

What is NGINX?
NGINX (pronounced “engine X”) is a popular HTTP server and reverse proxy server. As an HTTP server, NGINX serves static content very efficiently and reliably, using relatively little memory. As a reverse proxy, it can be used as a single, controlled point of access for multiple back-end servers or for additional applications such as caching and load balancing. NGINX is available as a free, open source product or in a more full-featured, commercially distributed version called NGINX Plus.
NGINX can also be used as a mail proxy and a generic TCP proxy, but this article does not directly address NGINX monitoring for these use cases.
Key NGINX metrics
By monitoring NGINX you can catch two categories of issues: resource issues within NGINX itself, and also problems developing elsewhere in your web infrastructure. Some of the metrics most NGINX users will benefit from monitoring include requests per second, which provides a high-level view of combined end-user activity; server error rate, which indicates how often your servers are failing to process seemingly valid requests; and request processing time, which describes how long your servers are taking to process client requests (and which can point to slowdowns or other problems in your environment).
More generally, there are at least three key categories of metrics to watch:
Below we’ll break down a few of the most important NGINX metrics in each category, as well as metrics for a fairly common use case that deserves special mention: using NGINX Plus for reverse proxying. We will also describe how you can monitor all of these metrics with your graphing or monitoring tools of choice.
This article references metric terminology introduced in our Monitoring 101 series, which provides a framework for metric collection and alerting.
Basic activity metrics
Whatever your NGINX use case, you will no doubt want to monitor how many client requests your servers are receiving and how those requests are being processed.
NGINX Plus can report basic activity metrics exactly like open source NGINX, but it also provides a secondary module that reports metrics slightly differently. We discuss open source NGINX first, then the additional reporting capabilities provided by NGINX Plus.
NGINX
The diagram below shows the lifecycle of a client connection and how the open source version of NGINX collects metrics during a connection.
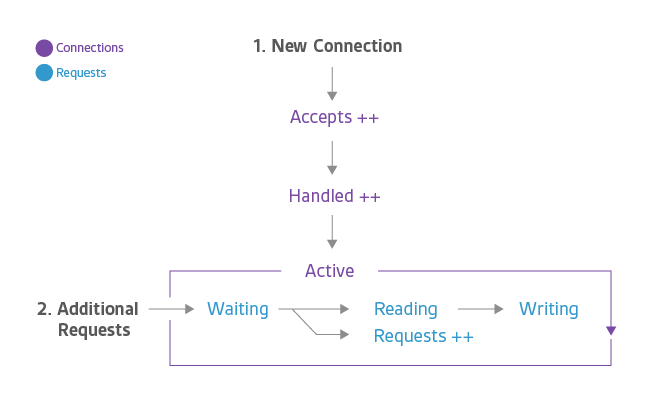
Accepts, handled, and requests are ever-increasing counters. Active, waiting, reading, and writing grow and shrink with request volume.
| Name | Description | Metric type |
|---|---|---|
| accepts | Count of client connections attempted by NGINX | Resource: Utilization |
| handled | Count of successful client connections | Resource: Utilization |
| active | Currently active client connections | Resource: Utilization |
| dropped (calculated) | Count of dropped connections (accepts – handled) | Work: Errors |
| requests | Count of client requests | Work: Throughput |
| *Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric. | ||
The accepts counter is incremented when an NGINX worker picks up a request for a connection from the OS. If the worker fails to get a connection for the request (by establishing a new connection or reusing an open one), then the connection is dropped and dropped is incremented. Ordinarily connections are dropped because a resource limit, such as NGINX’s worker_connections limit has been reached.
- Waiting: An active connection may also be in a Waiting substate if there is no active request at the moment. New connections can bypass this state and move directly to Reading, most commonly when using “accept filter” or “deferred accept”, in which case NGINX does not receive notice of work until it has enough data to begin working on the response. Connections will also be in the Waiting state after sending a response if the connection is set to keep-alive.
- Reading: When a request is received, the connection moves out of the waiting state, and the request itself is counted as Reading. In this state NGINX is reading a client request header. Request headers are lightweight, so this is usually a fast operation.
- Writing: After the request is read, it is counted as Writing, and remains in that state until a response is returned to the client. That means that the request is Writing while NGINX is waiting for results from upstream systems (systems “behind” NGINX), and while NGINX is operating on the response. Requests will often spend the majority of their time in the Writing state.
Often a connection will only support one request at a time. In this case, the number of Active connections == Waiting connections + Reading requests + Writing requests. However, HTTP/2 allows multiple concurrent requests/responses to be multiplexed over a connection, so Active may be less than the sum of Waiting, Reading, and Writing.
NGINX Plus
As mentioned above, all of open source NGINX’s metrics are available within NGINX Plus, but Plus can also report additional metrics. The section covers the metrics that are only available from NGINX Plus.
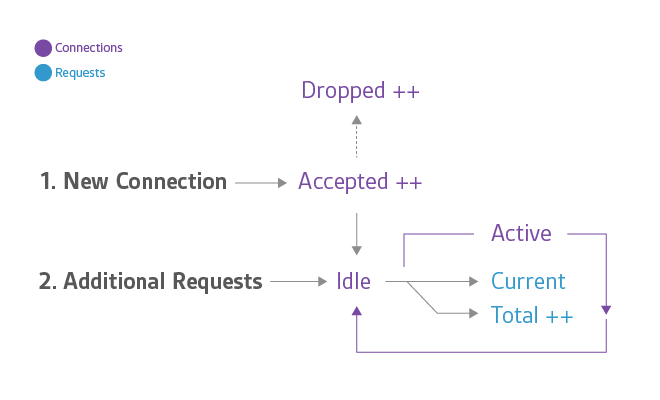
Accepted, dropped, and total are ever-increasing counters. Active, idle, and current track the current number of connections or requests in each of those states, so they grow and shrink with request volume.
| Name | Description | Metric Type |
|---|---|---|
| accepted | Count of client connections attempted by NGINX | Resource: Utilization |
| dropped (calculated) | Count of dropped connections | Work: Errors |
| active | Currently active client connections | Resource: Utilization |
| idle | Client connections with zero current requests | Resource: Utilizations |
| Total | Count of client requests | Work: Throughput |
| *Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric. | ||
The accepted counter is incremented when an NGINX Plus worker picks up a request for a connection from the OS. If the worker fails to get a connection for the request (by establishing a new connection or reusing an open one), then the connection is dropped and dropped is incremented. Ordinarily connections are dropped because a resource limit, such as NGINX Plus’s worker_connections limit, has been reached.
Active and idle are the same as “active” and “waiting” states in open source NGINX as described above, with one key exception: in open source NGINX, “waiting” falls under the “active” umbrella, whereas in NGINX Plus “idle” connections are excluded from the “active” count. Current is the same as the combined “reading + writing” states in open source NGINX.
Total is a cumulative count of client requests. Note that a single client connection can involve multiple requests, so this number may be significantly larger than the cumulative number of connections. In fact, (total / accepted) yields the average number of requests per connection.
| NGINX (open source) | NGINX Plus |
|---|---|
| accepts | accepted |
| dropped must be calculated | dropped is reported directly |
| reading + writing | current |
| waiting | idle |
| active (includes “waiting” states) | active (excludes “idle” states) |
| requests | total |
Metric to alert on: Dropped connections
The number of connections that have been dropped is equal to the difference between accepts and handled (NGINX) or is exposed directly as a standard metric (NGINX Plus). Under normal circumstances, dropped connections should be zero. If your rate of dropped connections per unit time starts to rise, look for possible resource saturation.
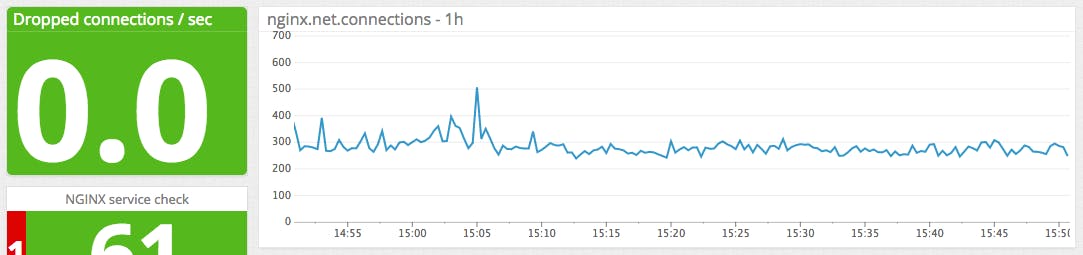
Metric to alert on: Requests per second
Sampling your request data (requests in open source, or total in Plus) with a fixed time interval provides you with the number of requests you’re receiving per unit of time—often minutes or seconds. Monitoring this metric can alert you to spikes in incoming web traffic, whether legitimate or nefarious, or sudden drops, which are usually indicative of problems. A drastic change in requests per second can alert you to problems brewing somewhere in your environment, even if it cannot tell you exactly where those problems lie. Note that all requests are counted the same, regardless of their URLs.

Collecting activity metrics
Open source NGINX exposes these basic server metrics on a simple status page. Because the status information is displayed in a standardized form, virtually any graphing or monitoring tool can be configured to parse the relevant data for analysis, visualization, or alerting. NGINX Plus provides a JSON feed with much richer data. Read the companion post on NGINX metrics collection for instructions on enabling metrics collection.
Error metrics
| Name | Description | Metric type | Availability |
|---|---|---|---|
| 4xx codes | Count of client errors such as "403 Forbidden" or "404 Not Found" | Work: Errors | NGINX logs, NGINX Plus |
| 5xx codes | Count of server errors such as "500 Internal Server Error" or "502 Bad Gateway" | Work: Errors | NGINX logs, NGINX Plus |
NGINX error metrics tell you how often your servers are returning errors instead of producing useful work. Client errors are represented by 4xx status codes, server errors with 5xx status codes.
Metric to alert on: Server error rate
Your server error rate is equal to the number of 5xx errors, such as “502 Bad Gateway”, divided by the total number of status codes (1xx, 2xx, 3xx, 4xx, 5xx), per unit of time (often one to five minutes). If your error rate starts to climb over time, investigation may be in order. If it spikes suddenly, urgent action may be required, as clients are likely to report errors to the end user.

A note on client errors: while it is tempting to monitor 4xx, there is limited information you can derive from that metric since it measures client behavior without offering any insight into particular URLs. In other words, a change in 4xx could be noise, e.g., web scanners blindly looking for vulnerabilities.
Collecting error metrics
Although open source NGINX does not make error rates immediately available for monitoring, there are at least two ways to capture that information:
- Use the expanded status module available with commercially supported NGINX Plus
- Configure NGINX’s log module to write response codes in access log
Read the companion post on NGINX metrics collection for detailed instructions on both approaches.
Performance metrics
| Name | Description | Metric type | Availability |
|---|---|---|---|
| request time | Time to process each request, in seconds | Work: Performance | NGINX logs |
Metric to alert on: Request processing time
The request time metric logged by NGINX records the processing time for each request, from the reading of the first client bytes to fulfilling the request. Long response times can point to problems upstream.
Collecting processing time metrics
NGINX and NGINX Plus users can capture data on processing time by adding the $request_time variable to the access log format. More details on configuring logs for monitoring are available in our companion post on NGINX metrics collection.
Reverse proxy metrics
| Name | Description | Metric type | Availability |
|---|---|---|---|
| Active connections by upstream server | Currently active client connections | Resource: Utilization | NGINX Plus |
| 5xx codes by upstream server | Server errors | Work: Errors | NGINX Plus |
| Available servers per upstream group | Servers passing health checks | Resource: Availability | NGINX Plus |
One of the most common ways to use NGINX is as a reverse proxy. The commercially supported NGINX Plus exposes a large number of metrics about backend (or “upstream”) servers, which are relevant to a reverse proxy setup. This section highlights a few of the key upstream metrics that are available to users of NGINX Plus.
NGINX Plus segments its upstream metrics first by group, and then by individual server. So if, for example, your reverse proxy is distributing requests to five upstream web servers, you can see at a glance whether any of those individual servers is overburdened, and also whether you have enough healthy servers in the upstream group to ensure good response times.
Activity metrics
The number of active connections per upstream server can help you verify that your reverse proxy is properly distributing work across your server group. If you are using NGINX as a load balancer, significant deviations in the number of connections handled by any one server can indicate that the server is struggling to process requests in a timely manner or that the load balancing method (e.g., round-robin or IP hashing) you have configured is not optimal for your traffic patterns.
Error metrics
Recall from the error metric section above that 5xx (server error) codes, such as “502 Bad Gateway” or “503 Service Temporarily Unavailable”, are a valuable metric to monitor, particularly as a share of total response codes. NGINX Plus allows you to easily extract the number of 5xx codes per upstream server, as well as the total number of responses, to determine that particular server’s error rate.
Availability metrics
For another view of the health of your web servers, NGINX also makes it simple to monitor the health of your upstream groups via the total number of servers currently available within each group. In a large reverse proxy setup, you may not care very much about the current state of any one server, just as long as your pool of available servers is capable of handling the load. But monitoring the total number of servers that are up within each upstream group can provide a very high-level view of the aggregate health of your web servers.
Collecting upstream metrics
NGINX Plus upstream metrics are exposed on the internal NGINX Plus monitoring dashboard, and are also available via a JSON interface that can serve up metrics into virtually any external monitoring platform. See examples in our companion post on collecting NGINX metrics.
Conclusion
In this post we’ve touched on some of the most useful metrics you can monitor to keep tabs on your NGINX servers. If you are just getting started with NGINX, monitoring most or all of the metrics in the list below will provide good visibility into the health and activity levels of your web infrastructure:
Eventually you will recognize additional, more specialized metrics that are particularly relevant to your own infrastructure and use cases. Of course, what you monitor will depend on the tools you have and the metrics available to you. See the companion post for step-by-step instructions on metric collection, whether you use NGINX or NGINX Plus.
At Datadog, we have built integrations with both NGINX and NGINX Plus so that you can begin collecting and monitoring metrics from all your web servers with a minimum of setup. Monitor NGINX with Datadog in this post, and get started right away with a free trial of Datadog.
Acknowledgments
Many thanks to the NGINX team for reviewing this article prior to publication and providing important feedback and clarifications.
Source Markdown for this post is available on GitHub. Questions, corrections, additions, etc.? Please let us know.
