

When it comes to collecting EC2 metrics and events, you will likely make use of Amazon’s CloudWatch service. But even from that one source, there are a few ways to get data. Each of these methods will enable you to collect the same metrics. You can access CloudWatch metrics through:
- the CloudWatch web console,
- the AWS command line tool, or
- a program or third-party monitoring service that connects to the CloudWatch API.
You can supplement the available CloudWatch metrics by running a monitoring agent that pulls system-level information that CloudWatch may not collect directly from your EC2 instances. We will go over all of these approaches in this post.
But first: Are you you?
Securing and controlling user access to AWS can get complicated, especially at larger organizations that might have multiple teams and hundreds of users, not all of whom require the same permissions. AWS Identity and Access Management (IAM) provides a way to administer and secure API access. The following steps for monitoring CloudWatch metrics assume that you have access to a user account or role whose security policy grants the minimal permissions needed to manage the CloudWatch and EC2 APIs. See the AWS documentation for information.
Regional differences
As mentioned in part one of this series, you can launch EC2 instances in different geographical regions, each of which contains multiple availability zones. Regions and the resources hosted in each are isolated from one another. One consequence of this is that you can only view one region’s metrics at a time through CloudWatch unless you create dashboards that pull metrics in from multiple regions. Otherwise, you must specify which region’s instances you want to view. How to do this is described below.
Watching the clouds
CloudWatch collects metrics through the hypervisor from any AWS services you may use in your infrastructure. Namespaces allow you to specify which service (e.g. EC2) you want to view metrics for. As mentioned in part one of this series, by default CloudWatch publishes metrics at five-minute intervals. If detailed monitoring is turned on, this granularity increases to every minute, but certain metrics are only available with basic monitoring, and others can only be aggregated at a five-minute frequency even with detailed monitoring enabled. Custom metrics, which will be covered later, can be forwarded at a much higher frequency, though that can incur additional charges.
To help you drill down into specific parts of your EC2 infrastructure, CloudWatch provides a few means of filtering and aggregating data: dimensions, periods, and statistics.
Dimensions
Dimensions are preset groupings of instances. Selecting a dimension will filter your metrics to isolate that particular group. The EC2 namespace provides the following dimensions:
InstanceId: Isolates data from a specific instance.AutoScalingGroupName: Filters instances by their Auto Scaling group, if they are assigned to one.ImageId: Filters instances by their Amazon Machine Image (AMI). This dimension is only available for instances with detailed monitoring enabled.InstanceType: Filters instances by instance type. This dimension is only available for instances with detailed monitoring enabled.
Periods
The period sets the timespan, in seconds, over which CloudWatch will aggregate a metric into data points. The larger the period, the less granular your metric data will be. Note, however, that aggregation periods shorter than five minutes are only available with detailed monitoring, and periods shorter than one minute are only possible with custom metrics.
Statistics
Statistics are calculations used to aggregate data over the collection period. The following options are available: Minimum, Maximum, Sum, Average, SampleCount (the number of data points used for the aggregation), and pNN.NN. The pNN.NN aggregation returns any user-specified percentile, for example p95.00, which provides useful data for monitoring median values, outliers, and worst-case metrics.
Methods for collecting EC2 metrics
As mentioned above, there are several ways to use CloudWatch to view your EC2 metrics: via the AWS web console, via the AWS CLI, and via a third-party tool that integrates with the CloudWatch API.
Metrics via AWS console
The main CloudWatch page provides a few options for monitoring your AWS infrastructure. You can:
- browse available metrics for a quick overview of your instances,
- create dashboards to track multiple metrics, and
- set alarms to notify you if metrics pass fixed thresholds.
Browse metrics
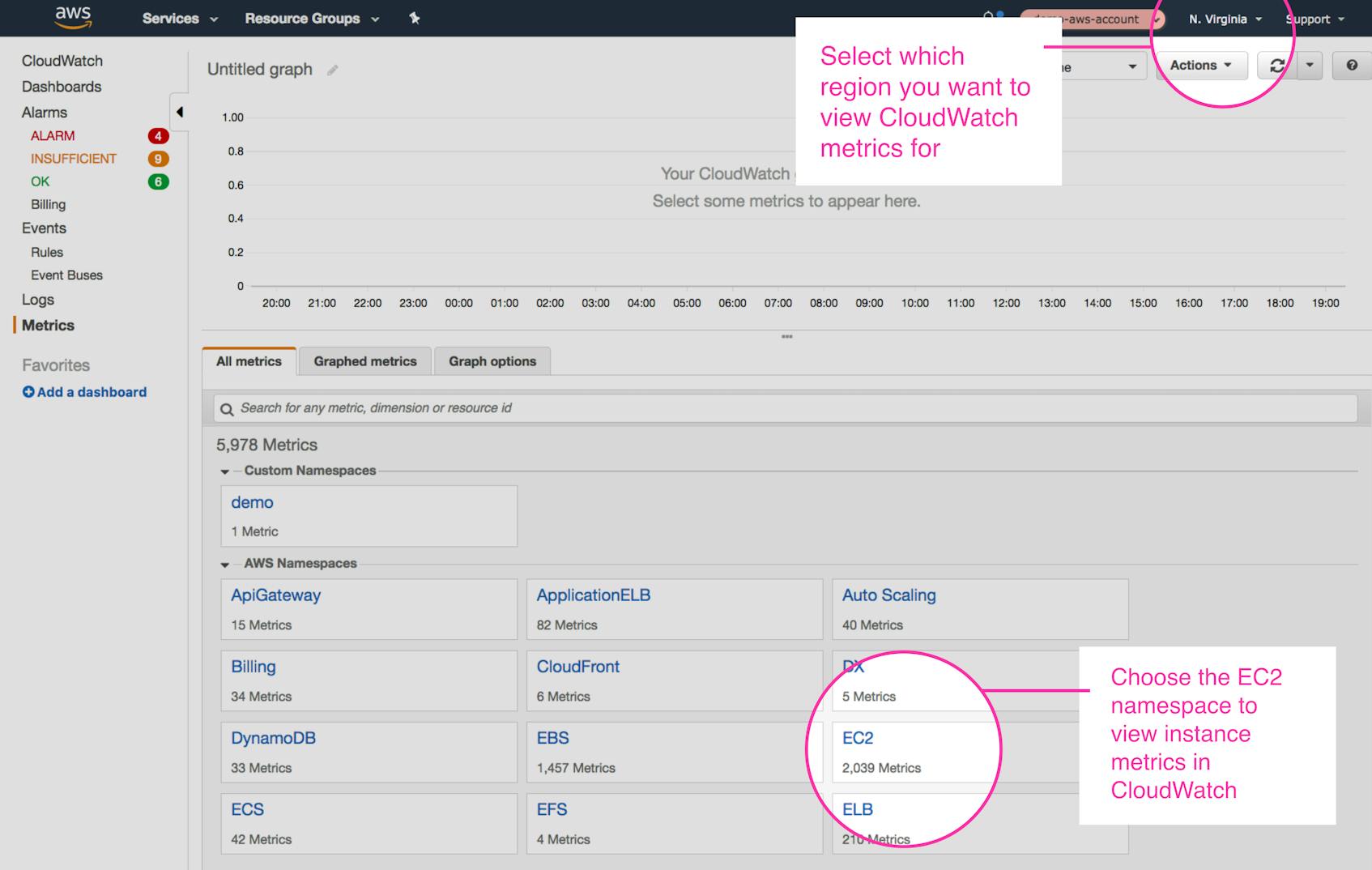
In the CloudWatch console, you can use the region selector to specify which region you want to view metrics for. Then, select any AWS namespace to see metrics from that service or source. Within the EC2 namespace, you can drill down to a dimension or single instance and choose which of the available metrics you want to graph.

The basic CloudWatch graph provides options for the time range you wish to view as well as the type of graph displayed—line, stacked graph, or a number graph that displays the metric’s current value. You can plot multiple metrics, from the same source or from different sources, on the same graph. So for example, you could view CPU usage for different instance types at the same time, or compare network throughput between Auto Scaling groups.
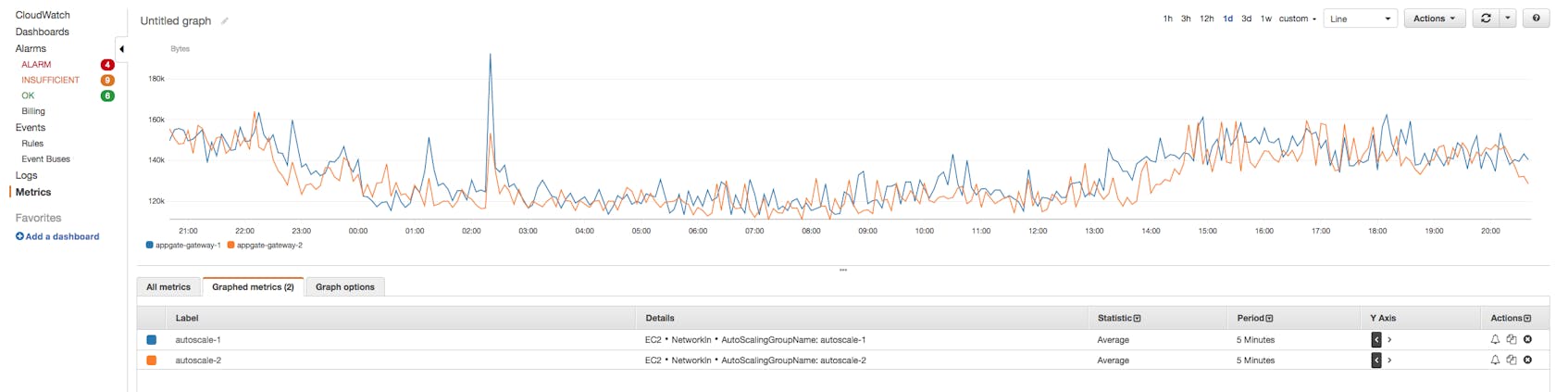
Dashboards
For a more comprehensive picture of your EC2 instances, you can create and save CloudWatch dashboards, which let you visualize multiple configurable graphs simultaneously. This is helpful for correlating instance metrics with each other and with data from other Amazon services. Dashboards provide the additional ability to change the metric aggregation period. You can also add metric graphs from different regions to the same dashboard.
Alarms
CloudWatch lets you create basic alarms on EC2 metrics. Alarms can be set against any upper or lower threshold and will trigger whenever the selected metric, aggregated across the specified dimension, exceeds (or falls below) that threshold for a set amount of time. In the following example, we are creating an alarm that will notify us whenever the average CPU utilization across all m3.medium instances equals or exceeds 90 percent over a five-minute window (one monitoring interval, under CloudWatch basic monitoring).
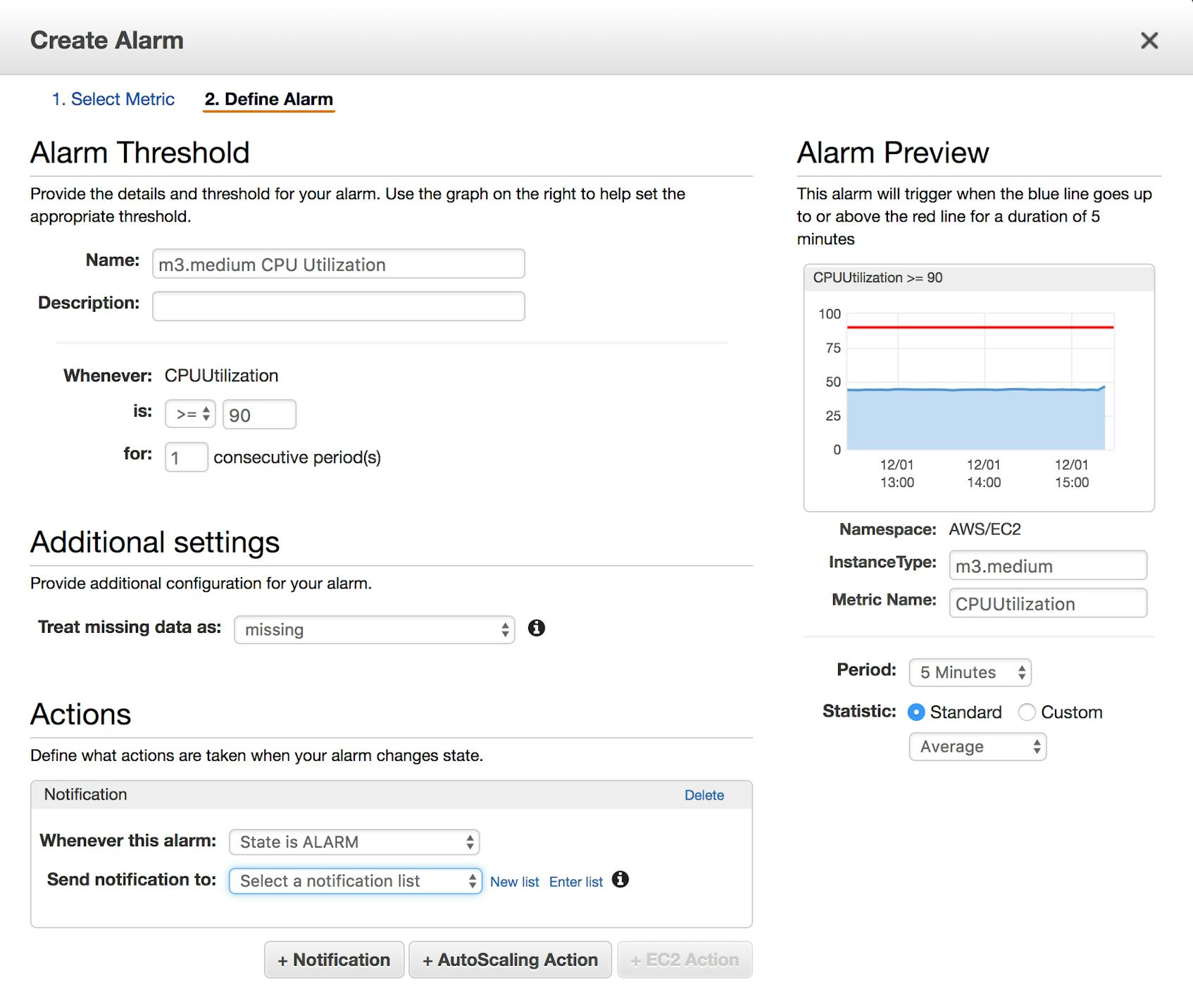
You can also set alarm actions such as stopping or rebooting instances when the alarm triggers. For example, you can create an alarm that stops any instance that has CPU utilization of less than 5 percent for an hour in order to avoid paying for unused resources.
Status checks
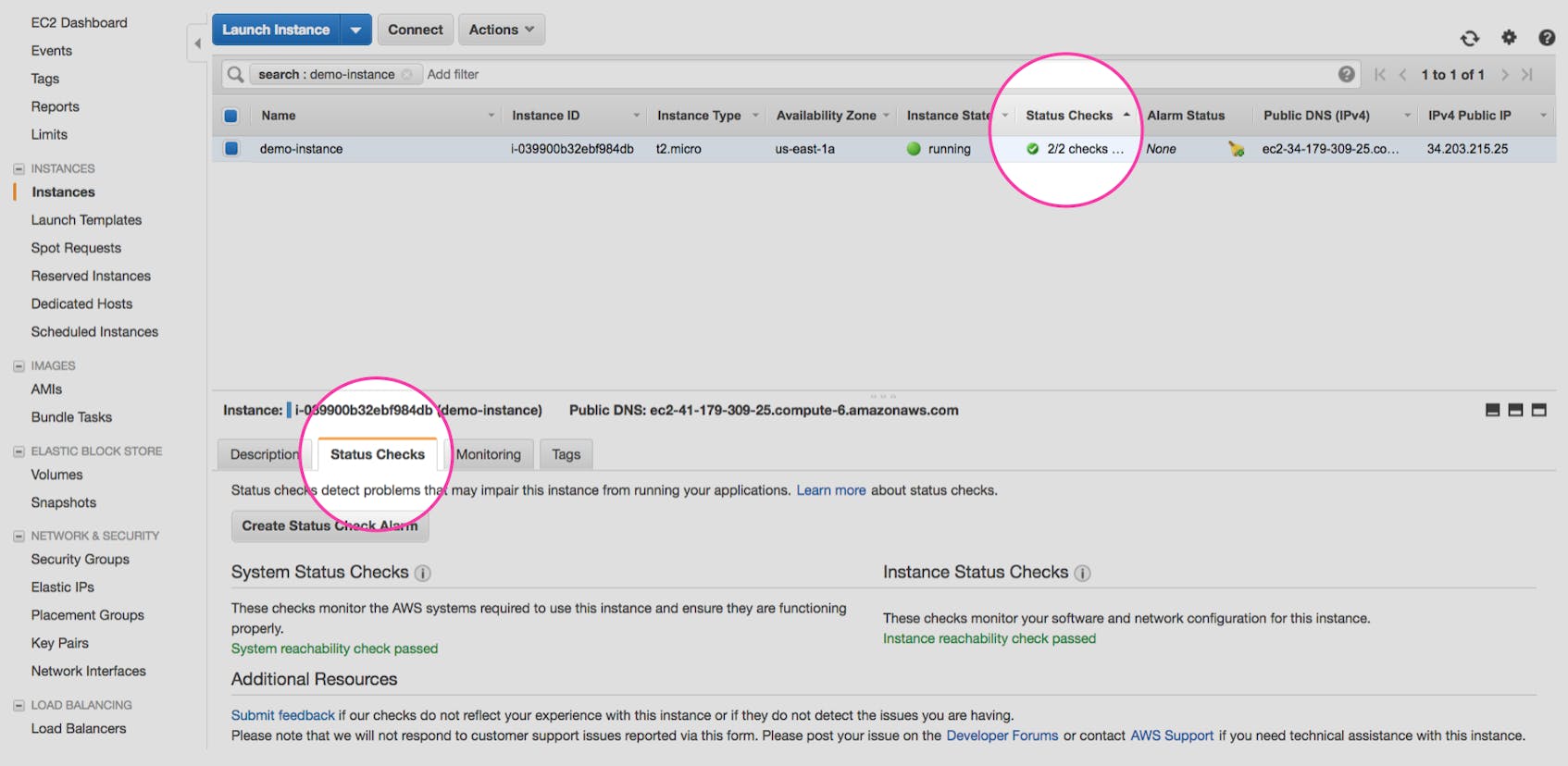
Instance status checks are reported from EC2 directly instead of through CloudWatch. So, you have to view them via the EC2 dashboard. The instance list view includes a quick summary of how many status checks each instance has passed. After selecting an instance, you can then click on the Status Checks tab in order to see specifically if both the system and instance checks have passed.
Metrics via CLI
Once you install the AWS CLI tool, you can query the full AWS API from the command line. The metrics and status checks described in the first part of this series fall under two different AWS namespaces, CloudWatch and EC2, so you’ll need two different CLI commands to request them. In both cases, you can specify which region you want to query in two ways. First, you can set the default region environmental variable, AWS_DEFAULT_REGION (this is also set when you initially configure the AWS CLI tool). Or second, you can include the --region parameter with the command.
EC2 metrics
Most EC2 metrics come from the CloudWatch namespace via the get-metric-statistics command. CloudWatch pulls metrics from other AWS services, so you must point the get-metric-statistics to the EC2 namespace so it knows which metrics you are requesting. In addition to namespace, the command requires four other parameters:
metric-namestart-time(ISO 8601 UTC format)end-time(ISO 8601 UTC format)period(in seconds)
You also must include either a statistics parameter, or the extended-statistics parameter if you want to specify a percentile. For example:
aws cloudwatch get-metric-statistics
--metric-name CPUUtilization
--start-time 2017-12-01T12:30:00
--end-time 2017-12-01T13:30:00
--period 900
--statistics Average
--namespace AWS/EC2
This requests average CPU usage across all instances within the default region (as no dimensions were included that would filter the search) for the specified hour with a granularity of 15 minutes. This will yield:
{
"Datapoints": [
{
"Timestamp": "2017-12-01T12:30:00Z",
"Average": 23.545234408687673,
"Unit": "Percent"
},
{
"Timestamp": "2017-12-01T13:15:00Z",
"Average": 23.607252374630786,
"Unit": "Percent"
},
{
"Timestamp": "2017-12-01T12:45:00Z",
"Average": 23.575792401181392,
"Unit": "Percent"
},
{
"Timestamp": "2017-12-01T13:00:00Z",
"Average": 23.639131672378156,
"Unit": "Percent"
}
],
"Label": "CPUUtilization"
}
Note that CloudWatch’s JSON response is not necessarily ordered chronologically when it returns more than one datapoint.
EC2 status checks
Instance status checks do not come from the CloudWatch namespace but instead are reported from the EC2 namespace using the describe-instance-status command. Without any parameters, this command will return the status and any associated events for all running instances (within the default region). You can include a list of one or more instance IDs, or you can provide a list of filters to return. For example, you can request only instances from a specific availability zone, or only instances that have an impaired instance status. The following command requests statuses for two specific instances via their instance IDs:
aws ec2 describe-instance-status --instance-ids i-07e36h4237d2as5hd i-0fw72f1c9e53d62r9
This returns:
{
"InstanceStatuses": [
{
"InstanceId": "i-0fw72f1c9e53d62r9",
"InstanceState": {
"Code": 16,
"Name": "running"
},
"AvailabilityZone": "us-east-1e",
"SystemStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
},
"InstanceStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
}
},
{
"InstanceId": "i-07e36h4237d2as5hd",
"InstanceState": {
"Code": 16,
"Name": "running"
},
"AvailabilityZone": "us-east-1e",
"SystemStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
},
"InstanceStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
}
}
]
}
If there are any scheduled events associated with the instance you are checking, those will also appear in the response to describe-instance-status.
Metrics via API
Amazon provides SDKs for major programming languages and mobile platforms to create applications and libraries that can communicate with AWS via specific APIs. A number of third-party monitoring products and tools take advantage of these APIs to pull and aggregate metrics automatically.
If you want to access the API directly, refer to the individual SDK documentation for information on how to make requests to the CloudWatch and EC2 namespaces for metrics and status checks. Amazon also supports a basic REST API that accepts HTTP and HTTPS requests.
Getting a fuller picture
CloudWatch provides a convenient way to collect EC2 metrics and get a general overview of the health of your instances, and it is fully integrated into the AWS ecosystem. But because it gathers metrics via a hypervisor instead of reporting from your instances themselves, it doesn’t collect all the resource metrics that you might want to keep an eye on, notably memory usage statistics.
One way to fill this gap is through the use of custom metrics, which you can forward to CloudWatch and monitor using the same methods outlined above. Additionally, custom metrics may be collected with much finer granularity—defaulting to one-minute resolution but with the ability to go as high as one second. (Note that fees will apply.) Amazon also provides sample scripts that use this custom metric mechanism to report memory, swap, and disk space statistics for Linux-based instances, although those scripts are not officially supported by AWS.
To gain deeper visibility into your instances, as well as your EC2-based applications and all the infrastructure components that support them, you can use a comprehensive monitoring service that integrates with EC2 and the rest of your stack. This provides a complete view into your infrastructure and applications, with the potential added benefit of increased resolution, because metric collection is not restricted by CloudWatch’s hypervisor.
In the third and final post of this series, you will learn how to use Datadog to set up comprehensive, high-resolution monitoring for your EC2 instances and the rest of your stack.
