

This post is part 1 of a 3-part series about MySQL monitoring. Part 2 is about collecting metrics from MySQL, and Part 3 explains how to monitor MySQL using Datadog.
What is MySQL?
MySQL is the most popular open source relational database server in the world. Owned by Oracle, MySQL is available in the freely downloadable Community Edition as well as in commercial editions with added features and support. Initially released in 1995, MySQL has since spawned high-profile forks for competing technologies such as MariaDB and Percona.
Key MySQL statistics
If your database is running slowly, or failing to serve queries for any reason, every part of your stack that depends on that database will suffer performance problems as well. In order to keep your database running smoothly, you can actively monitor metrics covering four areas of performance and resource utilization:
MySQL users can access hundreds of metrics from the database, so in this article we’ll focus on a handful of key metrics that will enable you to gain real-time insight into your database’s health and performance. In the second part of this series we’ll show you how to access and collect all of these metrics.
This article references metric terminology introduced in our Monitoring 101 series, which provides a framework for metric collection and alerting.
Compatibility between versions and technologies
Some of the monitoring strategies discussed in this series are specific to MySQL versions 5.6 and 5.7. Differences between those versions will be pointed out along the way.
Most of the metrics and monitoring strategies outlined here also apply to MySQL-compatible technologies such MariaDB and Percona Server, with some notable differences. For instance, some of the features in the MySQL Workbench, which is detailed in Part 2 of this series, are not compatible with currently available versions of MariaDB.
Amazon RDS users should check out our specialized monitoring guides for MySQL on RDS and for the MySQL-compatible Amazon Aurora.
Query throughput

| Name | Description | Metric type | Availability |
|---|---|---|---|
| Questions | Count of executed statements (sent by client) | Work: Throughput | Server status variable |
| Com_select | SELECT statements | Work: Throughput | Server status variable |
| Writes | Inserts, updates, or deletes | Work: Throughput | Computed from server status variables |
Your primary concern in monitoring any system is making sure that its work is being done effectively. A database’s work is running queries, so your first monitoring priority should be making sure that MySQL is executing queries as expected.
MySQL has an internal counter (a “server status variable”, in MySQL parlance) called Questions, which is incremented for all statements sent by client applications. The client-centric view provided by the Questions metric often makes it easier to interpret than the related Queries counter, which also counts statements executed as part of stored programs, as well as commands such as PREPARE and DEALLOCATE PREPARE run as part of server-side prepared statements.
To query a server status variable such as Questions or Com_select:
SHOW GLOBAL STATUS LIKE "Questions";
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Questions | 254408 |
+---------------+--------+
You can also monitor the breakdown of read and write commands to better understand your database’s workload and identify potential bottlenecks. Read queries are generally captured by the Com_select metric. Writes increment one of three status variables, depending on the command:
Writes = Com_insert + Com_update + Com_delete
Metric to alert on: Questions
The current rate of queries will naturally rise and fall, and as such it’s not always an actionable metric based on fixed thresholds. But it is worthwhile to alert on sudden changes in query volume—drastic drops in throughput, especially, can indicate a serious problem.
Query performance

| Name | Description | Metric type | Availability |
|---|---|---|---|
| Query run time | Average run time, per schema | Work: Performance | Performance schema query |
| Query errors | Number of SQL statements that generated errors | Work: Error | Performance schema query |
| Slow_queries | Number of queries exceeding configurable long_query_time limit | Work: Performance | Server status variable |
MySQL users have a number of options for monitoring query latency, both by making use of MySQL’s built-in metrics and by querying the performance schema. Enabled by default since MySQL 5.6.6, the tables of the performance_schema database within MySQL store low-level statistics about server events and query execution.
Performance schema statement digest
Many key metrics are contained in the performance schema’s events_statements_summary_by_digest table, which captures information about latency, errors, and query volume for each normalized statement. A sample row from the table shows a statement that has been run twice and that took 325 milliseconds on average to execute (all timer measurements are in picoseconds):
*************************** 1. row ***************************
SCHEMA_NAME: employees
DIGEST: 0c6318da9de53353a3a1bacea70b4fce
DIGEST_TEXT: SELECT * FROM `employees` WHERE `emp_no` > ?
COUNT_STAR: 2
SUM_TIMER_WAIT: 650358383000
MIN_TIMER_WAIT: 292045159000
AVG_TIMER_WAIT: 325179191000
MAX_TIMER_WAIT: 358313224000
SUM_LOCK_TIME: 520000000
SUM_ERRORS: 0
SUM_WARNINGS: 0
SUM_ROWS_AFFECTED: 0
SUM_ROWS_SENT: 520048
SUM_ROWS_EXAMINED: 520048
...
SUM_NO_INDEX_USED: 0
SUM_NO_GOOD_INDEX_USED: 0
FIRST_SEEN: 2016-03-24 14:25:32
LAST_SEEN: 2016-03-24 14:25:55
The digest table normalizes all the statements (as seen in the DIGEST_TEXT field above), ignoring data values and standardizing whitespace and capitalization, so that the following two queries would be considered the same:
select * from employees where emp_no >200;
SELECT * FROM employees WHERE emp_no > 80000;
To extract a per-schema average run time in microseconds, you can query the performance schema:
SELECT schema_name
, SUM(count_star) count
, ROUND( (SUM(sum_timer_wait) / SUM(count_star))
/ 1000000) AS avg_microsec
FROM performance_schema.events_statements_summary_by_digest
WHERE schema_name IS NOT NULL
GROUP BY schema_name;
+--------------------+-------+--------------+
| schema_name | count | avg_microsec |
+--------------------+-------+--------------+
| employees | 223 | 171940 |
| performance_schema | 37 | 20761 |
| sys | 4 | 748 |
+--------------------+-------+--------------+
Similarly, to count the total number of statements per schema that generated errors:
SELECT schema_name
, SUM(sum_errors) err_count
FROM performance_schema.events_statements_summary_by_digest
WHERE schema_name IS NOT NULL
GROUP BY schema_name;
+--------------------+-----------+
| schema_name | err_count |
+--------------------+-----------+
| employees | 8 |
| performance_schema | 1 |
| sys | 3 |
+--------------------+-----------+
The sys schema
Querying the performance schema as shown above works great for programmatically retrieving metrics from the database. For ad hoc queries and investigation, however, it is usually easier to use MySQL’s sys schema. The sys schema provides an organized set of metrics in a more human-readable format, making the corresponding queries much simpler. For instance, to find the slowest statements (those in the 95th percentile by runtime):
SELECT * FROM sys.statements_with_runtimes_in_95th_percentile;
Or to see which normalized statements have generated errors:
SELECT * FROM sys.statements_with_errors_or_warnings;
Many other useful examples are detailed in the sys schema documentation. The sys schema is included in MySQL starting with version 5.7.7, but MySQL 5.6 users can install it with just a few commands. See Part 2 of this series for instructions.
Slow queries
In addition to the wealth of performance data available in the performance schema and sys schema, MySQL features a Slow_queries counter, which increments every time a query’s execution time exceeds the number of seconds specified by the long_query_time parameter. The threshold is set to 10 seconds by default:
SHOW VARIABLES LIKE 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
The long_query_time parameter can be adjusted with one command. For example, to set the slow query threshold to five seconds:
SET GLOBAL long_query_time = 5;
(Note that you may have to close your session and reconnect to the database for the change to be applied at the session level.)
Investigating query performance issues
If your queries are executing more slowly than expected, it is often the case that a recently changed query is the culprit. If no query is determined to be unduly slow, the next things to evaluate are system-level metrics to look for constraints in core resources (CPU, disk I/O, memory, and network). CPU saturation and I/O bottlenecks are common culprits. You may also wish to check the Innodb_row_lock_waits metric, which counts how often the InnoDB storage engine had to wait to acquire a lock on a particular row. InnoDB has been the default storage engine since MySQL version 5.5, and MySQL uses row-level locking for InnoDB tables.
To increase the speed of read and write operations, many users will want to tune the size of the buffer pool used by InnoDB to cache table and index data. More on monitoring and resizing the buffer pool below.
Metrics to alert on
- Query run time: Managing latency for key databases is critical. If the average run time for queries in a production database starts to climb, look for resource constraints on your database instances, possible contention for row or table locks, and changes in query patterns on the client side.
- Query errors: A sudden increase in query errors can indicate a problem with your client application or your database itself. You can use the sys schema to quickly explore which queries may be causing problems. For instance, to list the 10 normalized statements that have returned the most errors:
SELECT * FROM sys.statements_with_errors_or_warnings ORDER BY errors DESC LIMIT 10; Slow_queries: How you define a slow query (and therefore how you configure thelong_query_timeparameter) depends on your use case. Whatever your definition of “slow,” you will likely want to investigate if the count of slow queries rises above baseline levels. To identify the actual queries executing slowly, you can query the sys schema or dive into MySQL’s optional slow query log, which is disabled by default. More information on enabling and accessing the slow query log is available in the MySQL documentation.
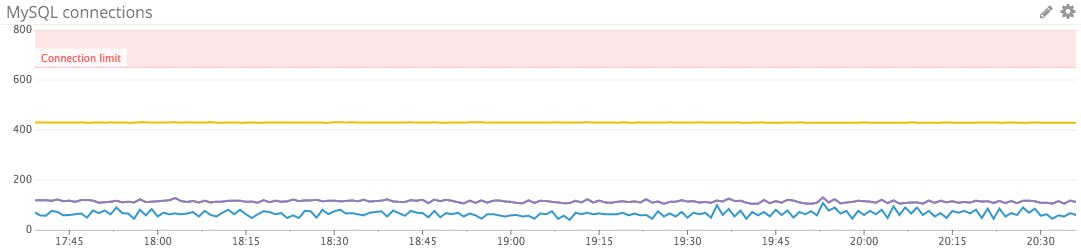
Connections
| Name | Description | Metric type | Availability |
|---|---|---|---|
| Threads_connected | Currently open connections | Resource: Utilization | Server status variable |
| Threads_running | Currently running connections | Resource: Utilization | Server status variable |
| Connection_errors_ internal | Count of connections refused due to server error | Resource: Error | Server status variable |
| Aborted_connects | Count of failed connection attempts to the server | Resource: Error | Server status variable |
| Connection_errors_ max_connections | Count of connections refused due to max_connections limit | Resource: Error | Server status variable |
Checking and setting the connection limit
Monitoring your client connections is critical, because once you have exhausted your available connections, new client connections will be refused. The MySQL connection limit defaults to 151, but can be verified with a query:
SHOW VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
MySQL’s documentation suggests that robust servers should be able to handle connections in the high hundreds or thousands:
“Linux or Solaris should be able to support 500 to 1000 simultaneous connections routinely and as many as 10,000 connections if you have many gigabytes of RAM available and the workload from each is low or the response time target undemanding. Windows is limited to (open tables × 2 + open connections) < 2048 due to the Posix compatibility layer used on that platform.”
The connection limit can be adjusted on the fly:
SET GLOBAL max_connections = 200;
That setting will return to the default when the server restarts, however. To permanently set the connection limit, add a line like this to your my.cnf configuration file (see this post for help in locating the config file):
max_connections = 200
Monitoring connection utilization
MySQL exposes a Threads_connected metric counting connection threads—one thread per connection. By monitoring this metric alongside your configured connection limit, you can ensure that you have enough capacity to handle new connections. MySQL also exposes the Threads_running metric to isolate which of those threads are actively processing queries at any given time, as opposed to connections that are open but are currently idle.
If your server does reach the max_connections limit, it will start to refuse connections. In that event, the metric Connection_errors_max_connections will be incremented, as will the Aborted_connects metric tracking all failed connection attempts.
MySQL exposes a variety of other metrics on connection errors, which can help you investigate connection problems. The metric Connection_errors_internal is a good one to watch, because it is incremented only when the error comes from the server itself. Internal errors can reflect an out-of-memory condition or the server’s inability to start a new thread.
Metrics to alert on
Threads_connected: If a client attempts to connect to MySQL when all available connections are in use, MySQL will return a “Too many connections” error and incrementConnection_errors_max_connections. To prevent this scenario, you should monitor the number of open connections and make sure that it remains safely below the configuredmax_connectionslimit.Aborted_connects: If this counter is increasing, your clients are trying and failing to connect to the database. Investigate the source of the problem with fine-grained connection metrics such asConnection_errors_max_connectionsandConnection_errors_internal.
Buffer pool usage

| Name | Description | Metric type | Availability |
|---|---|---|---|
| Innodb_buffer_pool_pages_total | Total number of pages in the buffer pool | Resource: Utilization | Server status variable |
| Buffer pool utilization | Ratio of used to total pages in the buffer pool | Resource: Utilization | Computed from server status variables |
| Innodb_buffer_pool_read_requests | Requests made to the buffer pool | Resource: Utilization | Server status variable |
| Innodb_buffer_pool_reads | Requests the buffer pool could not fulfill | Resource: Saturation | Server status variable |
MySQL’s default storage engine, InnoDB, uses an area of memory called the buffer pool to cache data for tables and indexes. Buffer pool metrics are resource metrics as opposed to work metrics, and as such are primarily useful for investigating (rather than detecting) performance issues. If database performance starts to slide while disk I/O is rising, expanding the buffer pool can often provide benefits.
Sizing the buffer pool
The buffer pool defaults to a relatively small 128 mebibytes, but MySQL advises that you can increase it to as much as 80 percent of physical memory on a dedicated database server. MySQL also adds a few notes of caution, however, as InnoDB’s memory overhead can increase the memory footprint by about 10 percent beyond the allotted buffer pool size. And if you run out of physical memory, your system will resort to paging and performance will suffer significantly.
The buffer pool also can be divided into separate regions, known as instances. Using multiple instances can improve concurrency for buffer pools in the multi-GiB range.
Buffer-pool resizing operations are performed in chunks, and the size of the buffer pool must be set to a multiple of the chunk size times the number of instances:
innodb_buffer_pool_size = N * innodb_buffer_pool_chunk_size
* innodb_buffer_pool_instances
The chunk size defaults to 128 MiB but is configurable as of MySQL 5.7.5. The value of both parameters can be checked as follows:
SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_chunk_size";
SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_instances";
If the innodb_buffer_pool_chunk_size query returns no results, the parameter is not tunable in your version of MySQL and can be assumed to be 128 MiB.
To set the buffer pool size and number of instances at server startup:
$ mysqld --innodb_buffer_pool_size=8G --innodb_buffer_pool_instances=16
As of MySQL 5.7.5, you can also resize the buffer pool on-the-fly via a SET command specifying the desired size in bytes. For instance, with two buffer pool instances, you could set each to 4 GiB size by setting the total size to 8 GiB:
SET GLOBAL innodb_buffer_pool_size=8589934592;
Key InnoDB buffer pool metrics
MySQL exposes a handful of metrics on the buffer pool and its utilization. Some of the most useful are the metrics tracking the total size of the buffer pool, how much is in use, and how effectively the buffer pool is serving reads.
The metrics Innodb_buffer_pool_read_requests and Innodb_buffer_pool_reads are key to understanding buffer pool utilization. Innodb_buffer_pool_read_requests tracks the the number of logical read requests, whereas Innodb_buffer_pool_reads tracks the number of requests that the buffer pool could not satisfy and therefore had to be read from disk. Given that reading from memory is generally orders of magnitude faster than reading from disk, performance will suffer if Innodb_buffer_pool_reads starts to climb.
Buffer pool utilization is a useful metric to check before you consider resizing the buffer pool. The utilization metric is not available out of the box but can be easily calculated as follows:
(Innodb_buffer_pool_pages_total - Innodb_buffer_pool_pages_free) /
Innodb_buffer_pool_pages_total
If your database is serving a large number of reads from disk, but the buffer pool is far from full, it may be that your cache has recently been cleared and is still warming up. If your buffer pool does not fill up but is effectively serving reads, your working set of data likely fits comfortably in memory.
High buffer pool utilization, on the other hand, is not necessarily a bad thing in isolation, as old or unused data is automatically aged out of the cache using an LRU policy. But if the buffer pool is not effectively serving your read workload, it may be time to scale up your cache.
Converting buffer pool metrics to bytes
Most buffer pool metrics are reported as a count of memory pages, but these metrics can be converted to bytes, which makes it easier to connect these metrics with the actual size of your buffer pool. For instance, to find the total size of buffer pool in bytes using the server status variable tracking total pages in the buffer pool:
Innodb_buffer_pool_pages_total * innodb_page_size
The InnoDB page size is adjustable but defaults to 16 KiB, or 16,384 bytes. Its current value can be checked with a SHOW VARIABLES query:
SHOW VARIABLES LIKE "innodb_page_size";
Conclusion
In this post we have explored a handful of the most important metrics you should monitor to keep tabs on MySQL activity and performance. If you are building out your MySQL monitoring, capturing the metrics outlined below will put you on the path toward understanding your database’s usage patterns and potential constraints. They will also help you to identify when it is necessary to scale out or move your database instances to more powerful hosts in order to maintain good application performance.
Part 2 of this series provides instructions for collecting and monitoring all the metrics you need from MySQL.
Acknowledgments
Many thanks to Dave Stokes of Oracle and Ewen Fortune of VividCortex for providing valuable feedback on this article prior to publication.
