

In modern systems, important logs can emerge from hundreds of different sources—in almost any format—and often change over time. This sheer variety can pose a challenge when you’re simply looking to leverage logs “off-the-shelf” for investigations, dashboards, or reports—especially when you don’t control the content and structure of certain logs (like those collected from third-party applications and platforms).
Meanwhile, teams’ analytical needs also continue to evolve in ways that can be difficult to predict. This makes the ability to easily process or reprocess data at query time incredibly valuable for on-call engineers tackling unique incidents, security analysts hunting for novel threats, and anyone else looking to perform in-depth investigations in highly dynamic environments.
Datadog is pleased to introduce Calculated Fields in the Log Explorer to give you more flexibility and control in these scenarios. All Log Management users now have the power to transform and enrich their log data on the fly during searches and investigations.
In this post, we’ll show you how Calculated Fields can be leveraged to unlock ad-hoc analysis, delve deeper into data, and quickly adapt to rapidly changing environments, as well as how to use Datadog to standardize and store data transformations long-term.
Unlock ad-hoc analysis and get to actionable insights faster
Often, to answer a specific question or gain previously obscured insights from existing data, you need to restructure or enrich it with new context. Imagine you’re an analyst tasked by an executive in your advertising department to measure and report on the success of a recent campaign. You’re advised that log data would be the best way to measure user activity and engagement.
Upon investigation, you find that the ad server is sending logs with users’ names split into separate @firstName and @lastName fields, making it hard to group and analyze data by user. You consider updating your log pipelines to restructure this data during ingestion, which would be helpful if you or others on your team wanted to perform this type of analysis again in the future.
But now you need to wait for the admin who owns the pipeline to review your request, bringing your investigation to a halt. More importantly, because pipeline changes only apply to new logs that stream in after the update, this does not actually solve your current predicament—you want to analyze historical data that’s already been processed.
Instead, you can easily “calculate” a more useful, formatted #fullName field by concatenating the separate firstName and lastName fields. Not only does this unblock your analysis, it allows you to improve and tailor the presentation of the data for your audience – which includes a mix of executives, technical users on your team, and non-technical users from the advertising department.
Delve deeper into data to take investigations one step further
Calculated Fields make it easy to add new dimensions to your logs on the fly right from the Log Explorer. For example, say you’re an SRE at a large e-commerce platform investigating a sudden increase in latency across your app. You navigate to the Log Explorer for more context on what might be causing the problem.
Your instinct is to look for actions that are taking longer than usual. When you open one of your application logs to inspect it though, you only find two timestamp attributes to work with, individually marking the beginning and end of the logged action. Typically, you might opt to download your logs at this point to perform further calculations or analysis in another tool (like a spreadsheet). Now you can do the math in Datadog and eliminate needless context switching.
By defining a simple formula: @end_time - @start_time, you’re able to directly calculate a brand new #DURATION field in mere seconds. Sorting your logs now immediately surfaces that your checkout service is the main culprit here.

To investigate further, you click through to the Service Catalog, which alerts you to the fact that the host running the checkout service is underprovisioned for CPU. With this knowledge in hand, you alert the service owner to the issue so they can remediate the problem.
Quickly adapt to rapidly changing environments
In scenarios where the ability to swiftly react to changes in your data, its context, or the underlying environment is critical, Calculated Fields can help you stay on top of things. For example, let’s say you’re a security officer alerted to an unanticipated spike in requests to download data from your company’s new CRM tool (which could be a sign of a data exfiltration attack). You start by looking for evidence in logs that points to any malicious activity but find that logs from the third-party software are relatively terse.
There are millions of logs to comb through, so you decide to focus on requests originating from outside the company’s network or place of business. Luckily, the logs do capture information about users’ “home office” location and their location at time of request. You quickly compare these values to flag requests made by users outside the office via the following formula:
if(@request_location == @home_office_location, “in office”, “unknown”)
This filters your dataset down to a quarter of its original size—still in the millions—and you realize it’s not the most effective filter on its own, as many employees now work from home regularly.
A helpful teammate points out that the amount of data being processed would be another useful parameter to filter by here, as larger requests are more likely to indicate aberrant or anomalous behavior—especially when you suspect unauthorized data transfer. You now reference the first #REQUEST_ORIGIN field in a new #SUSPICION field that incorporates this logic to help neatly categorize the requests by level of suspicion based on the two dimensions of interest:
if(#REQUEST_ORIGIN == "unknown" AND @rows_processed > 1000, "high", if(#REQUEST_ORIGIN == "unknown", "medium", "low"))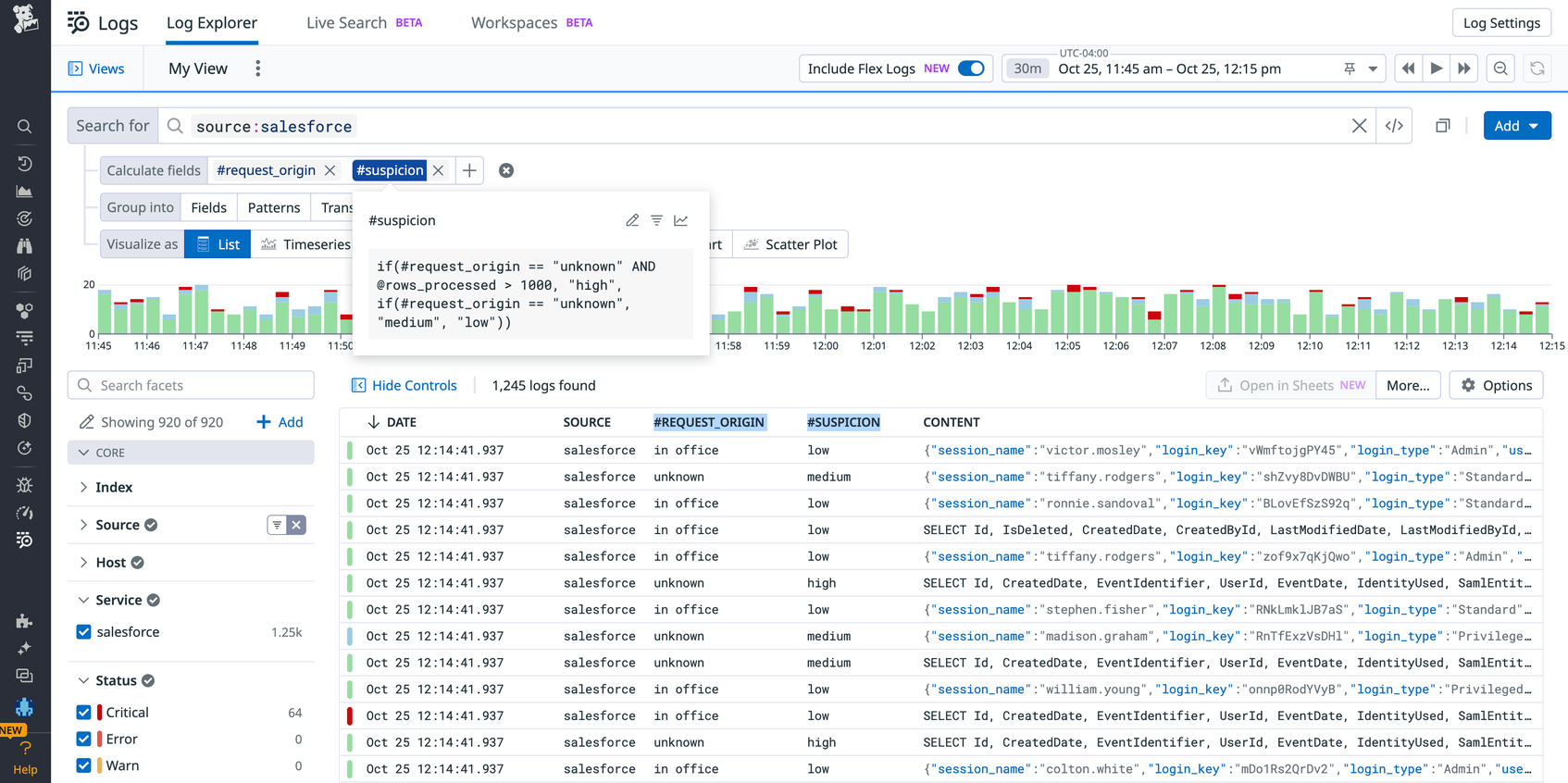
Now you can easily filter down to just the “high” suspicion requests and work with a much smaller set of data to complete your investigation.
Standardize and store data transformations long-term
Calculated Fields can help different members of your team—from non-technical users entirely unfamiliar with logging schemas to advanced power users whose demands of their data are constantly evolving—remodel log data on the fly to serve specific querying and reporting needs. In addition, Datadog enables you to standardize your logs’ processing, parsing, and transformation ahead of time via Pipelines. Our library includes 300+ out-of-the-box pipelines preconfigured to parse and standardize logs generated from commonly used technologies, such as AWS, Azure, and GCP.
Log Pipelines and Processors can also be customized, for example to store a data transformation achieved with a Calculated Field for long-term or team-wide reuse. Learn more about configuring ingestion time processing with log pipelines here.
Manipulate log data on the fly with Calculated Fields
Calculated Fields empower you to transform and enrich logs dynamically, in order to better support evolving analysis and reporting needs. This new feature is available to all Datadog Log Management users and works seamlessly with Flex Logs, making it easier to conduct historical investigations over up to 15 months of data and eliminating the overhead of having to reprocess your logs.
If you’re new to Datadog, sign up for a 14-day free trial.
