

Google Cloud Run is a fully managed platform that enables you to deploy and scale container-based serverless workloads. Cloud Run is built on top of Knative, an open source platform that extends Kubernetes with serverless capabilities like dynamic auto-scaling, routing, and event-driven functions. By using Cloud Run, developers can simply write and package their code as container images and deploy to Cloud Run—all without worrying about managing or maintaining any underlying infrastructure.
Because Cloud Run abstracts away infrastructure management, there are monitoring concerns to consider that are different from those you would have for traditional non-serverless containers. For example, Cloud Run auto-scales containers based on the volume of incoming requests, but if you don’t know the CPU and memory usage of these containers, you can’t determine what resource settings and limits to enact to ensure that the scaling behavior of your Cloud Run containers is efficient and cost effective. Over- or underutilization of allocated container resources can lead to degraded user experience and unanticipated cloud costs.
In this post, we’ll cover key Cloud Run metrics you should monitor to ensure that your serverless containerized applications are reliable, responsive to requests, and utilizing resources efficiently. In the next section, we’ll look at fundamental Cloud Run concepts that affect how you should approach monitoring your environment.
Brief overview of Google Cloud Run
Cloud Run is a managed service built on Knative, providing serverless capabilities for containerized workloads. It integrates easily with other Google Cloud services such as Pub/Sub, Cloud Storage, and Google Cloud SQL, which makes it ideal for organizations who are already working within the Google Cloud ecosystem. Cloud Run also offers more flexibility and portability than Google Cloud’s other serverless offering, Cloud Run Functions. Cloud Run Functions are an abstraction on top of Cloud Run where Google handles the management of the HTTP/event server logic for you. While this does allow you to focus more on the specifics of your application, it offers a lower degree of configurability compared to the container-based solution of Cloud Run. Cloud Run also provides you with more portability, as container-based applications can be moved across different containerized environments, whereas Cloud Run Functions are more tightly integrated into the Google Cloud ecosystem so they are much less portable.
Cloud Run enables you to run code in one of two ways: as Cloud Run services, which handle HTTP-based request workloads, or Cloud Run jobs, designed for executing tasks that run to completion. Both cover a broad range of use cases, and next we will take a look at what types of workloads each is most appropriate for.
Cloud Run services
Cloud Run services feature request-based auto-scaling and built-in traffic management, meaning they automatically scale out to the number of container instances necessary to handle incoming requests, manage concurrency, and meet CPU demands. Services are best suited for APIs, web applications, microservices, or any other use case in which you want your code to respond to specific requests and events from clients that can access your service over the web.
When traffic reaches a service, Cloud Run employs a load balancer to automatically distribute requests across container instances based on their availability and current workload. By default, container instances can handle 80 concurrent requests, but you have the option to increase the maximum concurrency settings up to 1,000. Alternatively, you can decrease your container instances’ concurrency settings down to one in cases where there may be resource or dependency limitations and parallel processing may introduce complications. For instance, your code may not be designed to handle several requests simultaneously or may be performing tasks that are so resource intensive a single request may require all available memory or CPU.
A Cloud Run service has a corresponding HTTPS URL (e.g., https://your-ecommerce-app-service.run.app). Clients can send web requests and events to these HTTPS endpoints and Cloud Run will automatically spin up container instances in response, as illustrated below.
Services can scale out to a maximum of 100 instances, but you have the option to adjust this maximum when necessary. For example, you may choose to decrease your instance maximum in order to control costs or limit the demand on a backend database by preventing too many instances from starting up and opening database connections.
When traffic demands decrease, Cloud Run will scale container instances down in response. By default, Cloud Run will scale instances down to zero unless you have set a configured minimum. Google Cloud recommends setting an instance minimum to help ensure your service has some instances available to respond to requests, which helps minimize latency added by “cold starts” that occur when a service scales from zero.
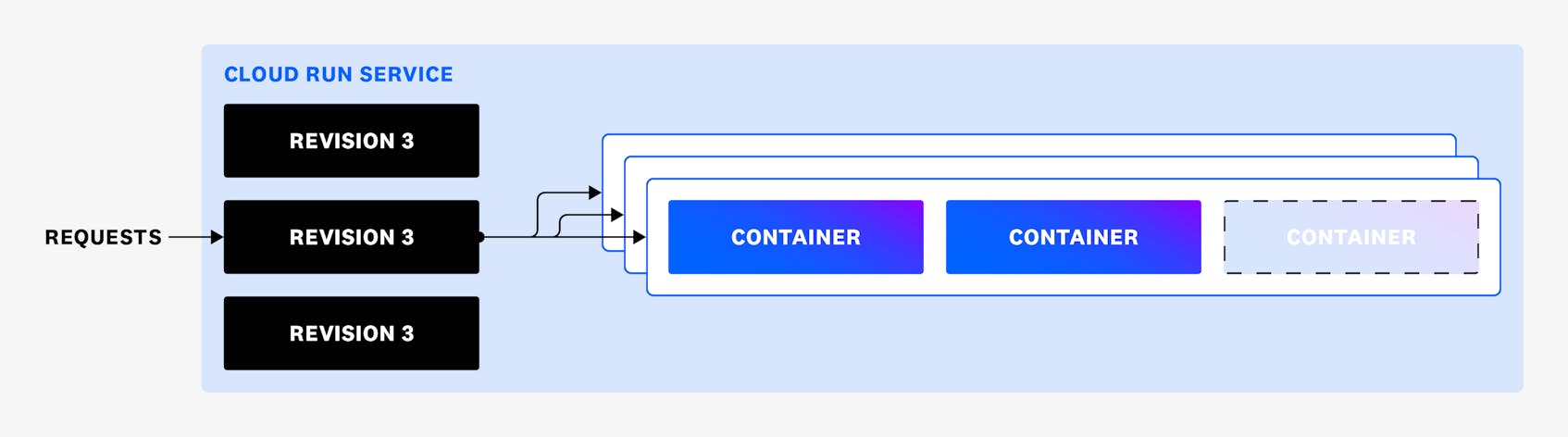
Cloud Run service monitoring data is aggregated by revision, which refers to a specific version of your service that has been deployed. Any updates you make to a Cloud Run service—such as a memory limit change or added environment variables—result in a new revision of that service. With Cloud Run’s built-in traffic management, you can split incoming request traffic between several different revisions simultaneously, which is particularly useful for canary deployments and gradual rollouts. For example, if you have a revision of a service that includes bug fixes and dependency changes, you can roll out that revision to a small subset of users to ensure that performance improves as expected before rolling it out to the rest of your user base. And if a newly deployed revision has unexpected bugs, you can easily roll back to a previous revision.
Cloud Run jobs
Cloud Run jobs are short lived and designed for executing scheduled tasks and batch processing jobs such as periodic video or image resizing, web scraping, or formatting and cleaning a dataset. Unlike Cloud Run services, jobs are not directly exposed to the wider internet and don’t listen for HTTP requests. Instead, jobs are either executed manually, on a schedule, or as part of an existing workflow and then shut down.
When Cloud Run executes a job, it creates one or more “tasks” (with a maximum of 10,000 tasks) based on the job’s configuration. Each task spins up a single container, which can be configured to retry in case of a failure. By default, the maximum number of retries a task has before failing is three. If a task within a job fails after exceeding its maximum retry count, the job execution is marked as failed. Similar to service concurrency, you can also configure Cloud Run jobs to use parallelism to define how many tasks a job can run simultaneously. You can use parallelism to help speed up the performance of your jobs by executing several tasks all at once rather than executing them one at a time.
Key metrics to monitor
Now that we’ve explored some key Cloud Run concepts, let’s take a look at the critical metrics to monitor for maintaining the health and performance of your serverless container workloads. Since Cloud Run abstracts away the underlying infrastructure, your focus should shift to optimizing resource allocation and to minimizing cost and latency. This means monitoring core metrics across service revisions and jobs and making adjustments as needed.
Cloud Run metrics fall under the following categories:
Monitoring how many containers are currently active, the resources they have available to them, and what portion of those resources are actually being used can help you make cost and performance optimization decisions. For instance, if containers overutilize allocated resources or exceed resource limitations which can slow down performance, you may decide to set higher resource limits.
CPU metrics
| Metric | Description | Metric type |
|---|---|---|
| CPU utilization | The average percentage of allocated CPU currently being utilized, aggregated across all container instances running for a particular revision | Resource: Utilization |
| CPU allocation time | The average amount of time it takes (in milliseconds) for container instances in a revision to be allocated and granted access to CPU once they receive requests | Resource: Utilization |
Container instances are allocated CPU based on your configurations for both services and jobs, up to a maximum of eight CPUs and minimum of one CPU if no configuration has been specified.
For Cloud Run services, you have the option to allocate CPU to container instances while requests are being processed, or enable CPU to always be allocated even if no requests are coming in. Allocating CPU while requests are being processed is ideal when you expect irregular bursts of traffic, such as hosting a newsfeed. Google Cloud recommends enabling instances to always have allocated CPU in circumstances when you expect steady, rarely varying traffic, such as regular background tasks.
Note that even if you choose to always allocate CPU to container instances, Cloud Run’s auto-scaling behavior won’t be impacted and instances will still terminate when there are no longer incoming requests. If you need to ensure that you always have some number of instances up and running with allocated CPU, you should configure your service to use a minimum number of instances that always have CPU allocated to them.
Metric to alert on: CPU utilization
Monitoring and alerting on CPU utilization helps you gauge whether your containers have sufficient compute resources to handle workloads effectively.
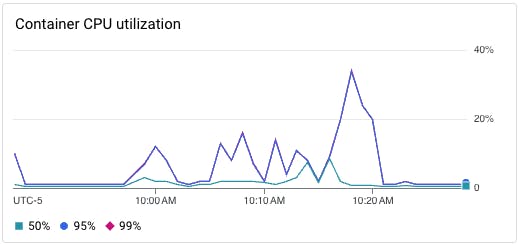
You should set alerts to notify you when CPU utilization is high (i.e., above 90 percent) for an unusually long duration of time. If instances overuse CPU, it can lead to resource contention as other instances within your service have to wait for there to be enough CPU available to process requests. This, in turn, leads to heightened latency.
Metric to watch: CPU allocation time
Another key metric to pay closer attention to is the amount of time it takes (in milliseconds) for container instances to be allocated and granted access to CPUs once they receive requests. Pricing is impacted differently depending on whether you have enabled always-on CPU allocation or have CPU allocated to container instances only upon receiving requests. If you have always-on allocation enabled, then CPU resources are allocated throughout the entire lifecycle of a container instance and you are charged for that entire time. Otherwise, you are charged only when an instance processes a request.
Monitoring CPU allocation time can help you spot bottlenecks and CPU contention issues. For example, if CPU allocation time spikes unexpectedly, it may indicate that your service is waiting longer for CPU resources due to high demand. This can slow down performance, as instances are delayed while they wait for CPU access, potentially leading to processing bottlenecks. CPU utilization time could also increase as your service auto-scales since more instances require additional CPU to start up. In this case, you may want to enable Cloud Run’s startup CPU boost feature, which temporarily grants additional CPU to minimize startup latencies.
Memory metrics
Memory is used to store information that Cloud Run containers need to run properly, such as code, library variables, and other necessary runtime data. Without sufficient memory, your serverless workloads can experience slowdowns, errors, and even shutdowns. In Cloud Run, you must configure your container instance settings to specify how memory is allocated. You define the amount of memory each container instance should have, ranging from 512 MiB to 32 GiB. Cloud Run then ensures that each instance of your container has the allocated amount of memory available for its use. This allocation affects both performance and billing. To determine what a service’s peak memory requirements are, and therefore what your memory configuration settings should be, Google Cloud recommends taking into account the baseline amount of memory that service uses before processing a request, the additional memory it needs while processing a request, and your concurrency settings. With that in mind, if you increase a service’s concurrency settings, you should also allocate more memory to that service.
In Cloud Run, you can set memory limits on the instances running in your services and jobs. If instances exceed your set limits, they will be terminated. To ensure your Cloud Run services and jobs have enough memory resources and are neither over- nor underutilizing available memory, you can monitor the key metrics listed below.
| Metric | Description | Metric type |
|---|---|---|
| Memory utilization | The percentage of allocated memory currently being utilized across container instances | Resource: Utilization |
| Memory allocation time | The amount of time it takes in milliseconds for container instances to be allocated and granted access to memory once they receive requests | Work: Performance |
Metric to alert on: memory utilization
When monitoring Cloud Run, you need insight into what proportion of allocated memory container instances of a particular service or job are actively consuming. This helps you better understand resource usage and configure memory limits with sufficient overhead to ensure stable and healthy performance under varying loads. When memory utilization is too high and exceeds container memory limits, it can lead to Out of Memory (OOM) kills in which containers or, in some cases, entire services are terminated.
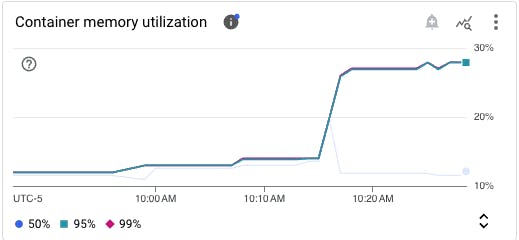
The default memory limit of both Cloud Run service and job container instances is 512 MiB. If there is a sudden and sustained traffic spike, instances may start to exceed the limit and shut down. You can take proactive steps to avoid performance disruptions by setting an alert to notify you when memory utilization is close to exceeding the limit and then deploying revisions of your service with higher memory limits.
Metric to watch: memory allocation time
Memory allocation time is the rate (GiB per second) at which allocated memory is utilized by your Cloud Run container instances while handling requests. Because Cloud Run charges you based on the amount of time resources are used, keeping an eye on the memory allocation time of Cloud Run services can help you understand your workloads, predict costs, and make configuration changes as necessary. For example, let’s say that the memory allocation time for a particular service typically increases significantly during peak hours, indicating that the containers are running longer due to high memory demands or CPU constraints that prevent workloads from processing requests quickly enough, directly impacting costs. Normally this does not pose much of an issue but your e-commerce site is about to run a sale and you believe that your service will soon have to meet heavier demands. You can choose to set higher memory limits on the appropriate Cloud Run services throughout the duration of the sale to avoid resource contention and performance degradation.
Request metrics
Request metrics provide you with an overview of how your serverless container instances are handling client traffic. Knowing how many requests your containers are receiving and how quickly they are able to process them helps you establish traffic expectations and determine if your services are performing optimally. Request metrics are particularly useful for helping you configure the concurrency settings of your container instances. By understanding how many requests each container may need to handle simultaneously, you can fine-tune your concurrency settings to balance resource utilization and performance, ensuring that instances aren’t overloaded with too many requests or underutilized with too few.
| Metric | Description | Metric type |
|---|---|---|
| Request count | The number of requests that have successfully reached your service, aggregated per service | Work: Throughput |
| Request latency | The average amount of time it takes (in milliseconds) for containers in a revision to receive a request and return a response, aggregated per revision | Work: Performance |
Metric to watch: request count
Monitoring the volume of requests reaching your services is critical for understanding the overall load of your applications on Cloud Run, which enables you to make resource-management and capacity-planning decisions. For example, once you’ve established baseline request behavior, you can determine whether your CPU and memory configurations are sufficient. If traffic is steady and container instances never receive more than a certain number of requests, you can adjust your concurrency settings and the amount of resources you have allocated to match actual demand. This will help you prevent unnecessary resource usage and save costs as a result.
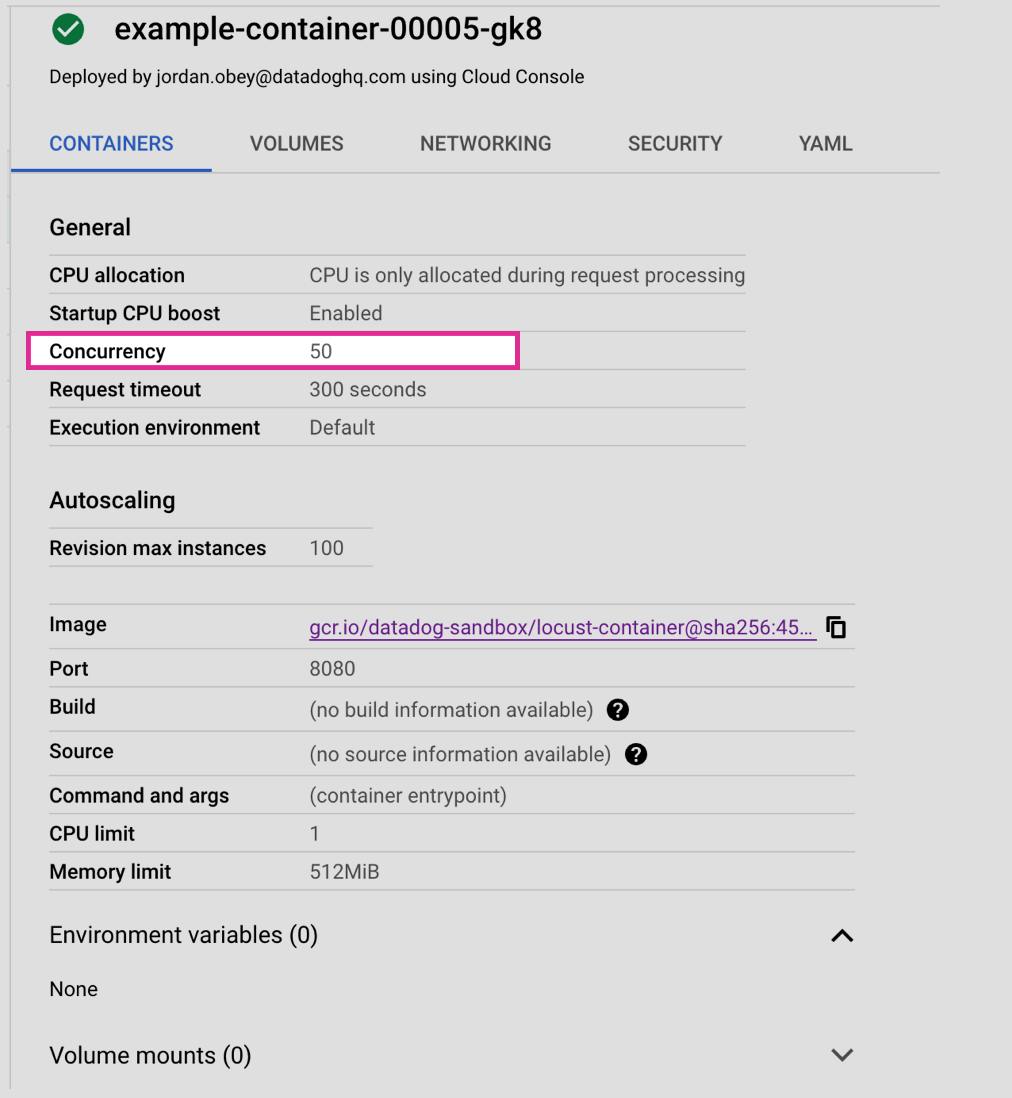
Let’s say you set your Cloud Run container instances to handle 50 concurrent requests (as shown in the image above) instead of the default 80 because your application has some moderately resource-intensive processes, and you want to ensure each request gets sufficient resources for optimal performance. However, during an unexpected traffic surge your service receives 500 requests per second. In this case, Cloud Run will need to spin up 10 instances to handle the load (500 requests / 50 concurrency = 10 instances). This scaling up can lead to a latency spike as new instances take time to spin up, and it also increases costs due to the higher number of active instances.
If you increase the concurrency settings to 100 requests per instance, the same 500 requests per second would only require five instances (500 / 100 = 5), reducing the total number of instances needed and in turn lowering costs and minimizing overhead. Note that it’s important to test your application’s performance under higher concurrency to ensure that it can handle more simultaneous requests without experiencing resource contention or performance degradation. Carefully monitoring the volume of incoming requests can help you strike that balance between resource utilization, latency, and costs based on your specific workload.
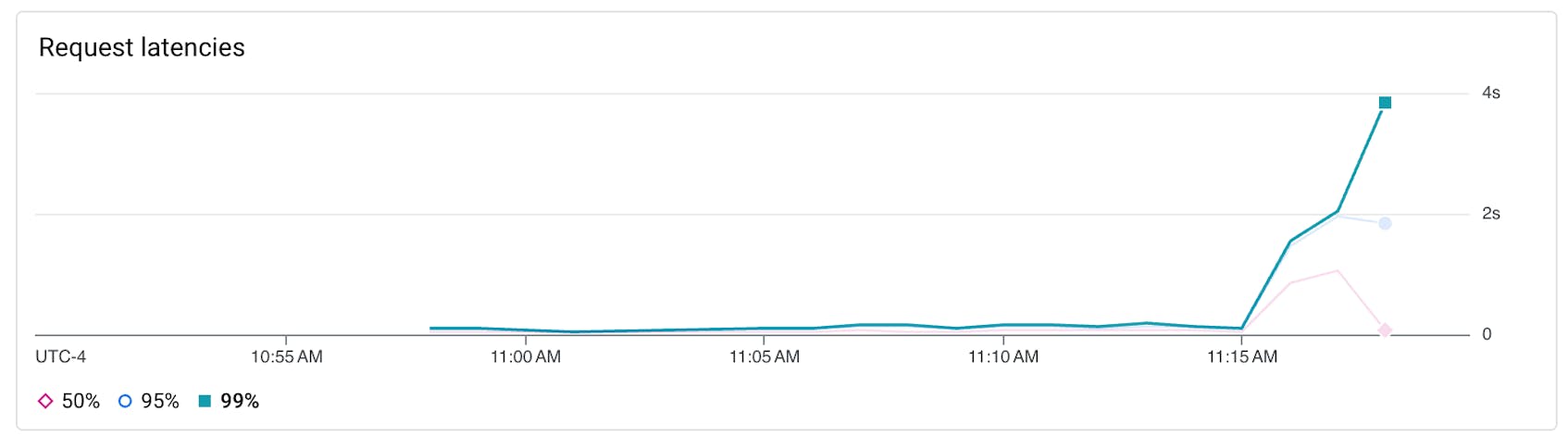
Metric to alert on: request latency
Ensuring that your request latencies are low is an essential part of delivering a highly-performant application on Cloud Run. To do so, you should alert on the request latency metric, which highlights the amount of time it takes for a service to receive a request and return a response.
While the threshold you set will vary based on your organizations’ service level objectives (SLOs) and traffic expectations, a good rule of thumb is to set a monitor to warn you when request latencies exceed 500 milliseconds, and a critical alert for when they exceed 1,000 milliseconds (i.e., above one second). Being alerted to high request latencies can help you quickly start investigating the problem and uncover potential root causes, such as bugs in your code, resource contention issues, or cold starts.
Alerting on request latency can also provide insight into the efficacy of your concurrency settings, as concurrency settings have a direct impact on request latencies. If you are getting high latency alerts, you may consider configuring lower concurrency settings so that each container instance handles fewer simultaneous requests. This can help reduce request latency because every request gets a larger share of an instance’s CPU and memory resources. However, as we saw in the previous section, low concurrency means more container instances are needed to handle high traffic. If traffic surges and instances need to be spun up, there may be a slight increase in latency due to the time it takes for Cloud Run to scale up and launch new instances.
For workloads that are I/O-bound and not CPU-intensive, you can improve latency by increasing concurrency levels. For example, a simple web service that returns static content using little CPU can benefit from higher concurrency. By allowing more requests to be handled in parallel, instances stay active and fully utilized, and clients don’t experience latency waiting for new instances to start up during traffic surges.
In Cloud Run, the key is to find the right concurrency setting that balances latency and resource efficiency to control costs and prevent over-provisioning. Monitoring request latencies and adjusting concurrency based on your application’s behavior can help maintain this balance.
Instance metrics
Instance metrics from Cloud Run provide you with a high-level overview of the containers hosting your workloads, giving you insight into costs and resource utilization. These metrics give you a clear picture of how many container instances are running and for how long, helping you understand how efficiently your service is using resources like CPU and memory, which directly impacts your billing. By reviewing these metrics, you can make adjustments to improve efficiency and reduce costs, such as optimizing concurrency settings.
| Metric | Description | Metric type |
|---|---|---|
| Billable instance time | The duration (in seconds) that a workload’s container instances are actively consuming memory and CPU, aggregated per service or job | Resource: Utilization |
| Container instance count | Total number of existing container instances | Resource: Availability |
Metric to watch: billable instance time
In Cloud Run, you are billed for the duration (in seconds) that all the container instances in a revision actively consume memory and CPU, with prices varying based on your resource allocation settings. Billable instance time directly impacts your cloud costs, so it’s important to watch this metric closely to ensure that it stays within your budget. Monitoring billable instance time is also useful for capacity planning. For example, you can analyze historical trends in billable instance time to identify peaks in resource usage to adjust CPU and memory allocation based on actual demand and set realistic budgetary expectations.
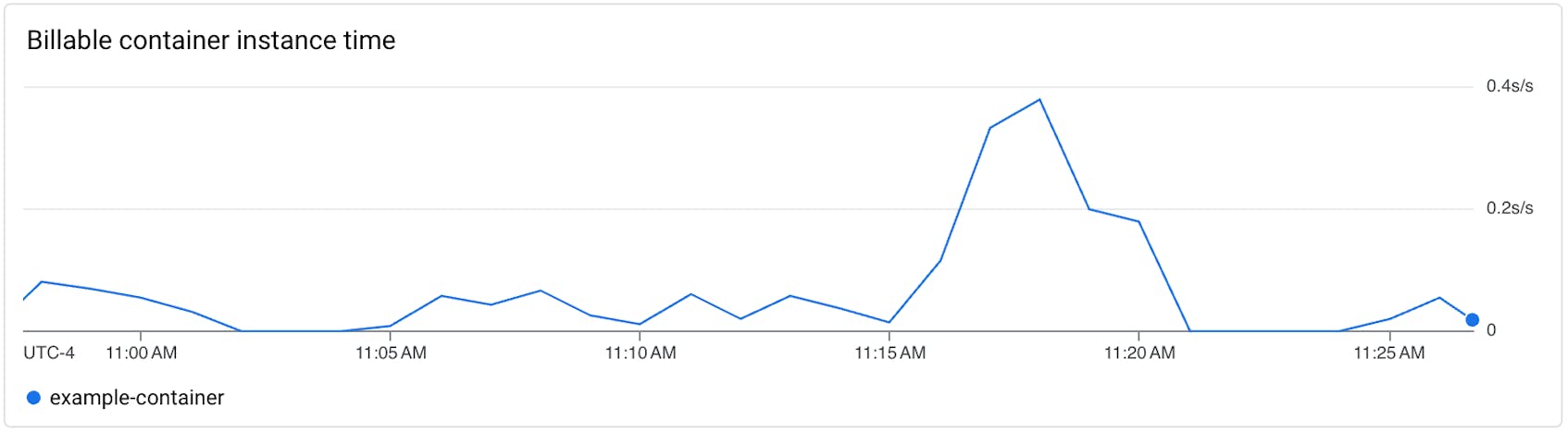
When billable instance time is consistently higher than expected and driving up costs, it could be due to a number of factors. For example, your scaling settings may not match the actual traffic patterns of your workloads. You may have decided not to set a minimum number of container instances in an attempt to save costs, reasoning that doing so means there is always some CPU or memory you will be charged for. Not setting a minimum for container instances, however, leads to cold starts because workloads now have to spin up from zero instances when there is new traffic. These cold starts may drive up costs because you are billed for their delayed initialization. This is particularly true in scenarios where your application experiences frequent, sporadic bursts of traffic, because the cost of repeated cold starts could exceed the cost of maintaining a minimum number of instances—especially if the initialization of your application is resource intensive.
To determine whether having always-on instances makes sense versus accepting cold starts, you need to monitor and balance request latency, traffic patterns, concurrency, and billable instance time. If cold starts are causing frequent and significant latency spikes, or if you have low concurrency settings, always-on instances could improve performance and reduce user-facing delays. On the other hand, if cold starts have minimal impact or if your service handles high concurrency well, you might prefer the cost savings of starting from zero instances.
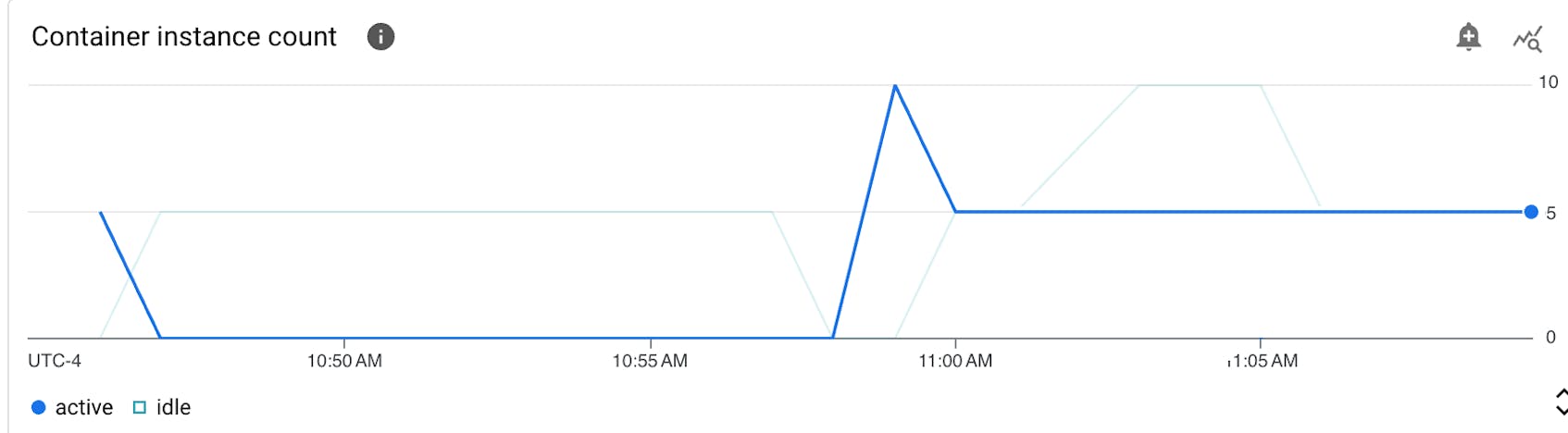
Metric to watch: container instance count
As you monitor your Cloud Run workloads, you should keep track of the total number of container instances that exist within your services as well as what proportion of those containers are active or idle. Cloud Run labels every count of a container instance as state so that you know of the total number of instances that are actively in use or idle. Tracking container instance count along with the state of instances helps surface traffic trends and usage patterns so you can evaluate your application’s scaling behavior and responsiveness under different workloads. You may find, for example, that a service has fairly stable and predictable traffic and doesn’t require the default maximum 100 instance limit, as it rarely exceeds 50 active instances. In that case, consider lowering the maximum instance limit to minimize resource usage and costs.
Note that Cloud Run does not have a specific container instance count metric for Cloud Run jobs. However, since one task equates to one container instance, you can use the count of running task attempts to keep track of the number of tasks a job is currently running, which corresponds to the number of active container instances within that job.
Cloud Run job metrics
Job metrics from Cloud Run enable you to track execution patterns and outcomes. These metrics offer insights into how many jobs and tasks are running, and how many have completed successfully. Monitoring metrics such as task attempts, running executions, and completed executions is critical for gaining a complete view of the performance, reliability, and costs of Cloud Run jobs. Together these metrics help you gain actionable insights to improve efficiency, troubleshoot issues, and optimize resource allocation.
| Metric | Description | Metric type |
|---|---|---|
| Running job executions count | The number of job executions currently running | Work: Throughput |
| Completed job executions count | Total number of successful job executions | Work: Success |
| Running task attempts count | The number of tasks currently running within a job | Work: Throughput |
| Completed task attempts count | The number completed tasks within a job | Work: Success |
Metric to watch: running job executions count
When monitoring Cloud Run jobs, it’s important to keep an eye on the running job executions count and the completed job executions count. These metrics provide insight into the status of your jobs and help you understand how effectively your jobs are performing. The running job executions count reflects how many job executions are currently active at a given time, which helps you monitor concurrency and ensure that the number of jobs running simultaneously aligns with your system’s resource limits. For instance, consistently high running executions might indicate a need to adjust concurrency settings or allocate additional resources to handle peak workloads efficiently. On the other hand, if running executions are consistently low despite high demand, it may signal scaling limitations or misconfigurations. You should also compare the amount of running job executions to your number of task completions. A high count of running executions without a corresponding increase in task completions often points to inefficiencies like long task durations, resource contention, or scaling misconfigurations.
Metric to watch: completed job execution count
The completed job executions count provides visibility into the number of job executions that have finished successfully. Tracking this metric helps you ensure that your jobs are completing as expected and can highlight trends in job throughput over time. For example, if completed executions drop unexpectedly while running executions remain high, it could indicate issues such as tasks failing or jobs taking longer than expected to finish. By monitoring both running and completed job executions counts, you can evaluate the scaling behavior and reliability of your job workloads. This data can guide optimizations such as tuning job retry settings, adjusting resource allocations, or refining job definitions to enhance efficiency and performance. Understanding these metrics ensures that your jobs are operating smoothly, without over-provisioning resources or encountering bottlenecks.
Metric to watch: running task attempts count
Because each task attempt runs in its own container instance in Cloud Run, the number of running task attempts in a Cloud Run job corresponds directly to the number of active containers being used for that job. This means that in addition to helping you track the progress of a Cloud Run job, monitoring the count of running task attempts can help you evaluate concurrency. For example, if the number of running task attempts consistently approaches the concurrency limit configured for your Cloud Run job, it may indicate that your workloads are scaling to the maximum capacity allowed. This could signal a need to adjust the concurrency setting or increase the maximum instance limit to handle peak workloads more effectively. Conversely, if the count of running task attempts remains well below the configured limits, it might suggest opportunities to optimize by lowering resource allocations or instance limits to reduce costs without impacting performance. Monitoring running task attempts provides valuable insight into how well your job configuration aligns with workload demands and system resources.
Metric to watch: completed task attempts count
The count of task attempt completions represents a direct measure of how many tasks have successfully finished. For example, if the count of completed task attempts increases steadily in alignment with your workload expectations, it indicates that tasks are progressing and completing as intended. However, if completed task attempts lag significantly behind running task attempts, it may suggest issues such as long task durations, task retries due to failures, or resource contention. Conversely, if the count of completed task attempts consistently matches or exceeds expectations, it may reveal opportunities to scale down resources or optimize costs while maintaining performance. By analyzing this metric, you can identify inefficiencies in task processing, improve resource allocation, or refine task definitions to enhance throughput. Monitoring completed task attempts offers critical insight into how effectively your Cloud Run jobs are meeting their workload and performance goals.
Get visibility into your serverless containerized workloads
In this post, we looked at core Google Cloud Run concepts and talked about how you can run code as either a service or a job. We also discussed key metrics you can pay attention to in order to ensure that your serverless container instances have enough resources and are performing as expected. In the next post of this series, we’ll look at how you can collect and visualize those key metrics using Google Cloud’s monitoring tools.
