Identifier rapidement les problèmes de performance des applications
- Visualisez en détail les performances du code de votre application grâce au tracing de bout en bout, aux analyses détaillées de la latence et aux flamegraphs présentant les détails au niveau de la requête
- Adoptez un déploiement Canary ou bleu/vert, voire une autre stratégie de déploiement en suivant automatiquement l'évolution des performances avant, pendant et après la publication de l'application
- Résolvez les incidents actifs plus rapidement grâce aux service maps en temps réel et aux alertes liées aux problèmes de performance au niveau du code et du service
- Détectez rapidement la source des problèmes rencontrés par le service par le biais d'une vue regroupant les métriques de santé et les dépendances, ainsi que les données de télémétrie de votre infrastructure et de vos bases de données
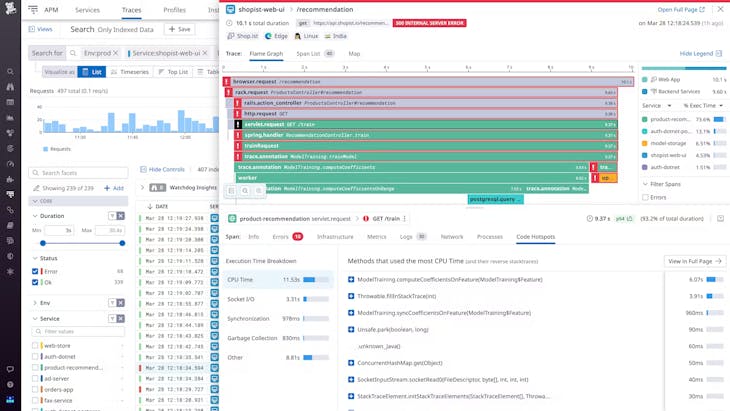
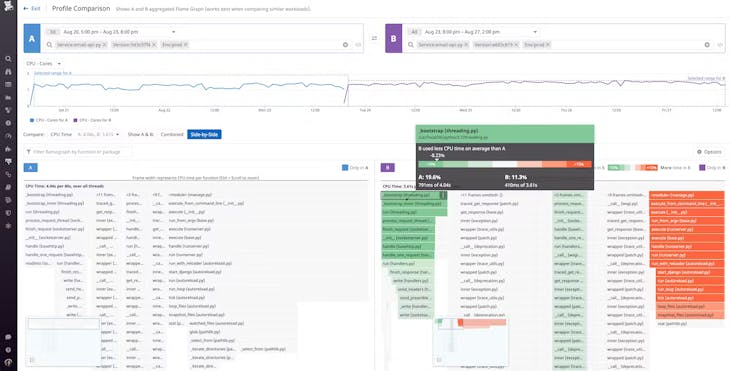
Optimiser le code de production pour des performances, une rentabilité et une efficacité accrues
- Analysez l'intégralité de votre code exécuté en production, notamment les méthodes, les classes et les threads sur l'ensemble de votre pile
- Basculez facilement entre différents profils et traces distribuées d'un simple clic, tout en bénéficiant d'un délai de résolution inégalé de 10 000 événements au niveau des threads par minute
- Obtenez des informations pertinentes et examinez facilement les exceptions, la parallélisation, les deadlocks, le nettoyage de la mémoire ainsi que les I/O, avec une analyse détaillée continue par pile d'appels, stack trace et flamegraph
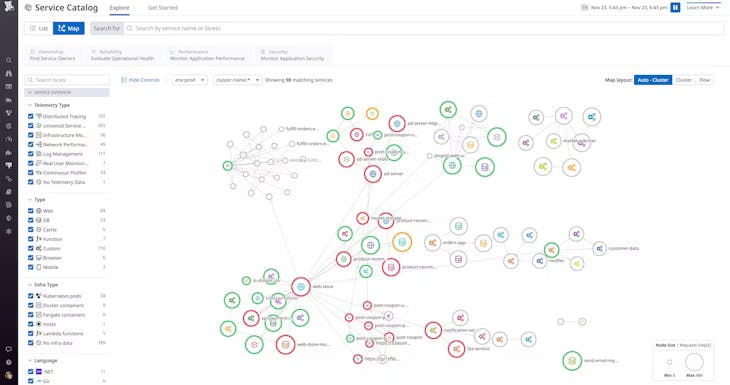
Découvrir, mapper et surveiller instantanément chaque service, sans modifier le code
- Éliminez les angles morts du système en détectant automatiquement l'ensemble de vos services, qu'ils vous appartiennent ou soient fournis par des tiers, sans instrumenter du code
- Améliorez la fiabilité de l'application et formalisez l'adoption des bonnes pratiques DevSecOps pour renforcer la collaboration entre les équipes
- Visualisez instantanément la santé de chaque service et dépendance par le biais de métriques RED en temps réel et de données de télémétrie corrélées automatiquement
- Détectez les problèmes plus rapidement avec une source unique de données d'observabilité et de SLO standardisés pour toutes les équipes d'une organisation
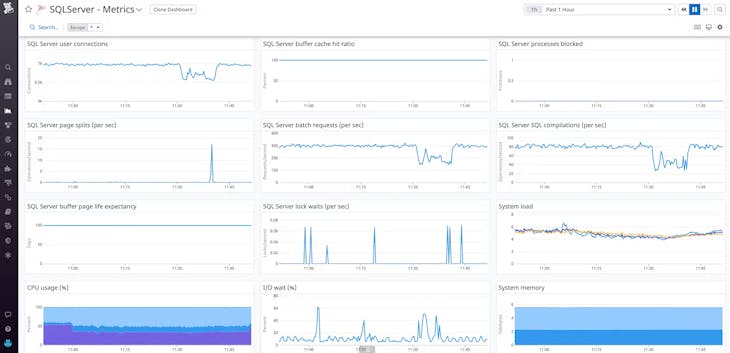
Surveiller les performances des bases de données à grande échelle
- Isolez les problèmes de performance des requêtes SQL en quelques secondes en visualisant les métriques de requêtes et les plans d'explications au fil du temps
- Surveillez toutes vos bases de données ainsi que vos services cloud, conteneurs et fonctions sans serveur au même endroit grâce aux plus de 650 intégrations de Datadog soutenues par les fournisseurs
- Diagnostiquez rapidement les causes profondes et détectez les comportements anormaux sur l'ensemble de vos systèmes en faisant corréler automatiquement les requêtes de bases de données avec les traces et métriques d'infrastructure
- Adaptez et gérez un grand nombre de bases de données tout en protégeant vos données sensibles
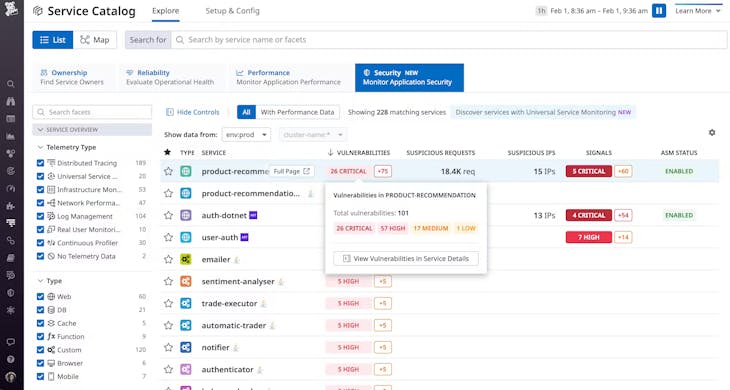
Protection intégrale pour l'ensemble des applications, des charges de travail et de l'infrastructure
- Suivez facilement votre posture de sécurité grâce à des fonctionnalités prêtes à l'emploi, comme l'activité des menaces, l'exposition et le score de gravité de Datadog
- Triez les vulnérabilités selon leur impact dans un contexte global à l'aide de scans de runtime continus sur les bibliothèques tierces
- Résolvez les problèmes au moyen d'outils d'aide concrets prêts à l'emploi et de la corrélation automatique entre l'application et l'infrastructure
- Renforcez la collaboration en adoptant une seule et même langue au sein des équipes chargées du développement, des opérations et de la sécurité
Témoignage client
Lifion by ADP utilisait auparavant plusieurs outils de surveillance pour les alertes, le tracing, etc., entraînant des coûts de maintenance annuels d’un montant total de 2,1 millions de dollars. Grâce à Datadog, ADP a pu consolider ses solutions de surveillance et réduire le temps passé à gérer des outils cloisonnés. Ces changements ont permis de réaliser une économie nette de 647 000 dollars par an, ce qui représente une diminution de 30 % des coûts informatiques totaux de l’entreprise.
$647K
Économies nettes annuelles
30%
Diminution des coûts informatiques totaux