

What is EC2?
Amazon Elastic Compute Cloud (EC2) is a core component of the Amazon Web Services platform that provides scalable cloud-based computing capacity. Similar to other IaaS offerings, such as Microsoft Azure VMs and Google Compute Engine, EC2 enables users to provision compute resources in the form of virtual servers called instances. Instances are available in a range of types, which provide different CPU, memory, storage, and networking capacity. And EC2 offers a wide variety of standard and custom templates—stored as Amazon Machine Images (AMI)—that have various Linux-based or Windows operating systems and software configurations.
EC2 instances allow users to increase or decrease resource capacity within minutes, and the ability to launch instances in specific parts of the world means you can match regional demand. EC2 can be integrated into other AWS components and features, including Auto Scaling, which automatically launches or stops instances to meet the demand on your application. Instances running applications in Docker containers can be grouped into clusters and managed by Amazon’s EC2 Container Service (ECS) or ECS for Kubernetes (EKS). You can also easily attach Amazon Elastic Block Store (EBS) volumes to new instances for persistent block-level storage, and many instance types can be optimized for EBS to provide additional performance.
What to look for with EC2 monitoring
Regardless of the configuration of your individual instances, you will want to monitor basic system-level metrics to keep an eye on the health of your core infrastructure. You will also want to track how well your resource capacity matches demand. Available EC2 metrics generally fall into three types:
In addition to these resource metrics from EC2, you also have access to binary status checks, which report the health of your instances and the AWS systems they are hosted on. And, you can track scheduled events that might affect your instances’ status or availability.
Amazon’s CloudWatch monitoring system is the easiest way to see most resource metrics for your EC2 instances and other AWS services, with a few things to keep in mind. First, by default CloudWatch uses basic monitoring, which only publishes metrics at five-minute intervals. You can enable detailed monitoring when available to increase that resolution to one minute, at additional cost. Second, some metrics have nuances specific to EC2 instances, which we will cover below. Third, AWS separates most resources by region, so you can generally only view CloudWatch metrics for instances within a single region at a time. And finally, CloudWatch does not expose metrics related to instance memory. We will explore some other methods for collecting memory metrics in the second part of this series.
This article references metric terminology introduced in our Monitoring 101 series, which provides a framework for metric collection and alerting.
Disk I/O metrics
There are two primary kinds of block-level storage volumes attached to EC2 instances: EBS volumes and instance store (ephemeral) volumes. Instance store volumes are physically attached to the host computer the instance runs on. This means that their performance levels are more predictable than EBS volumes, which might be splitting hardware resources among multiple tenants. But, all data on instance store volumes is lost when the instance is stopped or if the disk fails (hence “ephemeral”). EBS volumes, on the other hand, provide persistent storage. Note that many instance types do not support instance store volumes.
Both EBS and instance store volumes can be in solid-state drive (SSD) or hard disk drive (HDD) format. The number, capacity, and performance of these disks differs based on the instance type and volume configuration, so monitoring EC2 disk I/O can help you ensure that your chosen instance type’s disk IOPS and throughput matches your application’s needs.
CloudWatch’s main EC2 disk I/O metrics only collect data from instance store volumes. CloudWatch does offer a set of EBS disk I/O metrics within the EC2 namespace, but these are only available for C5 and M5 instance types. For all other instance types, disk I/O for EBS volumes must be monitored via CloudWatch’s EBS metrics.
| Name | Description | Metric type |
|---|---|---|
| DiskReadOps/DiskWriteOps | Completed read/write operations from and to all ephemeral volumes available to the instance. | Resource: Utilization |
| DiskReadBytes/DiskWriteBytes | Bytes read to/written from all ephemeral volumes available to the instance. | Resource: Utilization |
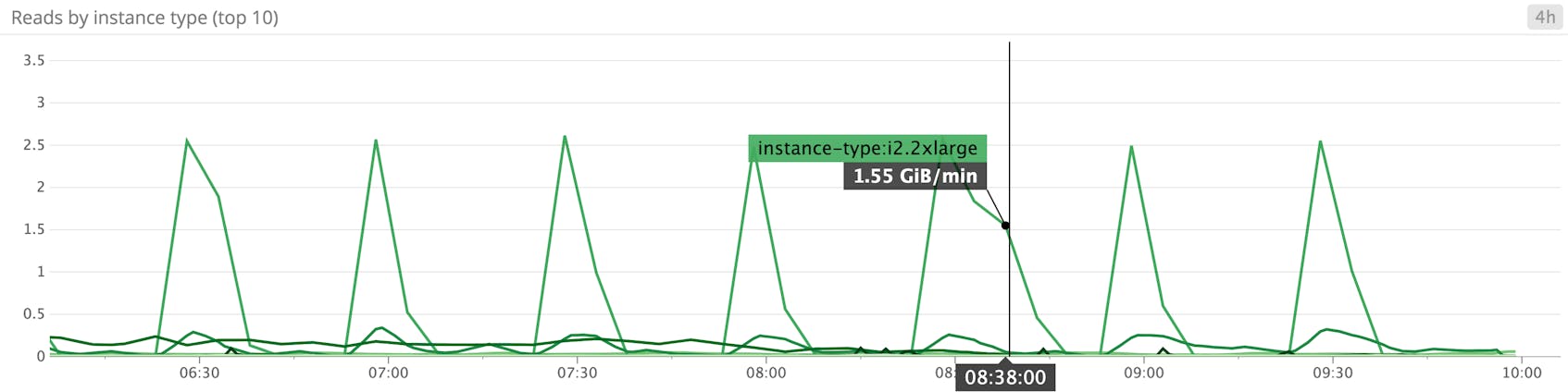
Disk read/write operations
Because any data stored on instance store volumes is lost if the instance stops or fails, these types of volumes are best suited for I/O-intensive uses such as buffers, caches, and other cases where data is stored temporarily and changes frequently. This metric pair can help determine if degraded performance is the result of consistently high IOPS, causing bottlenecks as disk requests become queued. If your instance volumes are HDD, you can consider a move to faster SSDs. Or you can upgrade the VM to an instance with more volumes attached to it.
Disk read/write bytes
Monitoring the amount of data being written to and read from disk can help reveal application-level problems. Too much data being read from disk might indicate that your application would benefit from adding a caching layer. Prolonged higher-than-anticipated disk read or write levels could also mean request queuing and slowdowns if your disk speed is not fast enough to match your use case.
Network metrics
Network metrics are particularly important for cloud-based services like EC2 that rely on consistently strong network connections, and that might be dispersed across various availability zones. This is especially true if you have attached EBS volumes to your instances, as they are networked drives. Instance types provide different limits both for network bandwidth and maximum transmission unit (MTU), or the largest amount of data that can be sent in a single packet. Bandwidth limits range from 5 to 25 Gbps. Network MTU is a standard 1,500 bytes for most instance types, but many allow jumbo frames of as much as 9,001 bytes, increasing efficiency and reducing overhead for applications that transmit large amounts of data. Selecting the right type and availability zone for your instances can improve network performance, as can configuration options such as placement groups and enhanced networking.
In addition to measuring network throughput in bytes, CloudWatch provides metrics for packets sent and received. Note, though, that packet metrics are only available in basic monitoring, at five-minute resolution.
| Name | Description | Metric type |
|---|---|---|
| NetworkIn/NetworkOut | Number of bytes received/sent out on all network interfaces by the instance. | Resource: Utilization |
| NetworkPacketsIn/NetworkPacketsOut | Number of packets received/sent out on all network interfaces by the instance. Only available at five-minute resolution. | Resource: Utilization |
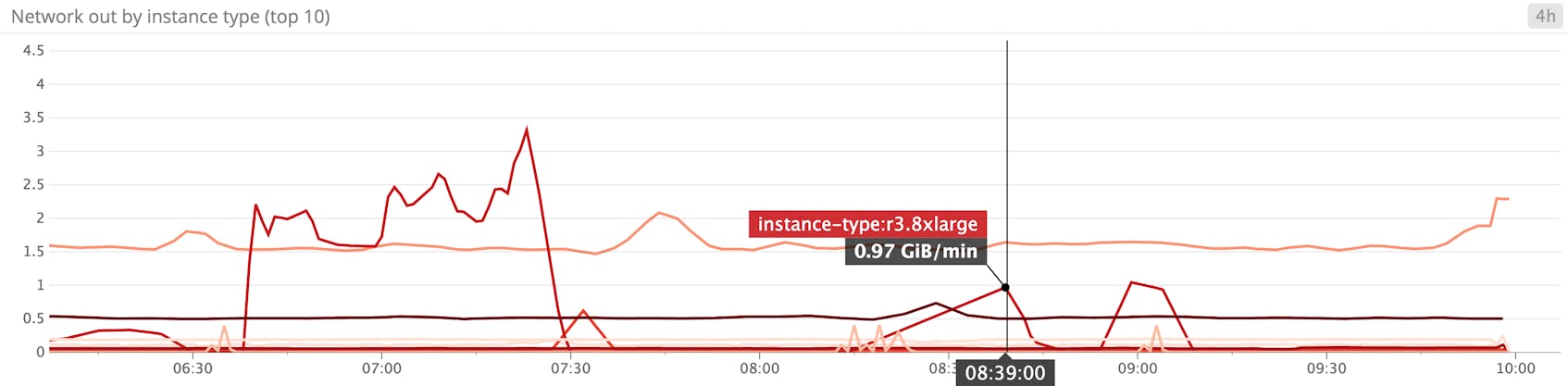
Network in/out
These metrics report the network throughput, in bytes, of your instances. Drops or fluctuations can be correlated with other application-level metrics to pinpoint possible issues. It’s unlikely that your instances will approach their network throughput limits unless they are severely mismatched with your application’s needs, but it can still be helpful to keep an eye on possible network saturation to make sure your instances meet demand—for example, if you want to restore or backup large amounts of data quickly. Or, if certain instances are receiving considerably more network traffic than others, you may wish to use a load balancer to distribute traffic more evenly.
CPU metrics
EC2 instance types have a wide range of vCPU configurations, so tracking CPU usage can help ensure that your instances are appropriately sized for your workload. Note that CloudWatch measures the percent utilization of the virtualized processing capacity of the instance, which AWS labels “compute units.” It does not report CPU usage of the underlying hardware that the instance is being hosted on.
T2 instances are capable of bursting, or providing processing power above a standard baseline level for short periods of time. This is ideal for applications that are not generally CPU intensive but may benefit from higher CPU capacity for brief intervals. See the T2 instance documentation for details on this instance type.
| Name | Description | Metric type |
|---|---|---|
| CPUUtilization | Percentage of allocated EC2 compute units that are currently in use on the instance. | Resource: Utilization |
| CPUCreditBalance* | Number of CPU credits that an instance has accumulated. | Resource: Utilization |
| CPUCreditUsage* | Number of CPU credits consumed. | Resource: Utilization |
| CPUSurplusCreditBalance** | Number of credits consumed after CPU credit balance has reached 0. | Resource: Utilization |
| CPUSurplusCreditsCharged** | Number of surplus credits not offset by earned CPU credits and that will incur charges: CPUSurplusCreditBalance - CPUCreditBalance | Resource: Utilization |
| * Only available on T2 instances. ** Only available on T2 Unlimited instances. | ||
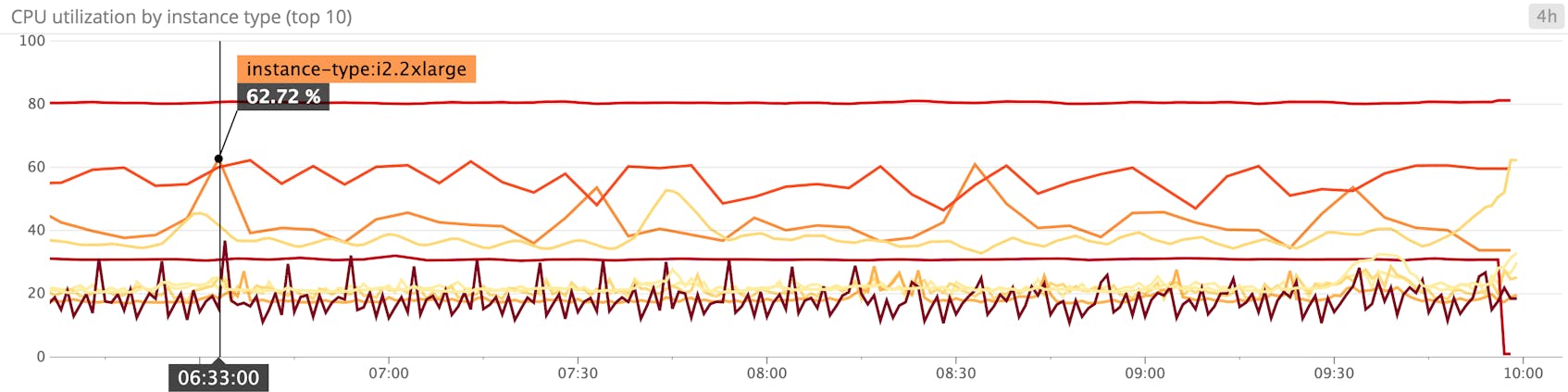
CPU utilization
CPU usage is one of the prime host-level metrics to monitor. Depending on the application, consistently high utilization levels may be normal. But if performance is degraded, and the application is not constrained by disk I/O, memory, or network resources, then maxed-out CPU may indicate a resource bottleneck or application performance problems. You can dive into application-level metrics or request traces to diagnose the cause of CPU saturation, or switch to an instance type with more vCPUs.
For instances with bursting, the increased processing power comes at the cost of CPU credits. EC2’s CPU credit metrics help keep track of your available balance and usage so that you are aware of possible charges as a result of extended bursting.
CPU credit balance
For standard T2 instances with bursting, a burst can continue only as long as there are available CPU credits, so it’s important to monitor your instance’s balance. Credits are earned any time the instance is running below its baseline CPU performance level. The initial balance, accrual rate, and maximum possible balance are all dependent on the instance level.
CPU credit usage
One CPU credit is equivalent to one minute of 100 percent CPU utilization (or two minutes at 50 percent, etc.). Whenever an instance requires CPU performance above that instance type’s baseline, it will burst, consuming CPU credits until the demand lessens or the credit balance runs out. Keeping an eye on your instances’ credit usage will help you identify whether you might need to switch to an instance type that is optimized for CPU-intensive workloads. Or, you can create an alert for when your credit balance drops below a threshold while CPU usage remains above baseline.
CPU surplus credit balance
In the case of T2 Unlimited instances, if the CPU credit balance is exhausted but burst performance is still required, the instance will consume additional credits to maintain greater CPU usage. This metric tracks the accumulated balance.
CPU surplus credits charged
This metric tracks the difference between the number of credits accumulated and the current credit balance that can be used to pay down the surplus balance. In other words, it is a measure of extra credits that will result in additional charges.
Status checks
EC2 status checks are, simply, checks on the status of an individual instance and of the AWS systems hosting it. Status checks are available at one-minute intervals. They provide a clear, high-level indication of an instance’s health and whether there is a problem with either the larger AWS infrastructure or with the software or network configuration of the instance itself.
| Name | Description | Metric type |
|---|---|---|
| StatusCheckFailed_System | Returns 1 if the instance has failed EC2's system status check. | Resource: Availability |
| StatusCheckFailed_Instance | Returns 1 if the instance has failed EC2's instance status check. | Resource: Availability |
Metric to watch: Status check failed—system
This status check reports whether there are problems detected with the system hosting the instance. Generally these are problems with the Amazon-administered computer on which your instance is hosted and are outside of your control—as an example, power loss. Possible resolutions include stopping and restarting an instance to switch it to a new host computer. (Keep in mind that instance store–backed volumes will be lost if the instance is stopped.) This check returns False (0) if an instance passes the system status check, and True (1) if it fails.
Metric to watch: Status check failed—instance
This check reports whether there are any problems detected with the instance itself and returns False (0) if an instance passes the status check and True (1) if it fails. Problems that might cause this check to fail include software or network configuration issues, a corrupted file system, etc. Amazon’s troubleshooting tips offer causes and possible solutions for common errors that result in a failed status check.
Events
Events are scheduled changes in an instance’s lifecycle. AWS may initiate events if problems are detected or if standard maintenance is required on an instance’s host computer.
Events include:
- Stopping an instance. This is only applicable to EBS-backed instances, which retain their data and can be restarted. If restarted, the instance will be hosted on a new computer.
- Retiring an instance. This will terminate the instance and delete any attached volumes.
- Rebooting either the instance (again, only applicable to EBS-backed instances) or the host computer.
- System maintenance, possibly affecting the instance’s performance or availability.
AWS will inform users if an event has been scheduled for their instances. But you can also use CloudWatch’s events stream to track events and monitor upcoming changes to your EC2 infrastructure that might degrade performance or affect data availability. This is particularly important for any instance store volumes—even if they are connected to an EBS-backed instance—as all data stored on those volumes is lost. Keeping an eye on your EC2 events will help you determine if you need to migrate data to a new instance before the current one is terminated or stopped.
Memory metrics
For many use cases, such as large, high-performance databases and in-memory applications, memory metrics are particularly vital to keeping an eye on your infrastructure and identifying problems and performance bottlenecks. However, Amazon’s CloudWatch does not report system-level memory metrics for instances. In addition to the metrics covered in this post, part two of this series will cover how you can collect memory metrics so that you have full visibility into the resource usage of your EC2 infrastructure.
Getting started
In this post we have looked at several standard metrics that are invaluable for EC2 monitoring as well as tracking the health of your applications. EC2’s huge range of instance types lets you create an infrastructure optimized for just about any use case, so keeping an eye on resource utilization is particularly important for determining if it is necessary to change, upgrade, scale up, or even downsize your instance fleet so that it meets your needs efficiently and cost-effectively.
Now that we know what metrics to collect, the next post will guide you through the process of collecting them, via the CloudWatch console, the AWS CLI, or a monitoring tool that integrates with the CloudWatch API.
