
To make modern application architectures more observable, we’re excited to announce general availability of serverless monitoring in Datadog. In the Serverless view, you can search, filter, and explore all your AWS Lambda functions in one place, and jump straight into detailed performance data for each of them:
- Troubleshoot performance issues with distributed traces, and filter your serverless traces by cold starts, timeouts, duration, or errors
- Collect custom metrics in real time from serverless functions to monitor key business metrics without adding latency to your applications
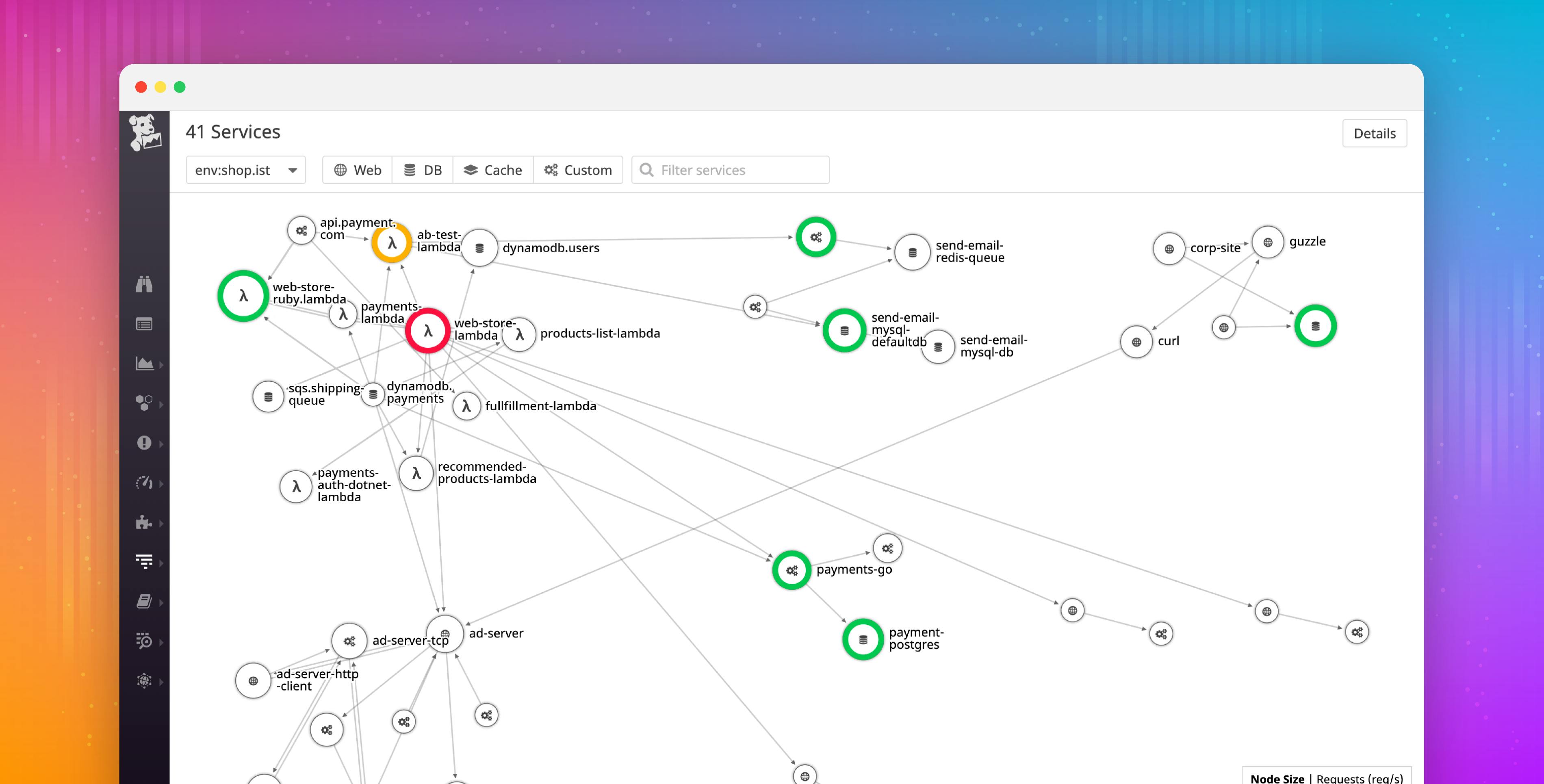
- See the bigger picture in the Service Map, which visualizes Lambda functions along with their dependencies (e.g., API Gateway, DynamoDB, S3)
In our conversations with customers since announcing the Serverless beta in late 2018, we’ve often heard how serverless architectures augment existing servers and infrastructure. It’s not easy to go all-in on serverless right from the start, which is why we’ve ensured that Serverless works seamlessly with the rest of Datadog. For example, we’ve made it easy to trace requests across any kind of infrastructure, whether in Lambda, EC2, or even running on-prem. And you enjoy the same power to drill down into a specific metric, log line, or trace from anywhere in Datadog.
With these additions to the Datadog platform, all the data you need for troubleshooting serverless functions is now available in one place.
Serverless meets the 3 pillars of observability
From an operations standpoint, serverless functions are fundamentally different from applications running on servers, VMs, or containers. From a monitoring perspective, however, you still need observability data like work metrics (requests, errors, latency), request traces, and logs to ensure that your serverless functions are performing properly, and to troubleshoot any issues that arise.
Explore performance data from all your Lambda functions in one place with Datadog.
The Serverless view in Datadog provides a searchable, sortable view of all your functions. Faceted search allows you to filter your functions using metadata such as function name, AWS account, region, runtime, and team name, whether that metadata is collected from your cloud provider or applied as a custom tag. In the Serverless view, you can also sort all your functions using high-level statistics such as number of invocations, average duration, error count, and memory usage.

Clicking on any function from the Serverless view takes you straight to detailed, function-specific data from all three pillars of observability: metrics, logs, and distributed traces.

Monitoring cold starts, timeouts, and more
Serverless monitoring does have some fundamental differences from traditional infrastructure monitoring. The runtime environment is minimal—and beyond the developer’s control. These differences mean that there is no place to install a monitoring agent, and some of the metrics you care about are unique to serverless environments.
There are also strict limits that control how your code runs: allocated memory, maximum timeout, and concurrency limit. When you exceed these limits, your Lambda functions will timeout or be killed by the runtime. Finding out about looming limits can therefore help you prevent user-facing availability or performance issues.
Cold starts are less predictable—they occur when the cloud provider scales up your functions behind the scenes to handle more requests. Your customers could see requests taking longer to complete when your functions need to cold start. Datadog detects when cold starts occur, and automatically applies a cold_start attribute to your request traces. So you can search all your traces to find cold starts for any service or function and determine their impact on overall application performance.

Datadog APM for serverless
Regardless of where your code runs, Datadog traces it. Whether in a Lambda function, on a host, or on a combination of both, you can see exactly what happens in the full lifespan of a request.
Tracing Lambda functions with X-Ray
Datadog’s integration with AWS X-Ray enables you to visualize Lambda trace data, so you can zero in on the source of any errors or slowdowns, and see how the performance of your functions impacts your users’ experience.
Tracing is especially valuable for Lambda and other serverless platforms, because it allows you to visualize how requests travel between the numerous components of a serverless architecture. If your application’s end-to-end latency starts increasing, you can see in an instant whether the bottleneck is due to code-level issues in one of your Lambda functions, hitting your limits for Lambda concurrency, or issues in a service dependency like DynamoDB.

If your request invokes multiple Lambda functions connected by other AWS components such as SNS or API Gateway, X-Ray will automatically instrument each of these functions and tie them together in a single trace. Within the trace detail view in Datadog, you can easily jump from one function to another via auto-generated links.
Distributed end-to-end tracing, anywhere
Your requests may originate from on-prem hosts and hit Lambda functions, or may skip between Docker containers and Lambda functions. Datadog intelligently ties together traces from VMs and X-Ray traces from Lambda. To automatically create unified traces in Datadog for end-to-end analysis, customers only need to add a few lines of code to their Lambda functions. (No code changes are required to your code running on VMs.)
Not only does Datadog track request traffic flowing through Lambda functions and other application code, but it follows requests across your microservices, through message queues, and deep into database tables. Seeing these distributed traces and logs in the same view, along with your infrastructure metrics, makes it easier to get to the root cause quickly.
Instrument Lambda functions for tracing
To instrument a Lambda function for tracing with X-Ray, navigate to the Lambda function in the AWS console, scroll to the “Debugging and error handling” section, and check the box to “Enable active tracing.”
To do this with the Serverless Framework, add the tracing section to your provider configuration:
serverless.yml
provider:
name: aws
runtime: python3.7
tracing:
lambda: true
apiGateway: trueThen, in your function code, import the X-Ray SDK and patch all supported libraries. For Python applications, instrumentation is as simple as importing the SDK and adding a one-liner to your function to start automatically tracing all calls to AWS services and other X-Ray-supported integrations:
patch_all()Instrumentation is available for Python, Node, Go, Java, Ruby, and .NET.
Service Map for serverless
On the Service Map, you can now visualize how your Lambda functions fit together into services, and how requests flow across your infrastructure.
Compose your serverless functions into services, and create alerts to see the health of your infrastructure all in one place. The Service Map automatically reflects the status of your alerts, giving you a color-coded view into the health of your infrastructure and application. When alerts are firing, you’ll see right away which services were affected, regardless of whether they are API Gateways, Lambda functions, or web applications running on EC2.

Serverless metrics and logs
The addition of Lambda tracing to the Datadog platform complements the insights that we’ve long provided for your functions via metrics and logs. Each of these data types provides valuable insights into the usage and performance of your serverless functions, from overall performance summaries to low-level error reporting.
Track business goals with real-time custom metrics
With Datadog custom metrics for Lambda, you can track the number of signups, conversions, or orders being placed, all in real time. Our forwarder function sends data to Datadog asynchronously, without relying on your Lambda functions to make API calls, so you can monitor key business metrics from your serverless functions without adding unnecessary latency to your applications. Enable custom metrics in your serverless functions with the Datadog Lambda Layer. Asynchronous reporting of custom metrics is now available for Python, Node, Ruby, Java, and Golang functions.
Logs: Errors, duration, memory usage
Lambda logs are extremely valuable for debugging, as they provide detailed error reporting and low-level details for each invocation. Logs capture data such as the execution time for a particular invocation, the billed duration, and the actual memory usage as compared to the memory allocated to the Lambda function. Because you pay for allocated resources rather than actual usage, these memory statistics can help you identify overprovisioned functions so you can balance Lambda performance with costs. Similarly, you can identify Lambda functions that are underprovisioned, and assign more memory to those functions to improve their performance. These memory statistics are available at full granularity in the Lambda logs, and are also aggregated automatically for each Lambda function in the Serverless view.

Get full visibility into your serverless functions
If you’re already using Datadog to monitor your applications, cloud infrastructure, and serverless functions, visit the Serverless view today to start monitoring and exploring all the performance data from your Lambda functions in one place. Then enable the X-Ray integration to start tracing requests as they travel through your architecture for even greater visibility.
If you don’t yet have a Datadog account, you can start a free, full-featured trial today to get deep visibility into your applications, infrastructure, and serverless functions in one platform.
