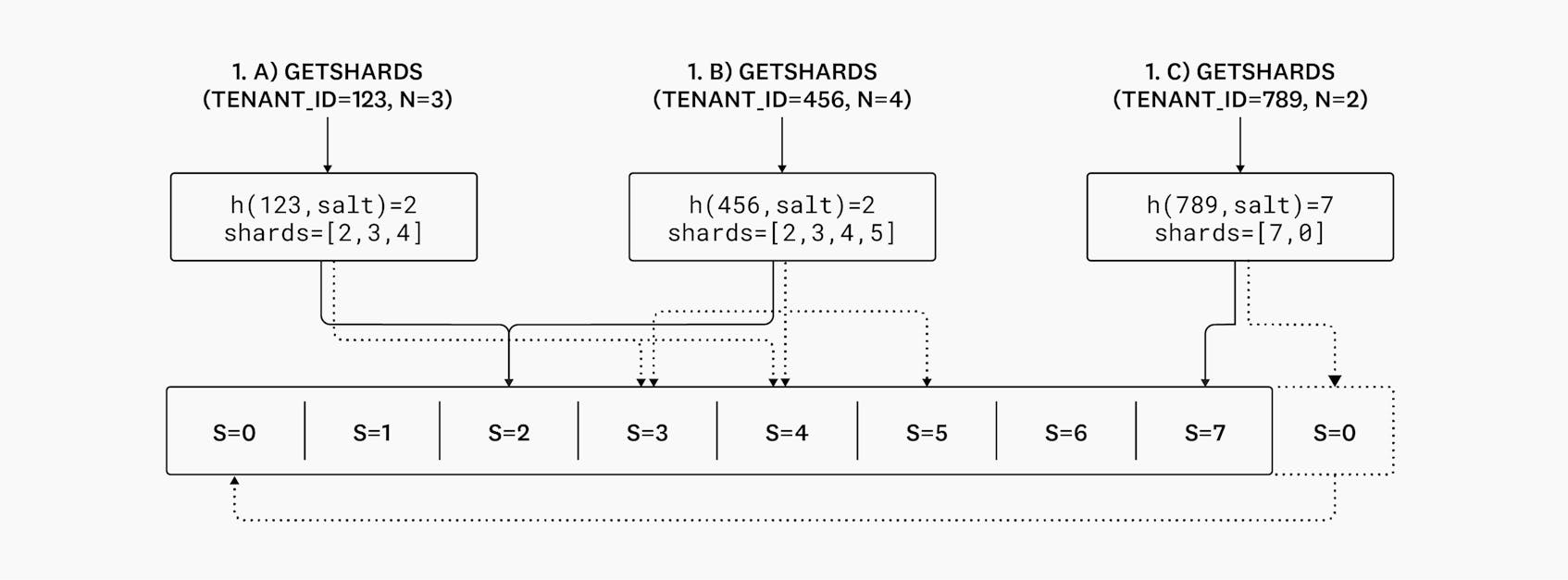
1.a) Tenant “123”, with shard count 3, is hashed to an initial shard ID of 2. Since the shard count is 3, they are assigned shards 2, 3, and 4.
1.b) Tenant “456” has the same initial shard ID as tenant “123”, but has a shard count of 4. Since the shard count is 4, the tenant is assigned shards 2, 3, 4, and 5.
1.c) If the consecutive shards would go beyond the maximum number of shards (as defined by the topic partition count), they simply wrap around to the beginning. Here, tenant ‘789’ with shard count 2 has an initial shard ID of 7. 7 is also the highest shard—so we wrap around, and the tenant is assigned shards 7 and 0.
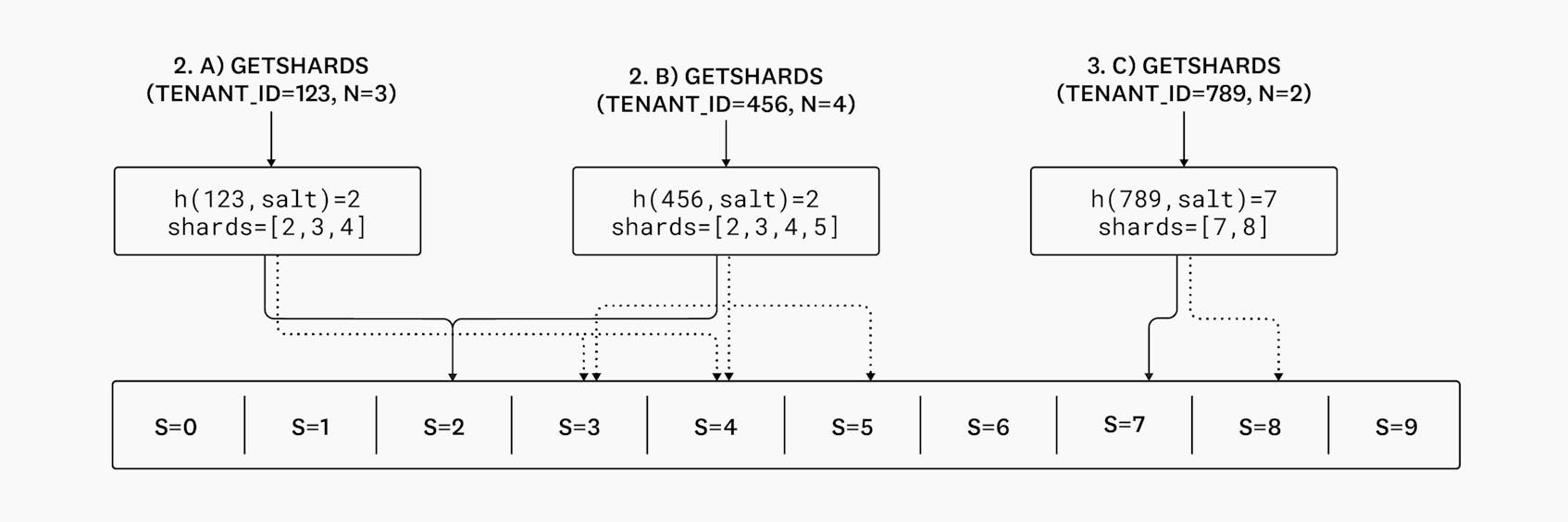
2.a) and 2.b) The assigned shards are identical, since the hashing function has ensured that the initial shard ID didn’t change, and the salts remained the same.
2.c) Here, the assigned shards changes from [7,0] to [7,8] since we no longer need to wrap around to accomodate these shards.
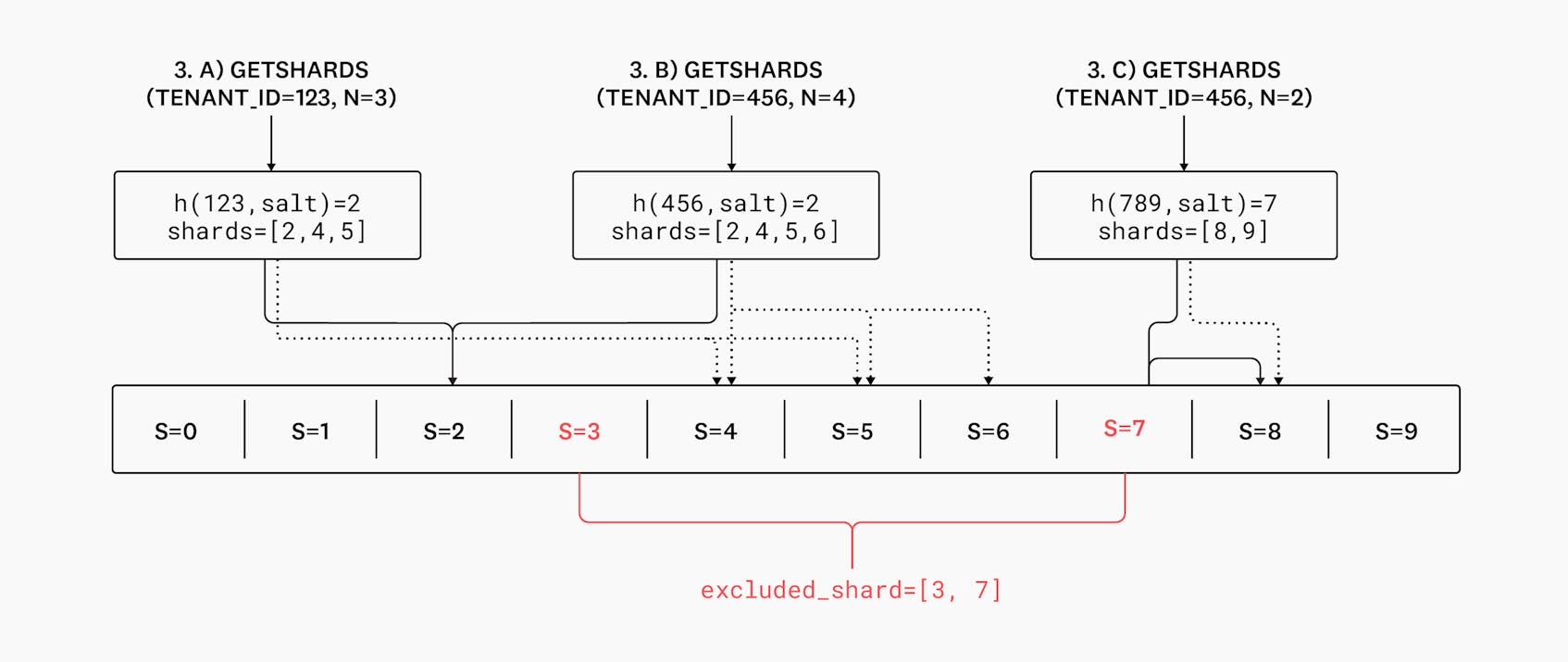
3.a) The assigned shards for tenant “123” would have been [2,3,4] but—since shard 3 is excluded—the tenant is assigned shards [2,4,5].
3.b) Similarly, [2,3,4,5] becomes [2,4,5,6].
3.c) And finally, since shard 7 is excluded, tenant “789” is assigned shards 8 and 9 instead of 7 and 8.
Load Balancing with the Sharding Balancer
Sharding Allocator’s consistent hashing scheme outlined above has one flaw: although hashing algorithms typically yield uniform distributions over keys, this is not sufficient to ensure that the total volume of traffic routed to each shard is roughly equal. Hotspots can occur randomly—even relatively small hotspots can result in large amounts of consumer lag for a given shard if the hotspot is long-lived.
Additionally, the hash function gives us our first shard for a tenant, but we’ve opted simply to use neighboring shards to choose the rest of a tenant’s shards. This means Shard Placements for different tenants can easily overlap, creating imbalances.
To alleviate these issues, we periodically run a balancing algorithm that shifts tenant Shard Placements around, until all shards are roughly balanced. Unfortunately, a consequence of using the tenant ID as the key for the hash function is that we are left without the ability to change the index of the first shard for a tenant. To address this, we introduce a salt value that is calculated for each tenant ID and is used as part of the hash function key. Changing this salt value allows us to offset the shards chosen for a placement, even if everything else remains the same.
$H(\text"tenant_id" + \bo{\text"salt"}, totalShards) = tenantShard$
If we persist this salt value and use it whenever allocating a Shard Placement, we can shift future Shard Placements of a tenant by modifying the salt.
Now that we’ve established how we can salt our key to shift Shard Placements, we need to come up with an actual algorithm that can correct unbalanced shards by shifting placements around.
First, let’s define what “unbalanced” means. In simple terms, it just means that some shards are receiving a lot more traffic (with regards to our cost function) than others. In mathematical terms, we can use the formula for population variance and apply it to observed values of the same per-shard throughput metric that is used by the Autosharder to tweak shard counts:
$σ^2 = ∑↙{i=0}↖N {(X_i - \ov{X})^2}/N$
$X_i =$ the observed traffic volume/cost sent to the ith shard,
$\ov{X} = $ the mean of the observed traffic volume across all shards,
$N = $ the total number of shards
Population variance is a commonly used measure for determining how spread out population data is. In our case, it works well as a metric for how unbalanced our shards are.
Having defined what it means for traffic across shards to be unbalanced, we can come up with a balancing strategy:
- Calculate population variance. If it is above a threshold, proceed to step 2.
- Pick the list of tenants whose current Shard Placements include the shard with the maximum observed throughput.
- Simulate moving those tenants to some shards with the lowest observed throughput, and recalculate the population variance each time. Choose and apply the move that yields the lowest simulated variance.
- Repeat steps 1-3 as needed, or as many times as allowed—the balancer is configured with a maximum number of moves it can make on each run to minimize placement moves.
The balancer is tuned to make the most impact with the fewest actual changes. This is not only to minimize routing changes, but also because we’ve observed that this works best – especially in the case of massively multi-tenant clusters, where significant imbalances rarely occur, or are limited to one or two outliers.
Accommodating bursts in traffic
Shard Placements are immutable, have a fixed set of shards, and apply to a specific tenant and range of time. Therefore, it is possible for a tenant with a small number of allocated shards to sharply increase its traffic during the range of time for which the placement applies. A sufficiently massive influx of traffic to a small number of shards has the potential to overload the associated workers, leading to ingestion lag.
Typically, a couple of automated mechanisms can mitigate the impact of bursts in traffic:
(Auto) upscale
Shards are sized to be small enough so that each writer is generally assigned several shards at once. The impact of processing an influx of traffic will manifest itself in increased values of vital metrics like CPU usage. The Watermark Pod Autoscaler observes these metrics and quickly upscales when observed values cross a threshold. Increasing the number of workers decreases the number of shards assigned to each, which in turn increases the maximum potential throughput of each shard. In other words, if a Writer was previously assigned ten shards, and is suddenly only assigned five, it can now process approximately twice as many events per second from each remaining assigned shard.
Shard Exclusions
Shards that are overloaded due to a large spike in traffic can be temporarily excluded. Excluding a shard means that it won’t be included in future Shard Placements, so that eventually, new traffic won’t be routed to it. In extreme situations, this can allow the shard to recover from a large backlog.
Husky Writers
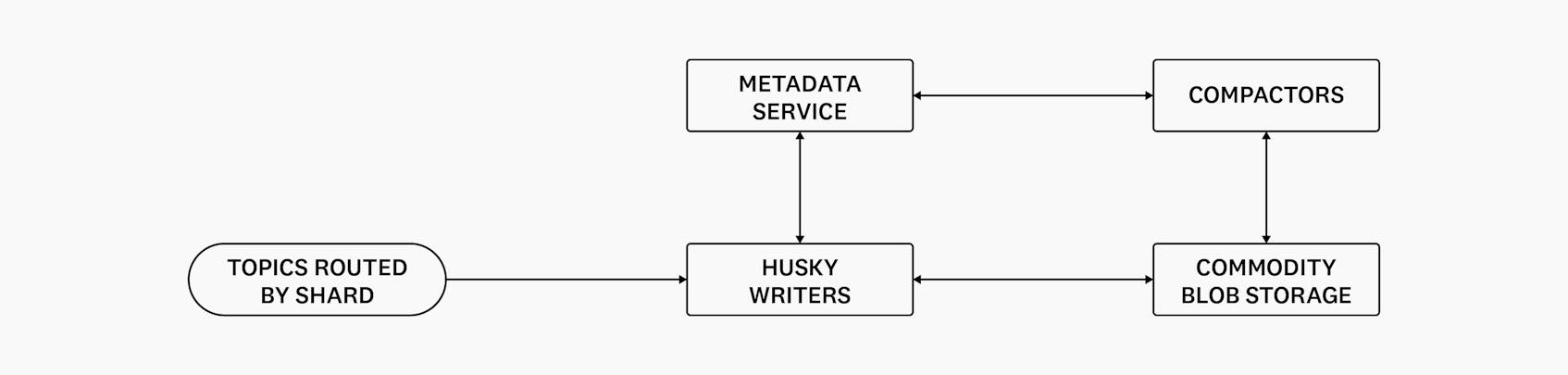
Until now we’ve discussed the storage routing system upstream of the workers responsible for exactly-once ingestion to a Husky deployment. This system enabled us to abandon all notions of clustering at ingestion time as we moved from our first-generation to our second-generation storage system, and is reused with our third-generation system, Husky. These days, the primary consumer of the Shard Router’s output is a Husky service called the Writers, which we introduced in our previous blog post. The Writers’ primary responsibility is reading events from Kafka, generating Husky columnar format files in blob storage, and committing the presence of those files to FoundationDB.
Much like their second generation counterparts, Husky Writers consume events from assigned shards. A Writer’s primary task is to persist these events with the goal of making them queryable as quickly as possible without introducing any duplicates.
There are also a couple of other requirements based on foreseeable issues:
- As we learned from the previous system, the Writers nodes themselves should be stateless—and we should be able to auto-scale and spread shard assignments across Writer workers as needed.
- Minimize number of files uploaded to blob storage. This is important because:
- The number of files (objects) created is an important cost dimension of commodity object storage – we need to make sure our costs don’t spiral out of control.
- We also need to make sure the blob storage bucket can handle our request volume (and avoid getting rate-limited).
- Having fewer files decreases the amount of work the compactors need to do, and makes queries more efficient.
- We need to minimize disruptions from worker restarts, including from deployments.
Stateless deduplication
The implication of stateless Writers is that the shards that a Writer is assigned can change. This means that other workers can (temporarily) receive events from the same shard, which can result in duplicate events across workers—in addition to the duplicate events within a single shard. So how do we perform deduplication?
Here are a couple of naive solutions that won’t work:
- Simply querying Husky for the event ID to see if it has already been written would be massively inefficient. Husky is optimized for search and aggregation, but not low-latency point lookups, and especially not at the high throughput that our data ingestion pipelines operate at.
- We can’t simply store all seen IDs in memory because they will not fit in memory. Besides, this doesn’t help us handle restarts or reconcile duplicates/conflicts that will invariably occur when two writers temporarily process the same shard during deployments and node restarts.
We need some sort of persistent store3 for event IDs from which we can retrieve and look up IDs efficiently. Two obvious candidates:
- Use an embedded local key-value store like RocksDB. This would certainly be efficient, but it would also ruin the stateless nature of the Writer nodes.
- Use a remote key-value store like Redis or Cassandra. This could work well, but it adds an additional dependency and could make it difficult to allow deduplication over large time windows, such as months or years.
Both of these solutions suffer another problem: they split consistency and correctness between two sources of truth. Husky is designed with a single source of truth – the Metadata store (backed by FoundationDB). An event exists if it has been committed there, and does not if it hasn’t. Using an additional store adds the complexity of reconciling disagreements between two systems: What if we were able to commit event IDs to Cassandra, but we failed to commit the event data itself to the Metadata store?
Storing IDs in Husky
We opted for a hybrid approach to storing IDs: we persist the event IDs in Husky itself, but we store them in separate Husky tables from the raw event data. This solves our two biggest problems in one fell swoop:
- IDs and event data are committed to the Metadata Service at the same time (and in the same FoundationDB transaction). As a result, it is not possible for there to be a discrepancy between committed IDs and committed data.
- Event data is stored in regular tables. ID data is stored in ID tables, which are unique per shard ID and partition files by time. This ensures that the Husky Writers can page in huge swathes of IDs for the shards that they’re consuming from blob storage using a very limited number of IO operations.
For fast lookups, event IDs are also stored in memory, and we lazily page in intervals of event IDs from Husky as needed. When the in-memory structure gets too large, we purge unneeded intervals with the help of an LRU (least recently used) cache.
This is an elegant solution for several reasons:
- Metadata remains our single source of truth. We commit tenant event data and event IDs in the same atomic transaction: thus, we can guarantee consistency between the event data itself and the event IDs once they’ve been committed to the Metadata store.
- Husky is designed to store vast amounts of data for long periods of time, so we can store all event IDs for as long as we need.
- The event ID tables are just regular Husky tables, so the Compactors automatically optimize them for reads (page in by the Writers), just like they do for all the other “regular” event data tables. In addition, these ID tables can have time-to-live configuration, just like any other table in Husky, and automatically expire after a configurable amount of time.
When a worker is restarted (or receives a new shard assignment), it must page in many intervals of event IDs, as it has none in memory. In practice, since observability data tends to arrive roughly ordered in time, the page-in rate is several orders of magnitude lower than a Writer’s actual rate of ingestion. Regardless, the Writers can page in IDs at a rate ~2 orders of magnitude higher than they can process incoming events.
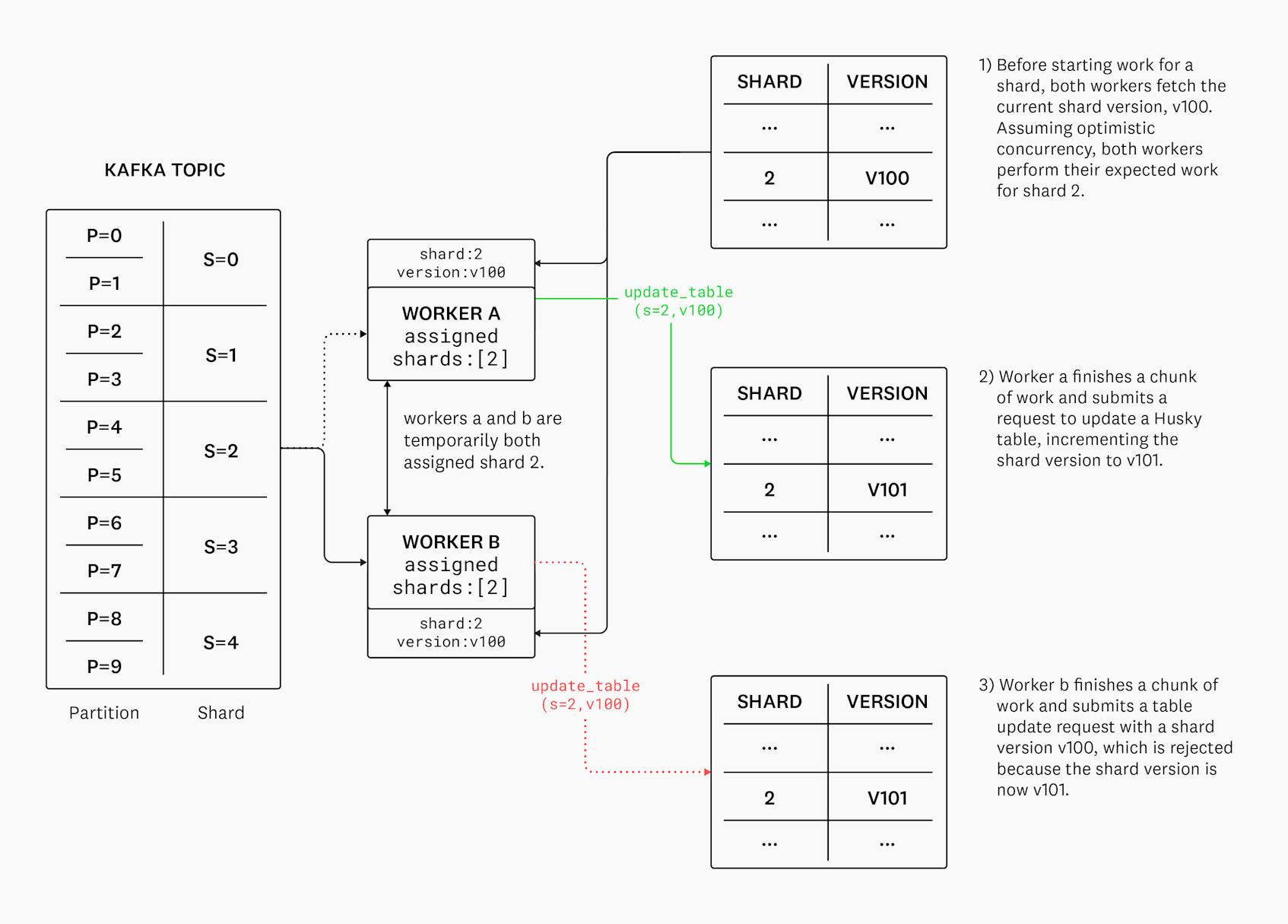
Conflict detection
What happens when a shard is reassigned to another worker? Does it break deduplication because both workers have diverging sets of event IDs for the same shard and interval of time? What if something goes wrong and a shard assignment ping-pongs between multiple different Writers?
Once again, we leverage FoundationDB’s strong transactional guarantees to achieve distributed consensus in the critical path. Husky’s Metadata Service is backed by FoundationDB, so we leverage its strong transactional guarantees to implement a conflict detection scheme based on optimistic concurrency – we simply version updates to the event IDs tables and reject out-of-order updates. The worker is notified of the conflict and triggers a reconciliation process – the contents of the local ID cache are discarded and consumer progress is reset to the latest committed fragment.
What’s next?
Here we reviewed how immutable yet dynamic upstream routing combined with a FoundationDB-powered conflict resolution mechanism make it possible for us to ingest and de-duplicate vast multi-tenant streams of data into Husky while maintaining that every piece of the ingestion path is stateless, scalable, and performant. Future posts in this series will cover interesting technical details of Husky’s compaction system and the query path.
Abstracting topic partitions into shards allows us to scale Kafka resources independently of shards, as well as to introduce some redundancy. Multiple partitions across multiple topics across multiple clusters can map to the same shard. This enables us to tolerate degraded performance and failures of brokers, entire topics, or even entire Kafka clusters with some clever client-side load-balancing as Shard Router publishes events. ↩︎
While it may seem trite to care about exactly once ingestion for an Observability system, it’s actually an incredibly important property for us to maintain. Introducing a single duplicate event into the system is sufficient to cause false positive or false negative monitor evaluations for our customers, which we consider unacceptable. Upstream services can introduce duplicate events in a number of ways during normal operation—retries, service restarts, network blips, etc. Last but not least, exactly-once processing is crucial for accurate usage reporting for billing and cost attribution. ↩︎
Another way some database systems handle de-duplication is by writing the duplicates, filtering at query time, and finally pruning at compaction time. With Husky, we can get away with not doing this because a) the majority of the data is not updated, so entire files are rarely re-written; and b) the write volume is much higher than the query volume. ↩︎
