


Tran Le

Till Pieper

Gillian McGarvey
Writing a postmortem is an essential learning process after an incident is resolved. But documenting important details comprehensively can be cumbersome, especially when responders have already moved on to the next urgent issue. To make this process easier, we implemented a feature in Bits AI that uses large language models (LLMs) to ease the writing process, aiming to retain the engineers’ control without compromising the primary goal of learning while recapping the details of the incident.
To implement this solution, we combined structured metadata from Datadog’s Incident Management app with unstructured discussions from related Slack channels. This data was then fed into an ensemble of LLM models to generate a postmortem first draft for human authors to build upon.
We learned that you can’t get reliable results with a naive approach that might otherwise work for interactive dialog systems like ChatGPT, and that evaluating the quality of results is nuanced due to the importance of retaining the human element of writing as a process of discovery and learning. This post dives into the challenges, solutions, and next steps that we unearthed during this project.
Challenges of using LLMs for postmortems
Putting LLM-based solutions into production requires significant but unintuitive efforts that go beyond commonly discussed tasks like model training, fine-tuning, and inference. For this project, we invested more than 100 hours iterating on the structure and instructions for the individual sections of the postmortem until they played well together with diverse inputs. This process involved tackling the common challenges of non-determinism with LLMs, such as failing to adhere to instructions, inconsistent formatting, repetition, and occasional hallucinations. All of these issues are manageable if you’re conversing with ChatGPT or Claude iteratively using prompts that were written ad hoc, but are less so as part of a hardwired feature.
Working with LLMs is a fundamentally new type of skill that lies at the intersection of software engineering, product management, data science, and technical writing. It requires learning new patterns and frameworks, and the challenges we observed largely fell into the following three categories:
- Data quality and hallucinations
- Cost, speed, and quality trade-offs
- Trust and privacy
Data quality and hallucinations
Ensuring the accuracy of postmortems is critical, as they encapsulate crucial organizational progress and learnings. Unlike in other LLM use cases, such as creative writing, sticking to the facts is essential. LLMs almost always create output that sounds polished and grammatically impeccable, but they are also inherently non-deterministic and may produce hallucinations—false information generated to fit given constraints. Our challenge then was to ensure that the LLM produced insights that were truthful, valuable, and detailed while maintaining a high level of consistency across postmortems.
Balancing structured and unstructured data was another hurdle. For instance, fields like “Customer Impact” in Datadog Incident Management, which are manually filled out by incident commanders or responders, tend to be more accurate for that reason but can also become outdated quickly. Unlike those static fields, LLMs do not require continuous manual updating and can constantly reevaluate and analyze unstructured information (such as live discussions in Slack) in the moment to draw more current conclusions.
Cost, speed, and quality trade-offs
We explored different model alternatives like GPT-3.5 and GPT-4 to evaluate their specific strengths in terms of cost, speed, and the ability to return high-quality results, which could differ up to a factor of 50x. GPT-4, for example, was more accurate but also significantly slower and more expensive.
Trust and privacy
The postmortem writing process is indispensable for uncovering non-obvious insights and enabling organizations to learn from past issues in order to avoid them in the future and improve resilience overall. Therefore, if AI generates a draft that users mistakenly accept to be final, it would hinder the essential learning process. It was key to ensure that the AI-assisted drafts did not take away the authors’ agency but rather supported them throughout the process and made sure they were always in control. Additionally, due to the sensitive nature of incidents, we also wanted to prevent the sharing of particularly sensitive information and secrets with the LLM as an added layer of privacy.
Limiting hallucinations, increasing accuracy, and generating output more quickly
To reduce the likelihood of hallucinations in LLM-generated content, we adopted an approached focused on refining LLM instructions with both structured and unstructured data. Our primary goal was to ensure the accuracy and reliability of the generated drafts while keeping the human author in control of the process.
Establishing an experimentation framework
We began with the development of a custom API that extracted the required data from our incident management product and other sources like Slack. It automatically structured the data for quick experimentation and scrubbed sensitive information before providing it as input to an LLM. This step was important not only for maintaining an additional layer of privacy but also for enabling rapid iterations using different datasets, incident information, and model architectures. By allowing us to tweak various parameters such as model type, input settings, and output token limits, we could quickly refine our approach and compare results on the fly.
With the data extraction framework in place, we focused on experimenting with different frameworks to provide the LLM with instructions alongside the input data. Our objective was to recommend content for the postmortem drafts in a manner that preserved the human author’s control. Each iteration was designed to balance structured information from Datadog—such as alerts, incident metadata, and shared graphs—with more current and unstructured data from Slack discussions.

To address the non-determinism of LLMs, we implemented several safeguarding mechanisms to enhance output reliability. By integrating structured input information from Datadog with unstructured data from Slack, we could capture the full scope of the incident and tell the LLM which information to prioritize based on its context. Additionally, we lowered the model temperature and adjusted other LLM parameters to further reduce the likelihood of generating false or irrelevant information.
Last but not least, we developed an adjacent project at the same time to provide LLM-generated incident summaries that help responders get up to speed quickly when they join corresponding Slack channels. These summaries had to meet an equally high quality bar but were more compressed and therefore easier to generate with less potential for hallucinations. They were also generated much more frequently, which gave us a testing ground for rapid iterations on using LLM on incident data which we fed back into the postmortem project.
Evaluating model output and feedback loops on postmortem drafts
Evaluating the quality of AI-generated postmortem drafts involved a combination of both qualitative and quantitative methods to assess the outputs and refine our processes continuously. We conducted qualitative surveys with authors of previous postmortems to validate our approach. These surveys compared their human-written versions with AI-generated drafts for the same incidents based on a few questions:
- Accuracy: Is the information in the postmortem true?
- Conciseness: Are there any unnecessary details or repeated information?
- Organization and coherence: Are the sections logically arranged and consistent with the given template, and does the content flow well?
- Coverage: Does the postmortem cover all key events from throughout the incident?
- Objectivity: Does the postmortem exhibit bias, personal opinions, blaming, or subjective interpretations?
The feedback from these surveys was invaluable and provided insights into the completeness and accuracy of the AI outputs across several template iterations. This enabled us to use the strongest performing instructions and configurations from each section in the final version of the template. As an example, this is the result of one of the evaluations comparing the first and second versions of the template:
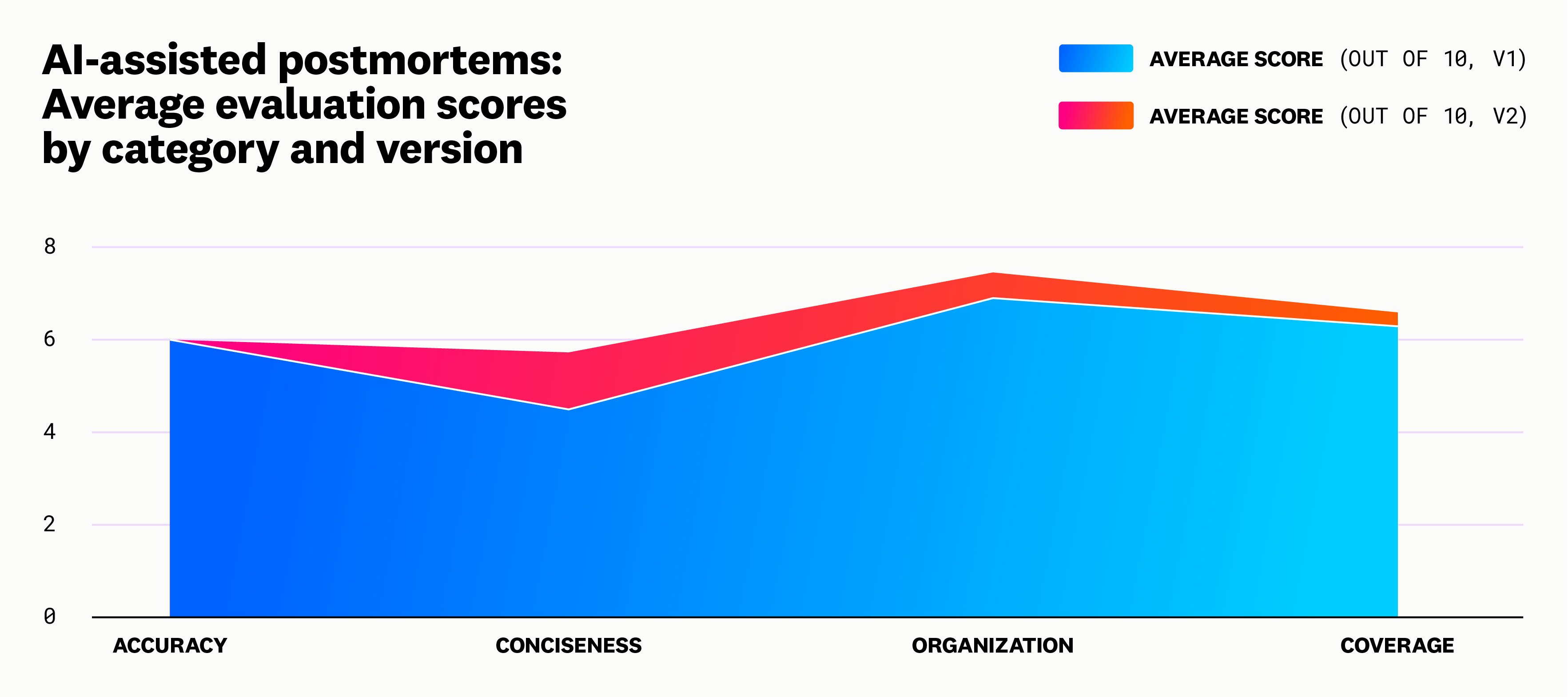
In addition to surveys, we performed qualitative comparisons between human-written and AI-generated postmortems. These comparisons pinpointed areas needing improvement, which enhanced the overall accuracy of the drafts. We found that LLM-generated postmortem drafts performed well in the context of recalling exact events backed by resources like Datadog logs. On the other hand, human-written postmorterms did better in describing the context of the overall technical infrastructure and the next steps to ensure the problem doesn’t occur again.
We also experimented with quantitative scoring metrics such as ROUGE/BLEU, two commonly used metrics for evaluating the quality of machine-generated text. In our case, we applied them to measure the similarity between AI-generated and human-authored postmortems. These metrics measure the overlap in n-gram words, but don’t take into account the greater context, relationship, and meaning of the document—all of which may be present in a human-authored postmortem. This ended up providing only limited insights, though, as high similarity scores did not always equate to factual accuracy or completeness. This highlighted another challenge when benchmarking AI against human output—uncertainty about whether a given human-authored postmortem was actually a more accurate reflection of reality.
Another challenge was that, while we provided metadata about the incident for the LLM, we did not provide data about the infrastructure in this first stage of the implementation. This meant that the LLM was not able to derive relationships, causes, and next steps from this information—which is a crucial part of learning from postmortems.
Finding the right cost, speed, and quality trade-offs
Balancing cost, speed, and quality was also a priority, as we wanted to enable this process at scale and with an acceptable end-user experience. To enhance speed and accuracy, we used multi-step instructions, breaking down the task into sections and processing them in parallel. This approach allowed us to generate content more efficiently while maintaining a high quality. By handling each section separately but concurrently, we could reduce the overall time required for the AI to produce a comprehensive draft from over 12 minutes to under one minute. This could likely be reduced to just a few seconds, given the recent rapid advancements in LLM inference speed. The downside of our approach was that the concurrently generated sections tended to overlap, and additional quality control was necessary to avoid repetition.
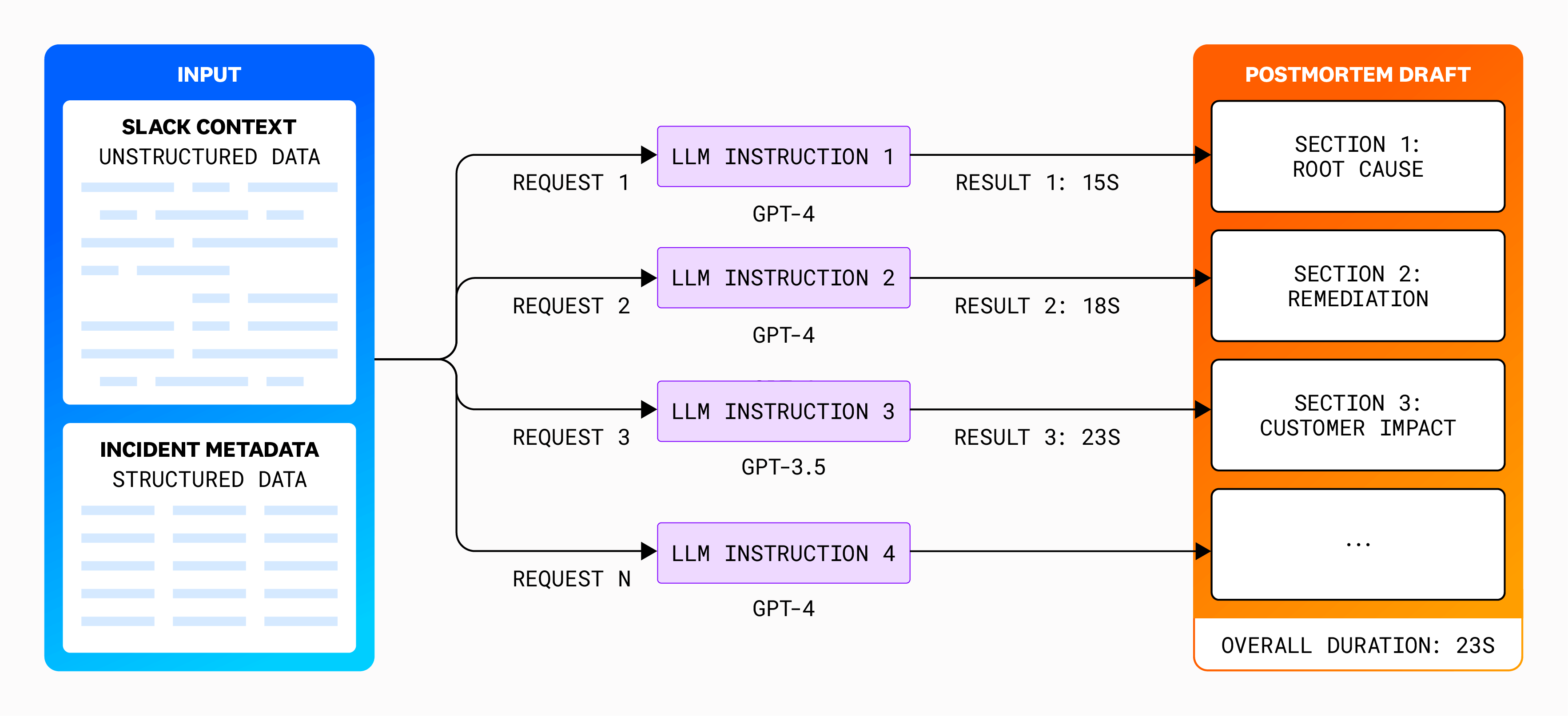
For cost efficiency, we implemented a hybrid model approach, selecting different models for different sections. This way, we leveraged the strengths of various models without incurring the high costs associated with using a single, more expensive model throughout the entire process when it wasn’t necessary. For instance, simpler sections could be handled by less costly models, while more complex sections used advanced models like GPT-4.
We also experimented with different model architectures to find the optimal trade-off. For example, we compared the context windows of GPT-3.5 Turbo (which offers 16,385 tokens) with GPT-4 (initially providing 8,192 tokens and later increased to 128,000 tokens but with a 4,096 token output limit for GPT-4 Turbo). This flexibility allowed us to adapt to different needs and constraints, ensuring that we used the most appropriate model settings for each specific task; for example, lowering the frequency penalty of the LLM to decrease the model’s likelihood of repeating the same lines verbatim.
After the initial content generation, we used additional LLM queries to refine the outputs. This included removing redundant statements and reinforcing structure by converting free text into bullet points and other structured formats. This refinement process enhanced clarity and readability, making the drafts more user-friendly and easier to understand.
To ensure that the postmortem drafts were comprehensive and well-informed, we also experimented with enriching the incident context by incorporating internal documentation. This included descriptions of systems and services from Confluence, which added depth and accuracy and relieved the author from having to find obvious internal resources and references.
Programmatically addressing trust and privacy issues
Ensuring trust and privacy when using LLMs to generate postmortem drafts was a critical aspect of our approach. We implemented several strategies to tackle these issues programmatically as part of building a reliable and secure system.
Given the sensitivity of technical incidents, protecting confidential information was paramount. As part of the ingestion API, we implemented secret scanning and filtering mechanisms that scrubbed and replaced suspected secrets with placeholders before feeding data into the LLM. Once the AI-generated results were retrieved, placeholders were filled in with the actual content, ensuring privacy and security throughout the process.
To enhance the credibility of AI-generated statements, we also ensured that important insights were backed by citations from relevant sources, such as specific Slack messages. This transparency can allow users to verify the information, increase trust, and address potential skepticism about AI-generated content in general. Additionally, we incorporated a feedback mechanism within the system, enabling users to flag issues such as content being “too long,” “too short,” or “inaccurate.” This feedback loop was key for iterative improvements of the outputs and could later even be turned into an automated, continuous training cycle of the underlying AI model.
We also addressed the goal of assisting rather than replacing the author via the user interface, because the thought process that an incident responder goes through when writing a postmortem is as important as the final postmortem document. Postmortem drafts were clearly marked as such, with disclaimers, examples, and instructions included. This approach positioned the AI as a supportive tool that acted as a helper instead of taking the human author’s place. To further this goal, we visually distinguished between AI-generated text and human-written content, allowing postmortem authors to easily identify which parts of the draft were machine-generated. This clear differentiation fostered understanding and trust in the collaborative process, with AI-generated content produced step-by-step, providing opportunities for iteration and refinement.
We also enabled users to customize the postmortem template fine-granularly by providing a placeholder for each instruction so that they could customize and augment the context of LLM-generated statements.
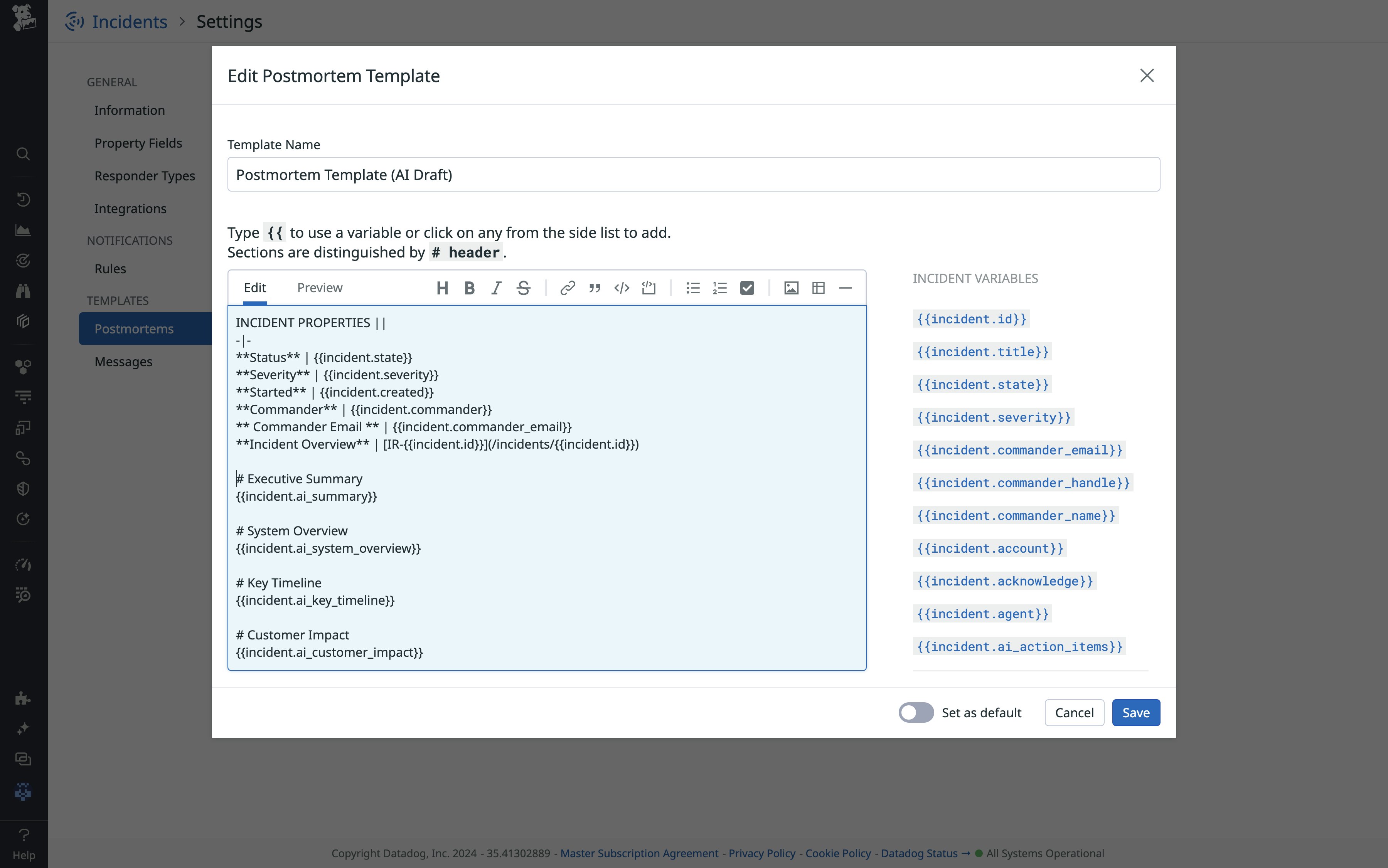
Transparency was further enhanced by providing the main instructions used by the AI in clear text within the template. By allowing users to see and understand the requests to the LLM, we increased trust in the system and empowered them to adjust and create new instructions at a later stage to better fit their needs. This flexibility ensures that the system can evolve and adapt to different scenarios and organizational preferences.
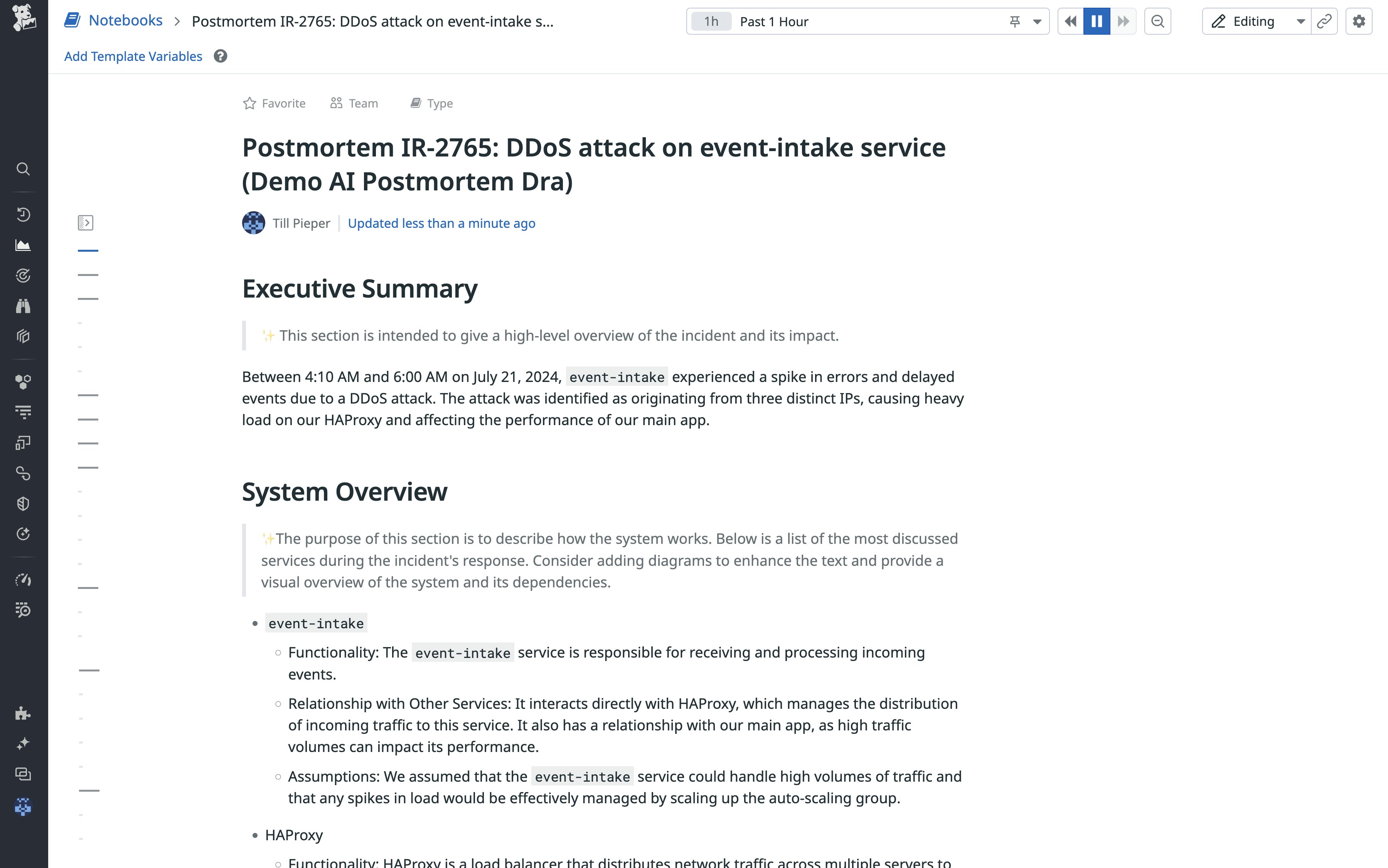
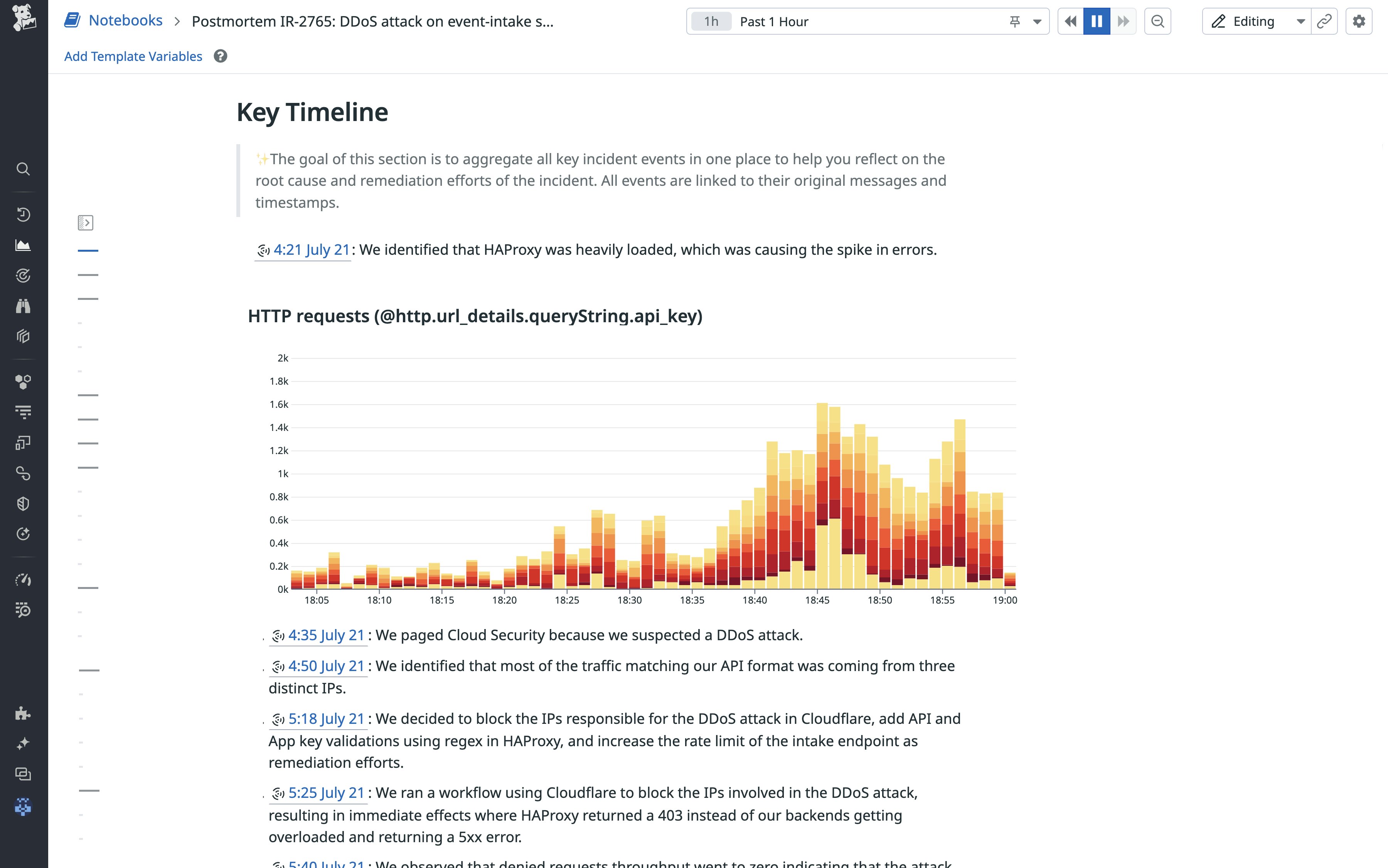
Key takeaways
We found that LLMs are generally capable of analyzing extensive unstructured data related to incidents and can give postmortem authors a head start—but not replace them—when capturing incident context comprehensively. At times, the LLM provided overly general statements that did not accurately reflect the investigative progress. For example, it sometimes over-indexed on outdated earlier statements in Slack without noticing that they were referring to the same matter, such as “the incident affected all regions” being superseded by “only customers connected to US West experienced data loss.” This meant that the first implementation was more effective in drafting postmortems for the long tail of incidents with mid to lower severities (e.g., from SEV5 to SEV2).
Overall, we came to think of engineering instructions for LLMs in the context of static production use cases as a new sub-function of software engineering. It took many iterations to align the LLM output with user expectations. The challenge was to maximize time savings and trust in the output for postmortem authors without skipping the essential learning process of writing the postmortem, which is still its primary objective.
Over the course of the project, we implemented a few components that built on the strengths of LLMs while limiting the negative effects of their inherent shortcomings:
- Combining structured information—such as alerts, incident metadata, human-edited fields, and shared graphs—with unstructured, summarized information from Slack discussions generated more comprehensive postmortem drafts.
- Using specialized model configurations and instructions for individual postmortem sections enabled a more effective cost/benefit trade-off, which was key given quickly changing model architectures, context windows sizes, processing speeds, and cost structures.
- Parallelizing queries increased speed and improved accuracy but led to duplicate results, particularly in related sections such as “What Happened” and “Root Cause.” Adding additional calls to LLMs to fact-check and avoid duplications of previously generated output helped improve accuracy.
- The combination and ease of using both qualitative and quantitative evaluation methods of the results generated by LLMs was critical when iterating on the underlying data sources and instructions.
- UX-focused improvements such as adding disclaimers and highlighting AI-generated text helped build trust with users and emphasize that they were still accountable for investigating in depth and ensuring that all key learnings were captured.
What’s next
Looking ahead, we will explore additional customization options, assistance in the moment while the postmortem is edited, and additional data sources to provide even more relevant incident context. For example, we expect a major improvement in output by giving the LLM more access to information about the underlying technical infrastructure from sources like internal wikis, RFCs, and system information in conjunction with Datadog’s Bits AI. Finally, given their ability to transform text for different purposes and our developed methods for filtering confidential information, we may test using LLMs to generate alternative versions, such as custom postmortems for individual clients or even public postmortems.
Interested in working with teams using AI to optimize monitoring workflows? Datadog is hiring!



