

Most modern platforms like AWS and Kubernetes create dynamic environments by quickly spinning up instances or containers with significantly shorter lifespans than physical hosts. In these environments, where large-scale applications can be distributed across multiple ephemeral containers or instances, tagging is essential to monitoring services and underlying infrastructure.
For example, the sample architecture below shows application services that are comprised of several different components: containers, Lambda functions, and other hosted tools.
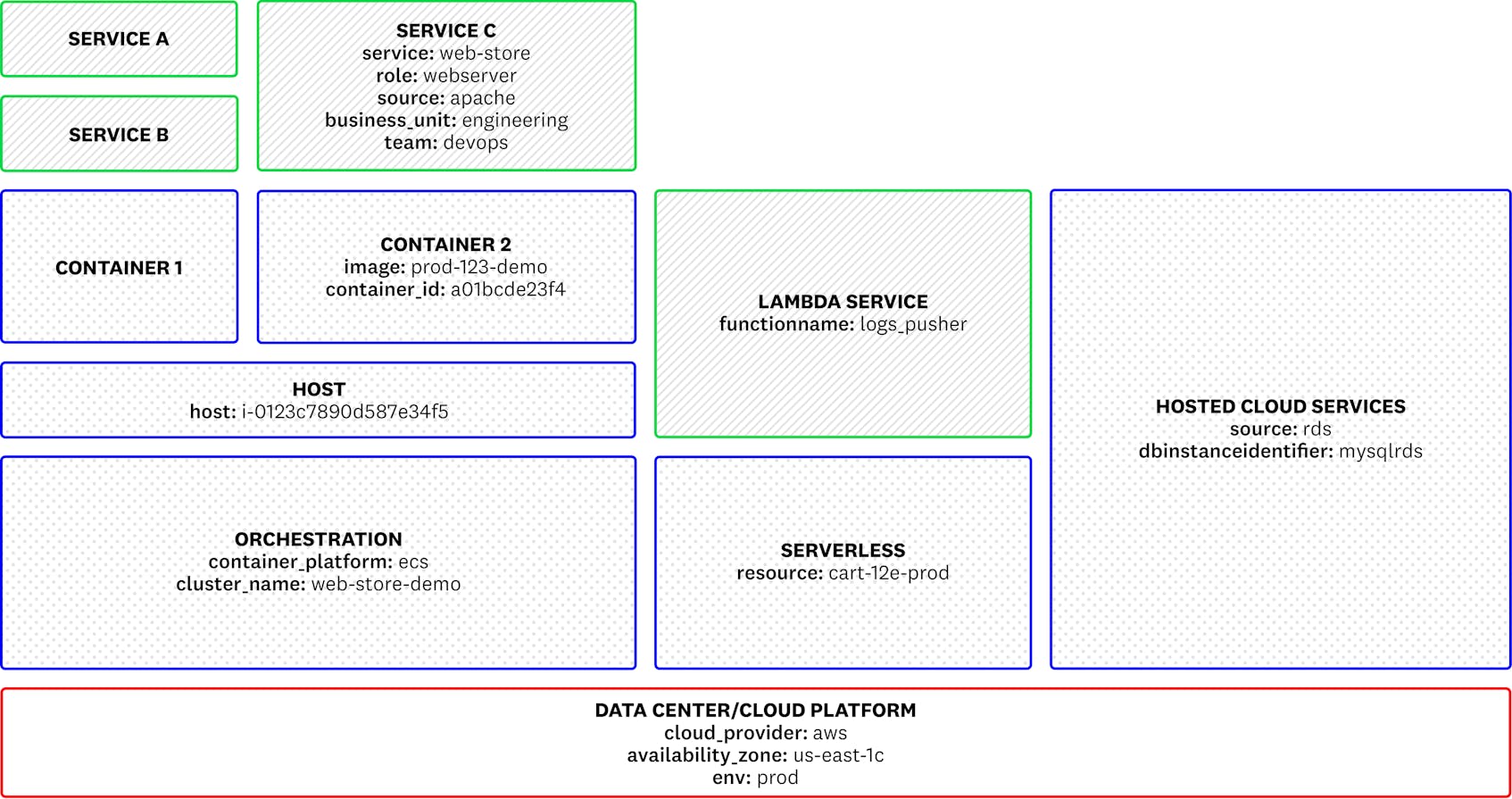
Tagging these individual components provide context for your services, enabling you to not only see your entire infrastructure, but also to isolate individual services for more comprehensive analysis. For example, you can use tags to view high-level metric data for all services deployed to a specific region in AWS or view logs for a single service hosted on a specific container. Without proper tagging, monitoring these complex systems can quickly become ineffective.
In this post, we’ll discuss some tagging best practices for your applications and application services and how you can use tags to:
- map your infrastructure with your collected tags
- unify your data streams to pivot between service metrics, logs, and request traces
- assign owners to services and build informative alerts that automatically route notifications to teams
- use primary tags to aggregate performance metrics
With tags, you can organize complex data streams (regardless of role, environment, or location), and quickly search for, aggregate, and pivot between data points.
Collect all available metadata from your infrastructure
Tags are typically key:value pairs or simple values (e.g., “file-server”, “database”) that add dimension to application performance data and infrastructure metrics. Most modern platforms and configuration management tools like AWS, Kubernetes, and Chef can automatically generate their own tags. Before you begin monitoring with Datadog, it’s important to take advantage of the tagging capabilities that your platforms offer as Datadog automatically imports these tags via its integrations.
Using the standard or recommended list of tags from your providers will ensure consistency in identifying your hosts and services. Letting Datadog automatically import tags is one of the most powerful ways you can begin monitoring your systems. With this, you can immediately understand and correlate key performance data across hosts, containers, and services. In an ephemeral infrastructure, these tags can automatically group and categorize your resources as they are created.
Let’s look at a few examples.
AWS
AWS provides tools for configuring tags across all of your EC2 resources and can apply a set of tags to each instance. AWS offers suggested tagging strategies for their resources, but some common AWS infrastructure tags include:
- #account
- #autoscaling-group
- #availability-zone
- #image
- #instance-type
- #instance-id
- #name
- #region
Datadog will automatically collect and assign these tags to your resources, as seen in the example below.
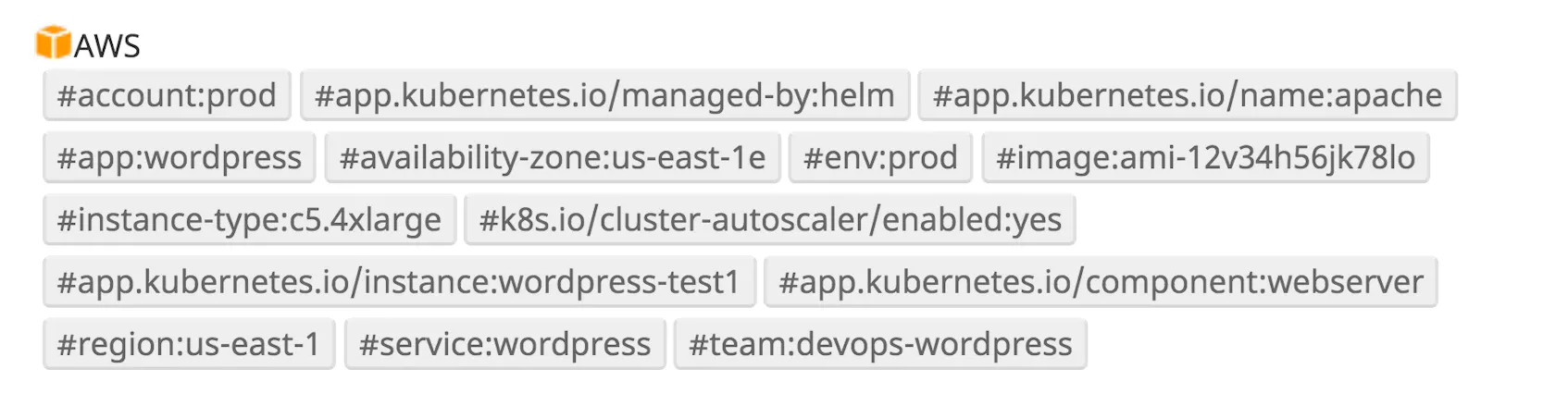
AWS tags help identify the types of resources running your services as well as their physical locations. These identifiers are invaluable if you are managing resources across multiple regions or availability zones. Production servers, for example, are typically deployed across several regions in order to build more resilient systems. When there is an outage with a service provider in a specific region (i.e., us-west-2), the region tag can help you quickly search for the affected resources in that area.
Kubernetes (k8s)
If you use Kubernetes for managing services, you can collect key metadata from your pods, including the common recommendations for labels:
- #component
- #instance
- #managed-by
- #name
- #os
- #part-of
Datadog can automatically discover and ingest labels and annotations as tags and apply them to all of the metrics, traces, and logs emitted by your pods and nodes. This also includes extracting any environment variables as tags for a containerized Agent.
As with the other platform tags Datadog automatically collects, this enables you to quickly visualize and monitor your clusters without the need to apply additional tags upfront. You can easily view your tags in the container map, as seen in the example below, and use them to search and filter your logs and dashboard data.

Visualize your infrastructure with the host map
With the tags from your service providers (e.g., AWS, Kubernetes), you can see a high-level view of your infrastructure and drill down to individual hosts, containers, or clusters through Datadog’s host maps. The host map enables you to quickly view host-related metrics across your infrastructure and further organize your hosts by grouping and filtering by tags (note that the container map does the same for your containers). For example, if you need to see the distribution of hosts for an autoscaling group across availability zones, you can filter the map to visualize only that autoscaling group, and then group those hosts using the availability-zone tag, which was applied by AWS and automatically ingested by Datadog.
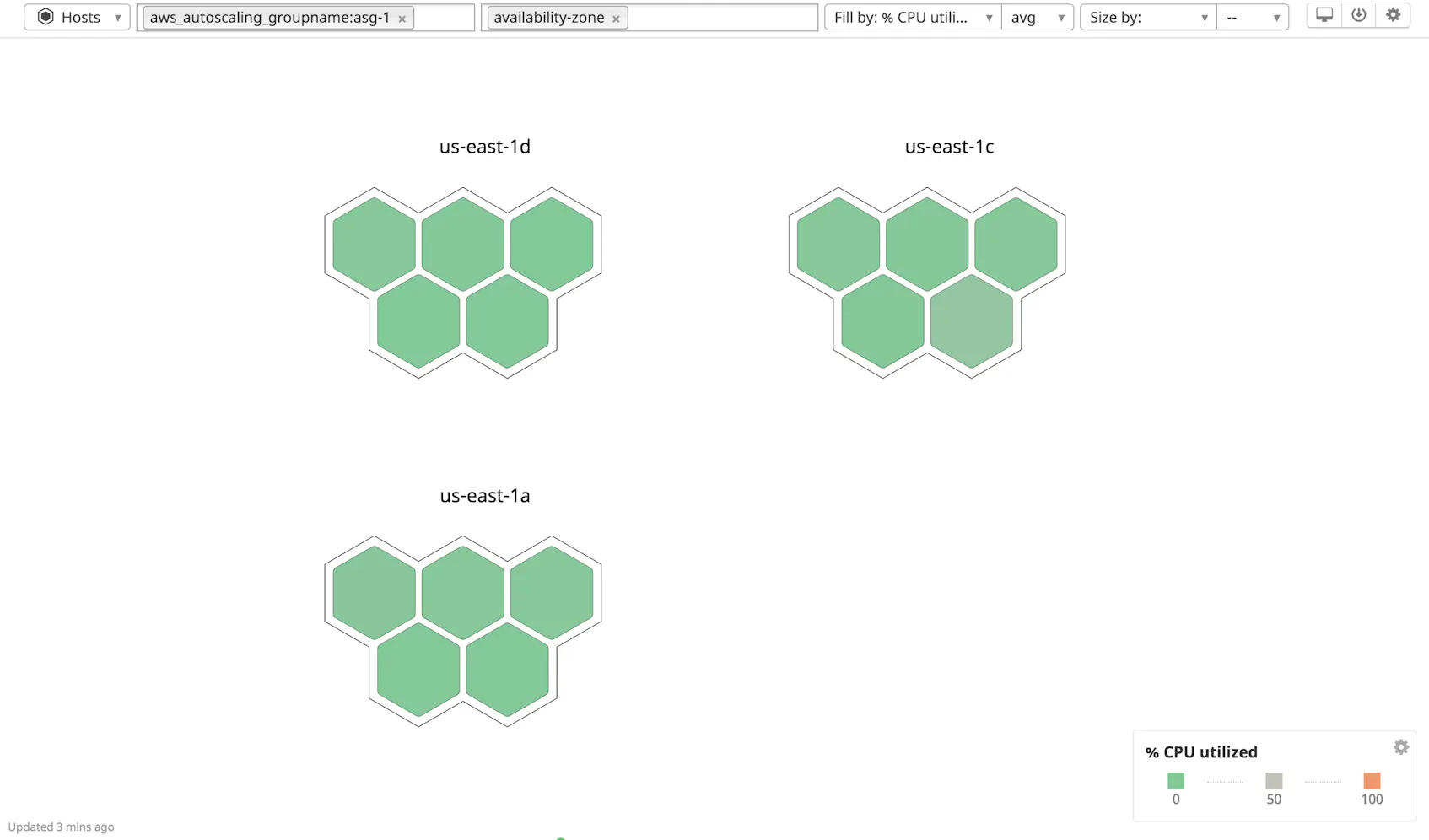
Through integration inheritance, Datadog automatically organizes your infrastructure by collecting all of the tags from your cloud providers, container platforms, or configuration management tools. You can immediately see your hosts and gain insight into how each part of your infrastructure fits together.
Correlate all of your data, troubleshoot faster
Integration inheritance is one of the recommended ways to ingest tags with Datadog to quickly categorize your infrastructure. But you can also assign custom tags to your infrastructure by adding them to the Datadog Agent’s configuration file (i.e., datadog.yaml) and any integration configuration file located in the conf.d directory of your Agent installation.
Along with the tags that Datadog automatically ingests, your custom tags play a critical role in organizing dynamic infrastructure and unifying all of your metric, trace, and log data emitted from those ephemeral resources. Datadog seamlessly interconnects all of your performance data through tags, so you can correlate, analyze, and alert on any data point for your organization. This enables you to troubleshoot issues faster and easily understand how individual services fit into the bigger picture.
When users report slow load times for your application, you need to be able to quickly see which dependency is causing the problem (e.g., web server, database). Tags can help you sift through all of your application data and identify the cause of the issue, such as a slow database query. Then you can easily pivot to related database logs to view the problematic query.
In the next few sections, we will show how you can use all of your tags (inherited and custom) to correlate application data through:
- grouping hosts by location and environment
- categorizing application services by their functions
- assigning and identifying service owners
Add scope to your applications

You can provide additional scope to all of your hosts and services by associating them with an environment or location such as a data center. A global env tag is useful not only for separating data by infrastructure environments (such as development, staging, and production), but also for providing a high-level view of your infrastructure. For instance, when an issue arises in production, you only care about the services and hosts in that environment, so this tag allows you to quickly filter out the noise. You can also use an env tag to ensure that you only get paged for real issues in production.
Tagging by data center (e.g., datacenter: us1.prod) gives you more control over the types of environments you manage. Being able to quickly group or filter hosts by data center can be critical for disaster recovery plans and data center failovers. Additionally, using collected platform tags such as the cloud provider (e.g., cloud_provider: aws) can also help with scaling your architecture and ensuring that resources are the appropriate size. This is also critical to managing the costs of a growing infrastructure.
Your custom tags immediately provide scope to your hosts. They give you a high-level view of your infrastructure so you can quickly see if an issue affects a single host or a whole cluster.
Explore your hosts by environment and location
As with the tags ingested from providers such as AWS and Kubernetes, you can see how a subset of hosts are distributed across a specific environment, location, or provider. You can subdivide your hosts further by adding a second grouping tag. In the example below, hosts are divided by datacenter and then further grouped by the availability-zone tag, which is automatically collected by Datadog.

Your host-level tags—custom and automatically collected from your providers—help you categorize and understand how your application operates across environments and locations. In addition to tagging your hosts, you can assign tags to your individual services so that you can quickly drill down to a specific application component and monitor related metrics, logs, and traces.
Categorize services by function

As with categorizing services at the host level, tags can add dimension to your data at the service level, giving you multiple angles for viewing your application data. You can connect every component that supports your application (e.g., web servers, databases, message brokers) together by grouping them by their function or business role. As seen in the example tagging scheme below, you can categorize application data by the name of a service, the website it supports, and its primary role.
service: web-store
site: web-store.staging
role: webserver
This enables you to search on several dimensions in Datadog: just the service, all services associated with a site, or all web servers in your infrastructure. In addition to their function, you can categorize services by their business role so you can manage cost allocation.
business_unit: internal-processing
cost_center: internal-processing-01
You can also create tags based on a customer region in order to pinpoint the subset of users affected by a service outage:
customer_region:eu
By applying business-specific tags to your infrastructure, you can make informed decisions about scaling your systems to meet budget or client demands. You can search on or filter by each of these tags (or combine them) to easily view performance data based off function or business role. We’ll walk through how you can use these tags in Datadog next.
View application architecture and dependencies
Service tags let you view all of the services related to a specific environment (or location) through Datadog’s service map, if you’ve enabled trace collection for your application. The service map breaks down your application into its individual component services and links them based on dependency.
In the example service map below, you can see request latency and error counts for the web-store service as well as all of its dependencies, filtered by environment. From this view, you can step through each service dependency or pivot to related logs or traces by clicking on a node.

To view key metrics across multiple services, you can combine your environment and platform tags like those collected from AWS to quickly search for data in dashboards. For example, you can monitor average CPU usage across specific hosts by filtering by the name tag and grouping by instance-type.

If you notice an issue in your service maps or dashboards, you can troubleshoot by pivoting to logs or traces for a single service or metric. In the next section, we’ll show how you can easily pivot from one datapoint to another for seamless troubleshooting.
Pivot between request traces, logs, and metrics
Datadog uses tags to automatically correlate your data so you can seamlessly pivot between dashboards, logs, and traces. The service tag automatically links metrics, logs, and traces from each service so you can monitor and troubleshoot application performance, while the source tag links metrics and related logs from a particular infrastructure technology. Dashboards can provide an overview of your systems and help you monitor unusual activity in your services. If you notice a resource usage spike in one of your dashboards (as seen in the example below), you can click on the datapoint in the graph and easily jump to related logs in the Log Explorer.

Datadog populates the search query with the same tags associated with your dashboard. Similarly, you can select a log entry and jump to host-level metrics, service-level request traces, and integration dashboards for the designated source.

Or you can search for trends in request traces across your application with the Trace Explorer using the same set of tags. Trace Explorer also enables you to view top-level performance metrics for your requests, such as request count, error count, and request latency.

Datadog automatically applies tags generated by your service providers to your traces, in addition to your custom tags. You can drill down to specific traces and immediately pivot back to viewing host metrics and logs, giving you greater visibility into the problem.
When you tag your systems, you create meaningful connections to your application data so you can pivot between all datapoints in Datadog. Tags also increase efficiency as you can create fewer dashboards and utilize tag filters to see more information in one place. Not only do these connections simplify monitoring and create a complete picture of application activity, they can be included in dynamic alerts so that you can be aware of issues from infrastructure components and services as they happen.
Assign owners to services with tags
If your services are supported by multiple teams, departments, or business units, you can use the Service Catalog and its metadata schema to document any necessary service owners, team contacts, and on-call personnel. The Service Catalog also improves the on-call experience for your teams by enabling you to link services to relevant runbooks and dashboards. This critical information creates the appropriate ownership and communication channels for your services, alongside easy access to monitoring and troubleshooting details.

The application and team tags in the Service Catalog allow you to group your service topology map and get a clear picture of service ownership and application dependencies. This is particularly useful as it enables visualization of complex microservice architecture on a more granular level to help organizations quickly reach the information they need.

The following example snippet shows how you can specify important ownership and operational information through the Service Catalog:
---
schema-version: v2.2
dd-service: web-store
team: shopist
application: shopist
description: shopist.com storefront
tier: tier1
lifecycle: production
links:
- name: Demo Dashboard
type: dashboard
url: https://app.datadoghq.com/dashboard/abc-123-cde
- name: Common Operations
type: runbook
url: https://shopist.com/wiki/
- name: Disabling Deployments
type: runbook
url: https://shopist.com/wiki/
- name: Rolling Back Deployments
type: runbook
url: https://shopist.com/wiki/
- name: Source
type: repo
provider: github
url: https://github.com/shopist/shopist-demo/tree/prod/web-store
- name: Deployment
type: repo
provider: github
url: https://github.com/shopist/blob/prod/k8s/web-store-deployment.yaml
- name: Deployment Information
provider: link
type: doc
url: https://docs.datadoghq.com/
- name: Service Documentation
provider: link
type: doc
url: https://docs.datadoghq.com/
ci-pipeline-fingerprints: ["123abc456def", "1234qwerasdf", "1a2s3d4f5g6h"]
tags: []
integrations:
pagerduty:
service-url: https://shopist.pagerduty.com/service-directory/XXXXXXXYou can also add tags based on distribution emails or Slack channels so you can build alerts that will automatically send notifications to that distribution list or to the right team in Slack. For the example below, core-experience@shopist.com is the email alias for the distribution group and https://shopistincidents.slack.com/archives/123 is a Slack channel.
contacts:
- type: slack
contact: https://shopistincidents.slack.com/archives/123
- type: email
contact: "core-experience@shopist.com"With the information provided by the Service Catalog, you can also build powerful, dynamic alerts in Datadog with tag variables. Tag variables enable you to include more detailed information about the instance(s) or service that triggered an alert, dynamically populated from your tags.
Create automatic, dynamic alerts for your team

These tags can provide important context for troubleshooting, as well as automatically notify the teams assigned to a specific service, host, or cluster of hosts.
Your infrastructure and service tags become especially powerful for creating multi alerts. Instead of manually creating separate alerts for each team or host or service in your infrastructure, you can let Datadog automatically trigger separate alerts with the appropriate tags, links, and notification mentions using a single alert template.
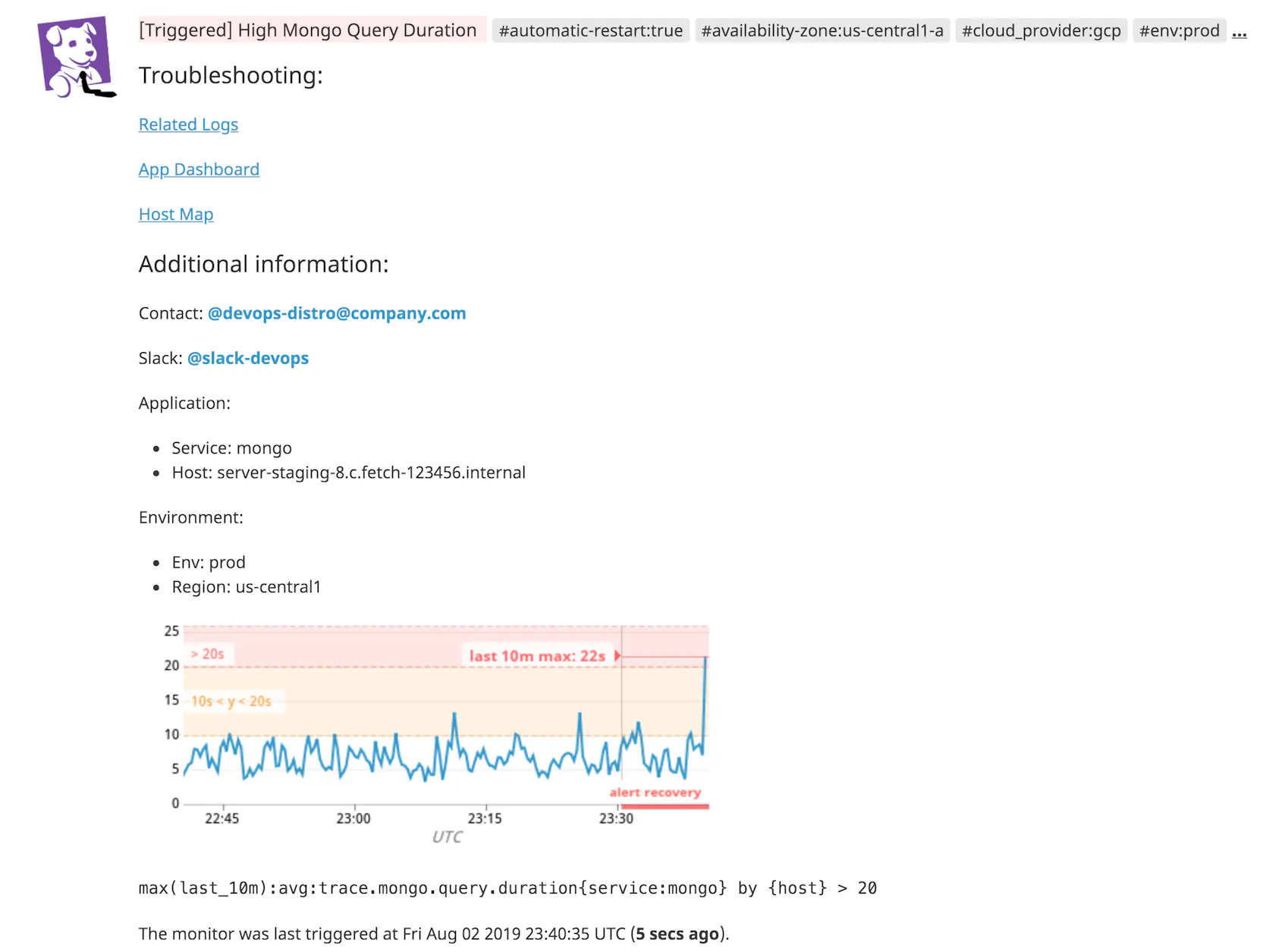
In the example below, we are creating a threshold multi alert for every host that reports the trace.mongo.query.duration metric. If this metric reaches the specified thresholds (e.g., alert, warning) for any host, Datadog will automatically trigger separate alerts for each affected host.

You can automatically notify team members or post a message to a Slack channel by adding a templated @-mention to an alert’s message that populates based on the tagged service owner.
The example alert below will automatically route notifications to the appropriate team distribution list and Slack channel. Check out the documentation for more information on alert notifications.

In addition to notifying team members of an issue, you can use tag variables to provide responders with targeted links to a specific dashboard, host map, or log search that is relevant to the alert. In the example alert message below, we replaced tags in the URL query strings for an application dashboard with the {{host.availability-zone}} and the {{host.env}} tag variables.

When the alert is triggered, the tag variable values will dynamically fill to match the tags that are associated with the affected host. In the previous example, the link in the alert will route you to a custom dashboard that is automatically pre-scoped with the host’s environment and availability zone. You can also use tag variables in links to route to custom trace and log searches.
Not only does this allow your teams to quickly pinpoint the root cause of an issue, it lets you create alerts that provide the most value to your organization. Each triggered alert will include relevant information for the affected host, which you can review on the Monitor Status page, in addition to email and Slack.
Configure primary tags to easily aggregate performance metrics
If you want to aggregate application performance metrics by tags like env or kube_cluster, you can configure primary tags. These tags give you access to several available dimensions for scoping an APM application so you have a more complete view of its behavior. To get started, you can configure host-based primary tags on the APM settings page and enable container-based primary tags in the Datadog Agent’s configuration file. Datadog calculates trace metrics based on 100 percent of an application’s traffic and applies aggregations pre-sampling. For best results, we recommend using tags with relatively low cardinality, such as availability-zone or datacenter as your primary tags.
Easily troubleshoot issues with tags
Tagging is essential for monitoring application data in modern, dynamic environments. Tags unify your metric, log, and trace data so that you can search for hosts and their services and easily move from one data point to another. By tagging each component of your stack—both with custom tags and the tags generated by service providers like AWS—you provide context to each moving piece of your application.
With Datadog, you can easily collect all of your infrastructure and service tags and visualize how your application components interact. By applying some of these best practices for tagging your systems and using them in Datadog, you can be more proactive in addressing issues before they impact customers.
Get started with tagging and monitoring your application with Datadog today by signing up for a free trial. If you already have an account, then you can learn more about tagging in Datadog in our documentation, or how you can standardize tags across your services.
