![Datadog in the wild : Fixing slow writes on AWS Elastic Block Store [訳]](https://blog.dd-static.net/img/blog/datadog-wild-fixing-slow-writes-aws-elastic-block-store-%E8%A8%B3/40.png?auto=compress%2Cformat&cs=origin&lossless=true&fit=crop&q=75&ar=380%3A193&w=1400&h=711&dpr=1 "Datadog in the wild : Fixing slow writes on AWS Elastic Block Store [訳]")


Jay Hotta
Datadogを使って、AWS EBSの書き込みスピードの低下を防止する。
この記事は、Konotor.comの共同創業者のDeepak Balasubramanyam(@deepakbsub)氏が書いてくださいました。Konotor.comは、モバイルアプリケーションのユーザへの遭遇、維持、販売を促進するモバイルファーストのユーザエンゲージメントのプラットフォームです。
This is a guest post from Deepak Balasubramanyam @deepakbsub, a co-founder of Konotor.com, which is a mobile-first user-engagement platform that helps businesses engage, retain, and sell more to their mobile app users.
背景
Konotorは、昨年飛躍的に成長しました。その結果、私達の事業の規模も急激に拡大しました。多くの成長企業がそうであったように、私達も事業規模に合わせた監視を実践するために膨大なエネルギーを使うようになりました。下記は、私達が日々抱えた疑問でした。
- どのメトリクスを監視すれば良いのか?
- 問題が発生する前に、技術部隊に対してどのように警告すればよいのか?
- 各種イベント情報の関連性を使って、目の前の現象をどのように理解すればよいのか?
Konotor has grown tremendously over the last year, so the scale of our operations has grown quickly, too. Like many growing companies, we were finding ourselves spending an increasing amount of energy to make our monitoring practices keep pace with our business. These were some of our pressing questions:
- Which metrics should we monitor?
- How can we alert the technical team before a problem occurs?
- How do we correlate events from different sources and make sense of what happened?
そんな時にDatadogを見つけました。Datadogは、先のすべての疑問に答えるだけでなく、更に多くのことを教えてくれました。Datadogを使ってモニタリングすることは、Konotorにとって非常に価値がありました。この記事では我々が抱えていた大きな課題(PostgreSQLのスケール)を、Datadogを使って解決した内容を共有したいと思います。
Then we found Datadog. It answers all those questions and more. Monitoring with Datadog has been hugely valuable for Konotor. In this article I’ll share how Datadog helped us solve one of our big problems: scaling our PostgreSQL database.
課題: EBSの遅い書き込みの解消
私達はPostgresSQLから高速なレスポンスが欲しかったので、 SSDを使ったAWS EBSを採用することにしました。物事は順調でした、遅い書き込みクエリが発生し、アラートを出し始めるまでは。遅いというのは、極端に遅いということです。普段なら50msで応答するものが800msを要します。Datasdogのダッシュボードではトラフィックのピークは過ぎており、一日は終わろうとしていたため、この状況を不可解に感じました。その症状が発生した時は、データディスクで、キュー長の値が高くなっていましたが、何がこの値を引き上げているのか分りませんでした。
We wanted fast database responses from PostgreSQL, so we decided to use SSD-backed Elastic Block Storage (EBS). Things went fine until we started getting alerts that some of our write queries were starting to get slow. By slow I mean real slow. What would normally take 50ms now took 800ms. This was baffling since traffic stats on Datadog showed us that the peak traffic had already passed and the day was coming to a close. The queue length on the data disk was quite high when this happened, but what was causing it?
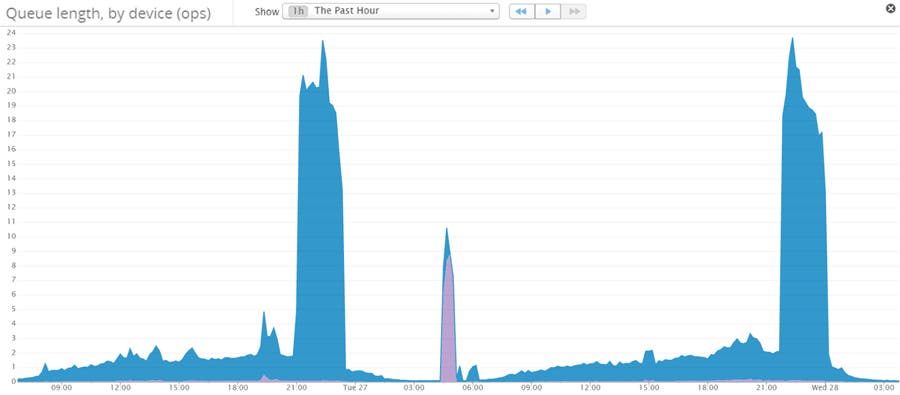
原因究明
そこで我々は、キュー長と書き込みの相関関係を見ることにしました。そして、異常を発見しました。書き込みが減り始めると、キュー長の値が突然跳ね上がるのです。(以下の図を参照) 何が起きているのでしょう。
We decided to correlate the writes with the queue length, and we found something strange: queue lengths spiked immediately after writes started to go down (see below). What was happening?
デバイスのキュー長と書き込みオペレーションの数の相関関係
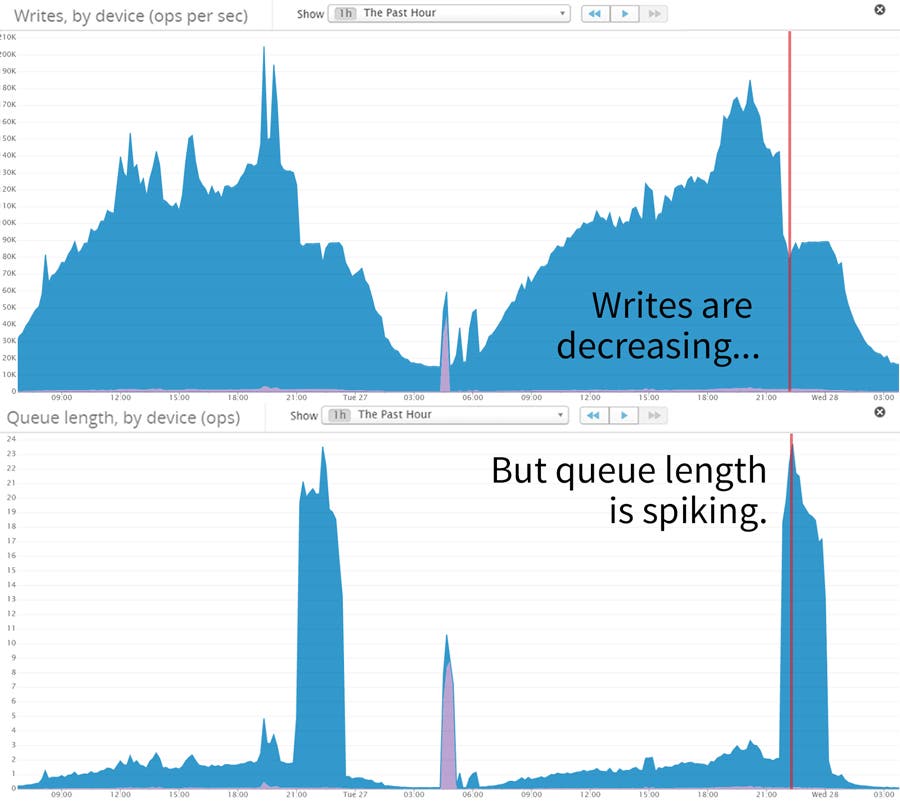
Konotorは、書き込みの多いアプリケーションです。このアプリでは、モバイルユーザーのメトリクスと、時間と共に変化するプロパティを追跡しています。上のグラフが、解決の糸口になりました。アプリケーションから大量の新しい書き込みのリクエストが発生している状況でも、EBSへの書き込みは減少していきます。 そして、キューに蓄積されていきます。Datadogを使うことにより、私達はCPUを使い切っていないことを確認することこができました。CPUは、IOの待ち時間で消費されていました。そして、使用できるメモリーは残っており、PostgreQSLも大丈夫なようでした。これらの情報が、私達を結論に導きました。“EBSのサービスが書き込みを制限してる!”
Konotor is a write-heavy application. We keep track of mobile user metrics and custom properties which change with time. The graphs above gave us a clue: EBS writes were declining even while plenty of new write requests were coming in from the application (and being sent to the queue). Using Datadog, we confirmed that CPU was not maxed (though it was spending a lot of time waiting on IO), there was available RAM, and our PostgreSQL locks looked fine. This lead us to our insight: EBS was throttling our writes!
新しいディスクをデータベースに割り当てている間、ディスクがどれくらいのIOPSを消費するか、正しく調整することができていなかったということを、我々は発見しました。
例えば、サイズが100ギガバイトで、500のIOPSを割り当てられたSSDディスクを購入するとしましょう。私たちが選択したように汎用目的のSSDのディスクを使った場合、サイトがトラフィックの急激な増加に遭遇した時のために、EBSは一時的にIOの上限を緩和するようになっています。この記事の執筆時点で、この緩和量を計算する式が次になります。
We discovered that while allocating new disks to the database we had failed to correctly calibrate how many IOPS the disks would consume. Let’s say that you purchase a SSD disk that is 100 GB in size and has 500 IOPS allocated to it. With the General Purpose (SSD) volumes we used, EBS will allow you to exceed your IO limit in case your site encounters bursts in traffic. At the time of this writing there is a formula to calculate this.

クレジット(credit)とは何か? あなたのデバイスが期待しているパフォーンス基準値以下で稼働している場合、クレジットは蓄積されていきます。そして高負荷により、割り当てられた書き込みと読み出しを消費したところで、EBSの制限機能が動作し始め、デバイスのIOPSをパフォーマンス基準値に落とします。
What is a credit you ask? Your device accumulates credits when you do not exceed its base performance. Since we had consumed more writes (mostly) and reads than what were provisioned for us, the EBS throttle kicked in and capped our IOPS to the device’s base performance.
解決策
個別または組み合わせて使用することができる解決策を紹介します。あなたの状況にあった解決策を選択してください。
There are many possible solutions which can be used separately or together. Use the strategies that are best for your situation.
複数のディスクへストライピング
ストライピングすることにより、ディスクアクセスのIO負荷を分割することができます。そしてこのアプローチは、急激なトラフィックの増加を上手にこなしてくれます。しかし、ディスク障害に対処するために、データベースの万全なバックアップ手順を確立しておいてください。
By striping you can spread the IO load across your disks, and this approach can handle burst pretty well. Be sure that database has the right backup policies to handle disk failures.
プロビジョンド IOPS (SSD)を利用する
勿論IOパワーを追加購入することで、問題を解決することもできます。本番環境でアプリケーションがスケールするために、N個のIOPSを必要としているというケースです。この戦略を使う場合は、必ずEBSオプチマイズドインスタンスを購入してください。それ以外の条件に関しては、Datadogに詳しく記述されているので、そちらを参照してください。
You can always buy your way out with more IO power. It may simply be the case that your application needs N IOPS to scale in production. If you use this strategy, be sure to purchase an EBS optimized instance. Other conditions to be met have already been documented well by Datadog.
エーファーマルストレージを利用する
エファーマルストレージは、誰もが知っているようにEBSより高速です。しかし再起動の際にストレージが一掃されるので、私のケースとの相性はよくありませんでした。このソリューションは、何をしているかを理解している場合、又はプライマリーサーバが停止す前のフェールオーバー計画ができている場合に採用してください。
This is faster than EBS for obvious reasons, but the solution never did sit well with me since storage will be wiped out during a restart. Use this solution only if you know what you are doing, and figure out your failover plans before your primary goes down.
頻繁にアクセスするテーブルとインデックスを他のディスクへ移動する
PostgreSQLには、新しい表領域を定義し、ALTER文を使用して新しい表領域に特定のテーブルやインデックスを動的に移動する機能があります。テーブルやインデックスを別のディスクへ移動することにより、書き込み中心のトランザクションが他のトランザクションに影響を与えないようにすることができます。新しい表領域へのテーブルとインデックスの移動は、そのテーブルをロック状態にしますので、十分注意して作業を行ってください。
PostgreSQL allows you to define a new tablespace dynamically and move specific tables / indexes to the new tablespace using the ALTER clause. This ensures that write heavy transactions do not affect other transactions. The tables will be locked when you move the tables / indexes over to a new tablespace, so do this with care.
書き込みIOを減らす
Tuning your app writes and trimming indexes can help reduce IO.
Can your application buffer writes and aggregate them before flushing it to the database? An INSERT or UPDATE operation on your table will lead to more writes depending on the number of indexes that need to be updated. Can you afford to drop some of them or prune them using partial indexes?
検知と予防
質の良い監視システムを採用することで、EBSの書き込みスピード低下の問題で、ユーザーに影響を与えることを避けることができます。
- 全てのディスク上のIOトランザクションを監視し警告するようします。AWSより割り当てられているIOの限界に近付き始めたら迅速に対応し、IOクレジットを使いきってしまう状況にならないようにアラートを設定します。
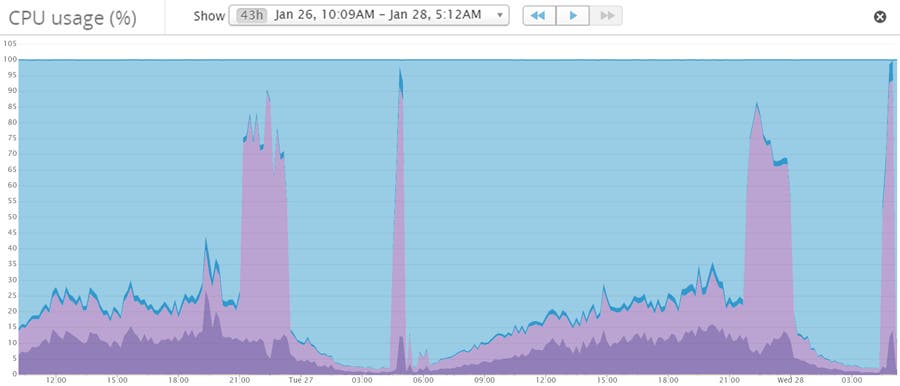
- CPU時間がどのように使われているか監視します。我々がこの問題に遭遇していた2日間、長いキューの待ち時間のために大半のCPU時間はIO待ちに使われていました。次のグラフでは、実際のCPUの使用量は低く、薄い紫色のIO待ちが非常に高いのに注目してください。
With good monitoring, you can avoid ever having these problems affect your users.
- Monitor and alert the IO transactions on all your disks. Set your alert so that if you begin to approach your provisioned IOs you can act quickly and avoid running out of IO credits.
- Monitoring how CPU time is the CPU time spent. When we ran into this issue over the span of 2 days, most of the CPU time was spent on IO waits due to a high queue length. Notice how the actual CPU utilized is low but IO wait (shown in light purple) is very high.
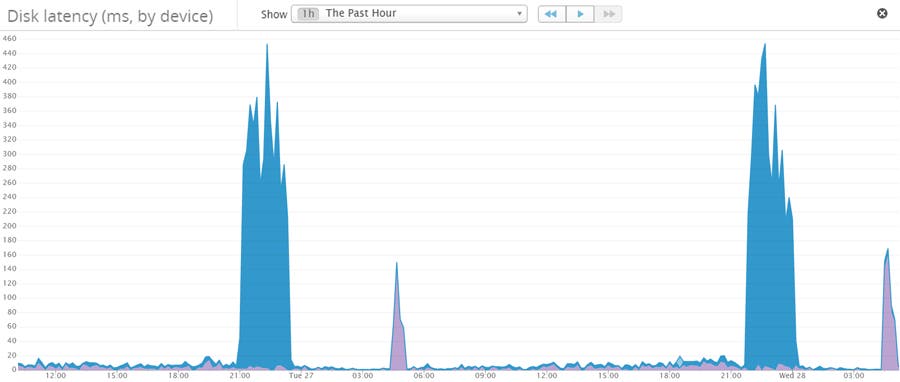
ディスクレイテンシー監視。同時にディスクレイテンシーの値が高いところを見ていきます。
Monitor disk latencies. You should monitor for high disk latency, too.
Datadogの優位性!
ここまで見てきたように、Datadogが背後で支えてくれていることは、我々が事業を拡大していく上で非常に心強いことです。以下に、Datadogの優れている部分を紹介してみます。
As we look to scale our operations we rest easy knowing that Datadog has our back. These are some of the areas where Datadog shines.
相関関係/依存関係
データベースへの書き込みの増加が、Webトラフィックの増加によるものか、バージョン3.0.1のアプリケーションで追加されたインデックスによるものかを判断するには、データの相関をとってみる必要があります。そのような場合、自らそれらのメトリックをAWSから取得できるでしょうが、取得したメトリクスを関連付けたり、動的ダッシュボードを構築する部分は、自作ソフトでは結構の手間になります。
To know if increased writes to your database came from increased web traffic or an index you added at version 3.0.1 of your application, you need to correlate data. While you can get some of these metrics from AWS, you cannot correlate them easily or construct dashboards dynamically.
多様なインテグレーション
インフラが拡大していくとともに、多岐にわたるソースのメトリックが必要になってきます。Kafkaを使っていようが、Tomcatを使っていようが、Datadogには様々なフレームワークやサーバーアプリケーションのプラグインがあります。
As you expand your infrastructure you will need more sources for metrics. Whether you use Kafka or Tomcat, Datadog has a plugin for any framework / server under the sun.
少ない動作負荷
Datadogのエージェントは動作負荷が少ないです。本番環境へのオーバーヘッドは、最小限になっています。プラグイン(Datadogインテグレーション)は、メトリクスデータを監視先のHTTP APIから収取することもできます。例えば、RabbitMQのがそのHTTP API経由の手法で、フレームワークの内部に存在し、プロセスの割り込んでメトリクスを収集するようなことはしていません。
Datadog’s agents are lightweight and add little to no overhead to a production system. Plugins can poll data from a framework’s HTTP API for example (say from RabbitMQ) instead of gathering this data more intrusively (by existing inside the framework).
最後に。
もしも、ストレージの問題でユーザーに影響を与える状況を避けたいと考えているなら、Datadogの14日間無料トライアルにサインアップし、CPUの使用率やディスクのレイテンシー、その他を監視することをお勧めします。
If you’re looking to avoid ever having storage problems affect your users, sign up for a 14 day free trial of Datadog and monitor your CPU usage, disk latency and much more.



