

When Codiga joined Datadog last year, we integrated our static analyzer product with Datadog’s infrastructure to release Datadog Code Analysis. Codiga’s static analyzer was written in Java and supported code analysis for Python, JavaScript, and TypeScript. It initially used ANother Tool for Language Recognition (ANTLR) for generating an abstract syntax tree (AST) of each language supported by the product.
Shortly after the acquisition, we worked to expand support to additional languages, but ran into two major issues:
- With our existing tools and flow, some languages were only partially supported
- Parsing was slower than we needed it to be, especially since analysis time compounded on larger repositories with thousands of files
To our surprise, these shortcomings were quickly addressed by migrating from ANTLR to Tree-sitter, a popular parsing library to parse source code and build its tree. We found that Tree-sitter has a vibrant open source community that contributes to many languages in full, and that parsing code with it is much faster because the grammar is implemented in C. However, Tree-sitter support of Java was limited at the time - it had the most robust support for C and Rust.
We found ourselves at a fork in the road: should we continue with a static analyzer in Java, trading performance for predictability, or take the risk of a costly and possibly failed rewrite to Rust in hopes of making static analysis much faster?
In this blog post, the first in a series that explores the technical challenges and decisions behind our static analyzer, we’ll cover:
- Why we chose to optimize for performance
- The architecture of the Datadog static analyzer
- The benefits of migrating from Java to Rust
- Our experience learning Rust for an efficient migration
An initial tradeoff between control and performance
Let’s start with an important difference between Codiga and Datadog:
At Datadog, users natively run the static analyzer on their own CI instance, which sends the results to Datadog. This approach gives customers more control over the execution of the static analysis process, which has major advantages in terms of security and performance. But it can also become a significant problem in CI environments that are restricted in resources. For example, when using a GitHub Actions runner sized at two cores and 7 GB of RAM, we struggled to get the analyzer to scan fast enough - medium-sized repositories (a few thousand files) should be fully scanned in less than three minutes, but instead, it took five with Datadog.
At Codiga, most of our analysis tools were already running on large instances. The analysis was processed on our servers: developers could trigger a push on their repository and the analysis would automatically be done for them. When we operated our static analyzer at Codiga, we controlled its execution and could allocate resources as needed. We also had the execution environment and the underlying JVM fine-tuned to squeeze the most performance from our existing infrastructure.
In addition, Codiga’s analyzer required a recent Java Virtual Machine (JVM 17+). This was a new configuration constraint, and customers may already have had a JVM in their CI environment that could have conflicted with the one used to run our static analyzer.
Thus, continuing with the static analyzer in Java presented a number of unpalatable drawbacks for customers: none were impossible to overcome, but all solutions presented limited upside. Should we push forward or take a different route altogether?
To answer this question, we need to understand how the static analyzer works.
Architecture of the Datadog static analyzer
Our static analyzer is architected in layers. The main components are the parsing part that builds the abstract syntax tree (AST), and the execution part that manipulates the AST, reports code violations, and offers fixes.
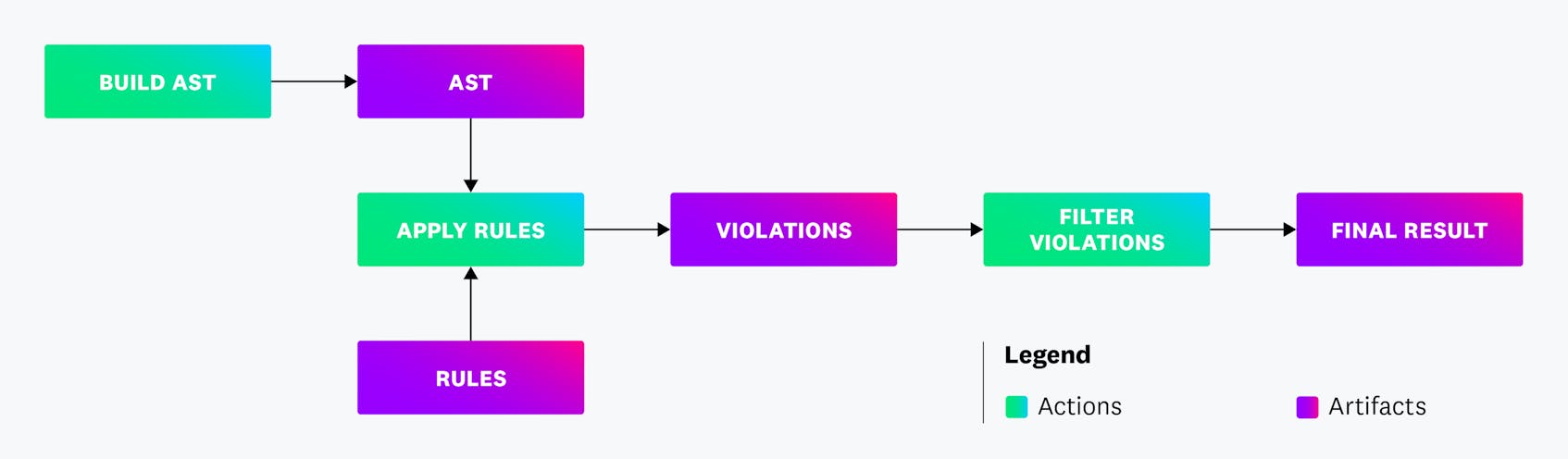
These two components of the analyzer rely on third-party dependencies:
- AST build: To build the AST, we use Tree-sitter. There was an initial Java library for Tree-sitter, but it was limited in functionality. (For example, it did not support Tree-sitter pattern matching, which is mandatory for optimizing the speed of the analyzer.) The Tree-sitter core libraries are implemented in Rust.
- JavaScript execution: Our static analysis rules are written in JavaScript. In order to execute these rules, we need a JavaScript runtime to execute the JavaScript code of our rules. The JavaScript execution layer was implemented using the polyglot features of GraalVM.
From a user experience perspective, we wanted the analyzer’s speed and performance to be optimized to run scans as quickly as possible. This is why we placed an emphasis on Tree-sitter’s pattern matching and fast rule execution.
From Java to Rust
Why Rust? Out of all the alternatives to the existing Java implementation of the analyzer, Rust made the most sense given our dependency on Tree-sitter and its level of support for Rust.
A successful migration from Java to Rust would mean that we could migrate all features while maintaining feature parity. We established a set of tests that would verify the migration was working: a scan with the new Rust version had to produce the same results as its predecessor in Java. This meant that the same program would produce the same violations when scanned by both versions, and the execution time of the new version is at least as fast as the old version (no performance regressions).
Migrating the parser component of our analyzer was the easy part. Rust is a first-class citizen in the Tree-sitter ecosystem; using the Rust library of Tree-sitter brought everything out of the box. From this perspective, migrating from Java to Rust was even better for us because we did not need to maintain our own Java library for Tree-sitter.
This migration not only enabled a seamless integration of Rust and Tree-sitter features, but also enhanced our static analyzer’s overall performance. We observed that the migration tripled our performance and resulted in a tenfold reduction in memory usage, which is crucial for optimizing operations in resource-constrained environments like CI systems with limited RAM and CPU resources.
For the JavaScript runtime used to execute the code for static analysis rules, we migrated from GraalVM to deno. Deno is a simple JavaScript runtime library integrated in Rust powered by v8. We only integrated the deno-core crate that included the JavaScript support without the underlying runtime. We did this for security reasons: static analysis rules need to execute JavaScript code but do not need to do any operation on disk nor communicate over the network.
Other components of the analyzer had to be migrated as well. The following table summarizes the mapping between each core function and the library used to implement it in Java or Rust.
| Function | Java Library | Rust Library |
|---|---|---|
| Building AST | Tree-sitter (custom library) | Tree-sitter (vanilla support) |
| Parsing YAML | snakeyaml | serde_yaml |
| HTTP client | JVM standard classes | reqwest |
| Concurrent execution | Java Future framework | rayon |
Learning Rust for an efficient migration
Datadog Static Analysis was our first Rust project, so we planned for what we expected to be a large undertaking. Not only did we need to migrate our codebase, but we needed to learn Rust from scratch. The initial plan accounted for three months for learning Rust and migrating the entirety of our static analysis tooling from Java to Rust.
Going by our previous experiences, we had planned to give ourselves at least a few weeks to become familiar with new concepts (such as the borrow checker) and understand how we would map the existing codebase onto Rust concepts. To our surprise, we gained a firm grasp of the language and a clear idea of how our codebase would be mapped onto Rust within 10 days.
Migrating the entire codebase happened even faster than we had anticipated. Within a month, the entire code analysis infrastructure was migrated from Java to Rust, and all customers were running on the new Rust analyzer.
During the process, the hardest part for us was to clearly understand the following concepts:
- The Copy trait vs. Clone trait and when to explicitly clone a value. The Rust ownership feature prevents memory errors and requires an understanding of how values are assigned and copied. Understanding the copy and clone trait are very important if you want to write efficient Rust code.
- The borrow checker and passing references instead of passing the value. We copied values across function calls too often. In the majority of these cases, we could have simply passed a reference value and avoided any cloning.
- Parallelization and concurrency. The rayon library simplifies a lot of operations and prevents developers from implementing their own concurrency mechanisms.
Once we understood these new concepts, we found that the Rust ecosystem is really efficient. From IDE plugins to CI/CD integration (available directly as GitHub actions), there are a lot of tools that help you write efficient Rust code.
What helped us the most was to adopt strict coding standards from the beginning:
- Linting (rust-clippy) and code formatting (rustfmt) checker at every push
- Adding unit and integration tests as much as we could to prevent any regression
- Checking all tests using a pre-commit push and in our CI/CD pipeline
While having strict guidelines from the beginning made the learning curve steeper (especially because every code style issue detected by rust-clippy and rustfmt had to be addressed before committing our code), it ensured that we maintained high code quality and prevented any performance regressions that could have impacted our customers.
Enhanced performance in the IDE
As we mentioned above, our internal tests showed that after migrating, on average, analysis time for a repository had been reduced by a factor of three, which means developers now had faster feedback on their pull requests and platform teams reduced compute time spent in their CI environment.
In addition, the new static analyzer is available as a binary and does not need the JVM to run, which reduces setup time on every commit. For example, there’s no need to install a JVM in the CI environment before running the analysis, which saves multiple seconds at every CI run.
Removing our dependency on the JVM and speeding up the analysis enabled us to embed the analyzer directly into the IDE. The very same lightweight and fast analyzer that runs in your CI/CD pipelines simultaneously reports coding errors and suggests fixes in your IDE in real time, tightening the feedback loop for the quality and security of the code you’re writing.
What’s next
If you’re considering migrating your codebase to Rust like us, we advise starting with smaller, non-critical components of your system to become familiar with Rust’s syntax, tooling, and compilation model.
As the Rust ecosystem continues to grow, we’ve found that specialized tools and libraries needed for Java are not as readily available in Rust. This required us to explore alternatives and invest in developing in-house solutions.
In our next post, we will discuss our experiences within the Tree-sitter ecosystem, detailing our contributions and our collaborative efforts with the open source community.
Excited about high-performance Rust? Datadog is hiring.
Resources
- Initial Datadog static analyzer (Java version)
- Current Datadog static analyzer (Rust version)
