

Elastic Block Storage (EBS) is a storage service offered by Amazon Web Services (AWS) that is backed by network block storage. EBS is critical for traditional database systems since it combines large storage capacity with reasonable throughput and latency. However, because it relies on the network, EBS can cause performance issues in your systems running on EC2.
When performance issues occur, it is important to determine if these issues are caused by EBS or some other part of your infrastructure. Datadog collects and aggregates various AWS metrics and offers features which can identify if performance issues are originating in EBS. The necessary steps to enable these capabilities are detailed below.
Measuring Storage Performance in EBS
Storage performance is usually measured in input/output operations per second (IOPS). It is not a perfect measure but acts as a useful yardstick to compare different storage systems.
EBS performance is thus expressed in IOPS. A careful read of the EBS documentation indicates that IOPS refer to operations on blocks that are up to 16KB in size.1
EBS volumes come in 2 flavors: standard and Provisioned IOPS:
Standard EBS - Standard EBS volumes deliver 100 IOPS on average (on blocks of 16KB or less). This is roughly the number of IOPS a single desktop-class 7200rpm SATA hard drive can deliver. In comparison, a similar desktop-class SSD drive can deliver between 5,000 and 100,000 IOPS.
**Provisioned IOPS - **Provisioned IOPS can deliver up to 4,000 IOPS per volume if you have purchased that throughput. If you strictly adhere to a number conditions, you can expect 99.9% of the time in a given year that the volume will deliver between 90% and 100% of its provisioned IOPS.
For more on how to achieve optimal Provisioned IOPS performance, see our blog post: Getting optimal performance with AWS EBS Provisioned IOPS.
Why AWS EBS performance issues occur
AWS EBS performance issues occur for two fundamental reasons:
- Standard EBS volumes are slow – Because EBS data traffic must use the network, it will always be an order of magnitude slower (as measured by its latency) than using local storage. Typical latency for network storage is 50-100 ms, versus 10ms for local storage.
- The actual storage and network hardware is shared – The network that exists between your instances and your EBS volumes is shared with other customers. When other customers begin to use a higher volume of the network or storage volume, your performance may be affected. This is not the case when you use local storage.
How to detect AWS EBS performance issues with Datadog
To detect AWS EBS performance issues you need to track the CloudWatch metric “VolumeQueueLength”. This is quick and easy to do in Datadog. The graphs shown below are available after signing up for a free trial of Datadog and enabling the AWS integration.
AWS CloudWatch’s VolumeQueueLength metric measures the number of I/O requests that are pending at a given time. By comparing VolumeQueueLength for each EBS volume attached to a slow application you can narrow down the cause of the slowness to an EBS issue. To see VolumeQueueLength in Datadog, go to the metrics explorer by hovering over the “Metrics” tab and selecting “Explorer” from the dropdown menu.

On the left of the Metrics Explorer screen, begin typing “aws.ebs.volume_queue_length” in the “Graph:” text box and select it from the dropdown options.

By default the Metrics Explorer will track all the hosts you’re monitoring with Datadog. You want to track just hosts with EBS volumes connected to you slow applications. In the “Over:” text box, enter the hostname for an EBS volume related to slow applications.

Finally, select the time period to analyze. For this example, we will look at the past 24 hours by choosing “The Past Day” from the “Show” menu.

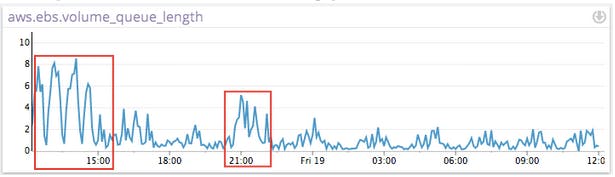
A sustained increase of VolumeQueueLength way above 1 on a standard EBS volume should be treated as exhausting the throughput of that EBS volume. A sustained increase of the same metric way above the number of provisioned IOPS/100 should be treated as maxing out the throughput of that EBS volume. In the image below there are two distinct cases where queue length is significantly above 1 for extended periods of time. Both indicate periods when the EBS volume’s throughput was maxed out.
How to fix AWS EBS performance issues
There are a number of ways to resolve EBS performance issues once they’re detected, or to try to avoid these altogether. These steps include:
Selecting the right storage and instance types
Priming your EBS volumes
Using Instance Store volumes instead of EBS
Purchasing Provisioned IOPS
Replacing a degraded EBS volume if needed
More information on how to implement these resolutions or how to avoid issues in the first place is available in our free eBook - The Top 5 Ways to Improve Your AWS EC2 Performance.
