

When it comes to reducing cloud costs, optimizing bottlenecks in your code can only take you so far. It may be time to rethink your architecture. Perhaps you’re looking for a new architecture that takes into account the capabilities that modern hardware and software make available. One such architecture is called “thread-per-core”. Research recently demonstrated that a thread-per-core architecture can improve tail latencies of applications by up to 71%. That sounds fantastic, but the machine efficiency gains of thread-per-core can easily be negated by the loss of developer productivity when your application developers have to adjust to a completely new way of doing things and deal with a set of arcane challenges that are specific to this particular model.
Datadog is not immune to those problems. We run a variety of datastores at scale, which ingest metrics at a very high throughput. And we, too, were starting to see how some of our components’ existing architecture was beginning to show limitations. Metrics data, with its very high distribution in space, looks like a prime candidate for a thread-per-core architecture—but we were concerned about keeping the effort manageable.
This article will explore the thread-per-core model with its advantages and challenges, and introduce Glommio (you can also find it on crates.io), our solution to this problem. Glommio allows Rust developers to write thread-per-core applications in an easy and manageable way.
What is thread-per-core?
We know that thread-per-core can deliver significant efficiency gains. But what is it? In simple terms, any moderately complex application has many tasks that it needs to perform: it may need to read data from a database, feed that data through a machine learning model, and then pass that result along the pipeline. Some of those tasks are naturally sequential, but many can be done in parallel. And since modern hardware keeps increasing the number of cores available for applications, it is important to efficiently use them to achieve good performance numbers.
The simplest and most time-tested way of doing that is by employing threads: for each of its internal tasks, the application may use a different thread. If a thread has available work to do, it will do it; otherwise, it will go to sleep and allow the next one to run.
The shortcomings of threaded programming are:
- When multiple threads need to manipulate the same data, they need to acquire locks to guarantee that just one of these threads will make progress at a time. Locks are notoriously expensive, not only because the locking operation itself is expensive, but also because they increase the time the application is doing nothing but waiting.
- Every time a thread needs to give way to another thread, there is a context switch. Context switches are expensive, costing around five microseconds. That doesn’t sound expensive, but if we take into account that famed Linux Developer Jens Axboe just recently published results for his new io_uring kernel infrastructure with Storage I/O times below four microseconds, that means that we are now at a point where a context switch between threads is more expensive than an I/O operation!
Not all threaded programming needs to be blocking: recently, languages and frameworks like Go, Node.js, and many others brought asynchronous programming into full force. Even C++ has futures and more recently coroutines as part of its standard, and so does Rust, our star of the day.
Asynchronous programming is a step in the right direction, allowing programmers to check for work instead of blocking waiting for work. But asynchronous support for those languages often still depends on thread pools for operations like file I/O, and on separate tasks inside the application in their own threads.
Thread-per-core programming eliminates threads from the picture altogether. Each core, or CPU, runs a single thread, and often (although not necessarily), each of these threads is pinned to a specific CPU. As the Operating System Scheduler cannot move these threads around, and there is never another thread in that same CPU, there are no context switches.
There are still context switches coming from hardware interrupts, and other helper tasks, like agents, that may share the machine. For maximum performance, operators can configure the operating system so that some CPUs are not given to the application and are instead dedicated to those tasks.
Using Sharding
To take advantage of thread-per-core, developers should employ sharding: each of the threads in the thread-per-core application becomes responsible for a subset of the data. For example, it could be that each thread will read from a different Kafka partition, or that each thread is responsible for a subset of the keys in a database. Anything is possible, so long as two threads never share the responsibility of handling a particular request. As scalability concerns become the norm rather than the exception, sharding is usually already present in modern applications in one form or another: thread-per-core, in this case, becomes the cherry on top.
Each asynchronous callback, now assigned unequivocally to a single thread, also runs to completion: since there are no other threads, nobody can preempt the running request: it either finishes or explicitly and cooperatively yields.
The biggest advantage of this model is that locks are never necessary. Think about it: if there is a single thread of execution, two things can’t be happening (for that request) at the same time.
Take, as an example, adding an element to a cache. In a simple threaded environment, updates to the cache can be happening from multiple threads, so one needs to obtain a lock like we see below:
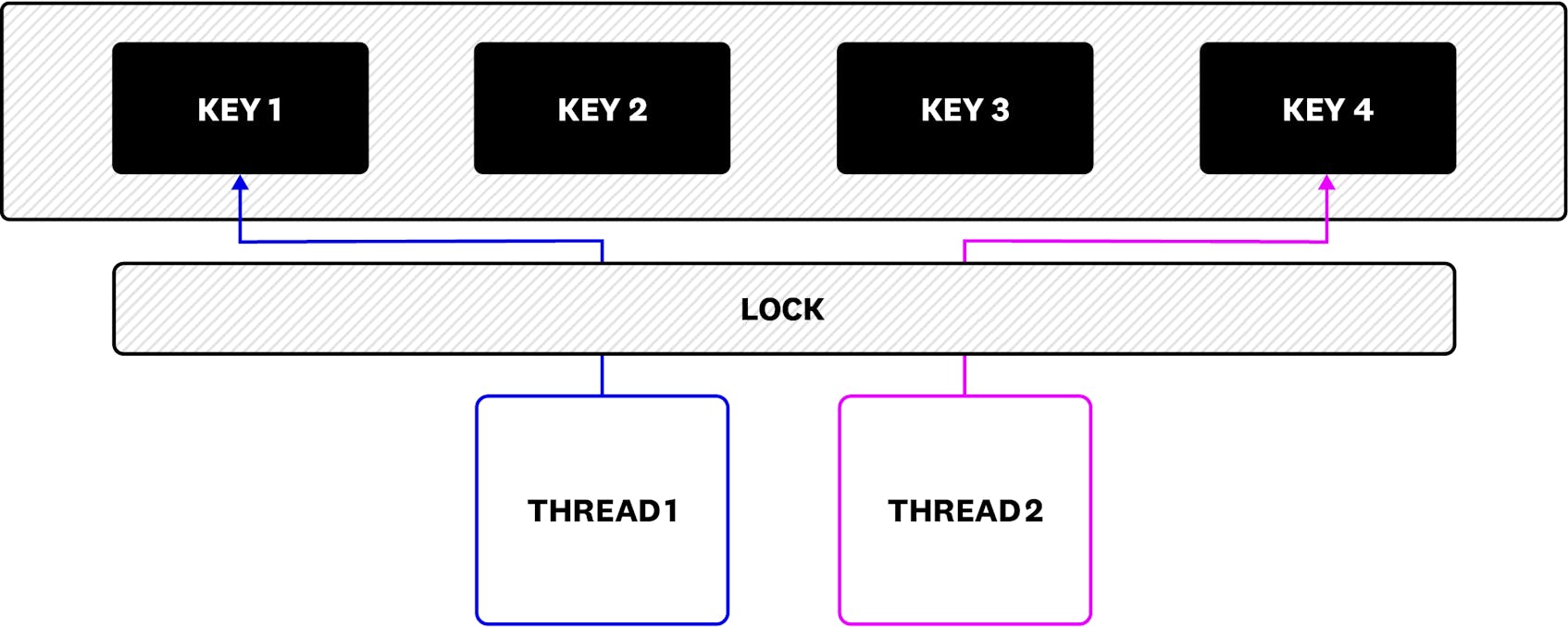
By itself, sharding already presents advantages: by splitting the big cache into smaller parts, we can reduce lock contention. Now it is possible to access Key 1 and Key 3 at the same time, and each shard will have its own lock. But because each thread can still be removed from the CPU by the operating system, and the new thread that takes its place can access Key 4—which lives in the same shard as Key 3—there is still a need to hold a lock to coordinate updates.
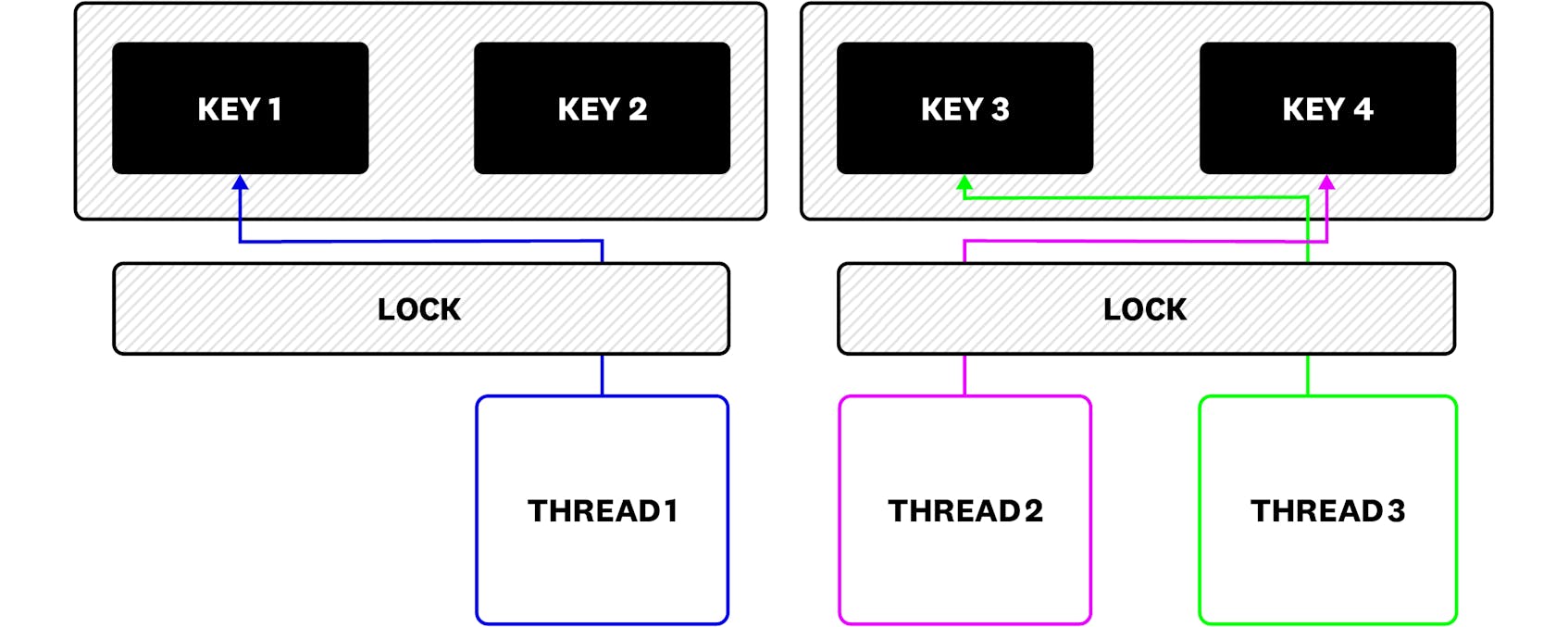
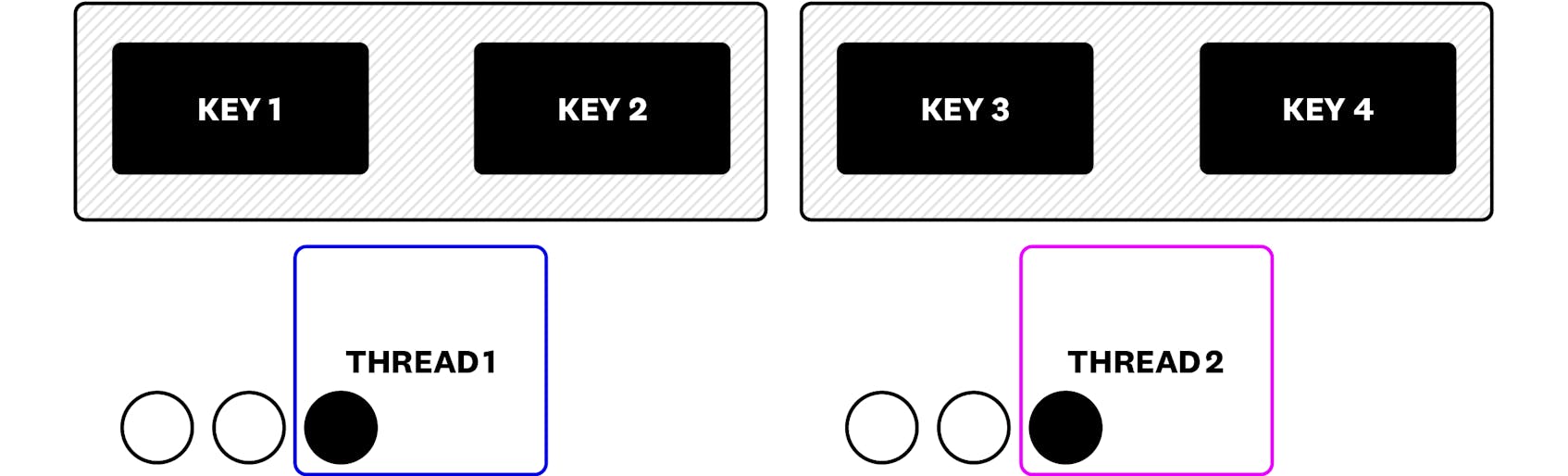
The thread-per-core design takes this one step further: we know that updates to Key 3 and Key 4 are serialized. They have to be! If they run in the same thread, then we are either operating on Key 3 or Key 4, never both. So long as we finish the update before declaring the task complete, the locks are gone. As we can see in the figure below, all possible update tasks for each of the cache shards are naturally serialized, and only one (in purple) runs at a time. So as long as it finishes its update before leaving the thread, locks are not necessary.
Did you just come up with all of that??
I wish! Thread-per-core has been around for a while. As a matter of fact, for many years before I joined Datadog, I worked in a thread-per-core framework for C++ called Seastar, the engine that is behind the ScyllaDB NoSQL database. ScyllaDB managed to leverage the thread-per-core model to provide more efficient implementations of existing databases like Apache Cassandra, so I knew that the model would work for our datastores too while keeping the complexity manageable.
However, it is not my intention to go into a language flamewar here. We had reasons not to pick C++ for this particular problem and chose Rust. The next step was to enhance the Rust ecosystem so that we could have a similar tool. If you are curious to read more about my take on how C++ and Rust compares for this particular task, you can check my writeup on the subject.
But I still need to run multiple tasks on the same data. What do I do?
Consider the example of an LSM tree, a data structure commonly used in modern databases. Data sits in a memory area for a while and is then written to immutable files. There is sometimes a need to combine those files together to prevent reads from becoming too expensive.
Some of those operations can be quite expensive and long-lived—which is why, traditionally, threads are employed. By using threads, the application can count on the operating system to preempt long-lived tasks and make sure important tasks are not starved. And all the locking is just considered the fair price to pay.
But how does that work in a thread-per-core application? Glommio allows the application to create different queues of execution:
let not_latency = Local::create_task_queue(Shares::Static(1), Latency::NotImportant, "test";
let latency =
Local::create_task_queue(Shares::Static(1), Latency::Matters(Duration::from_millis(2)), “testlat”);
)
In the example above, two queues are present. Tasks, when created, can be spawned in any one of them. Aside from its name, we can specify two things about each class:
- Its latency requirements: Glommio behaves differently in the presence of latency sensitive tasks, prioritizing their I/O operations.
- Its shares: in the example above, both classes have equal shares. Glommio has its own internal scheduler, which selects which task queue to run and provides each with time proportional to its shares. A task queue with twice as many shares as another will, over time, run for twice as long. In this example, they should both use 50% of the system’s resources as they have an equal number of shares.
What about I/O ?
Linux dominates modern cloud infrastructure. And Linux has recently seen a revolution in its I/O capabilities driven by a new asynchronous API called io_uring. I have written at length about its capabilities in the past. Io_uring is capable of not only processing file I/O, but also network sockets, timers, and many other events over a single common API.
By leveraging io_uring from its inception, Glommio can take a fresh look at how I/O is supposed to look like in Rust. Let’s dive deeper in the architecture.
Usually, a normal threaded application registers a single io_uring for the entire application, which can create contention when adding or completing requests. This is the approach taken by other Rust io_uring crates like ringbahn and rio (Tokio, as of this writing, employs normal threads pools for file I/O).
For each thread of execution, Glommio registers its own set of independent rings that can be operated locklessly. Sets? Yes! Each thread operates with not one, but three rings, each playing a different role.
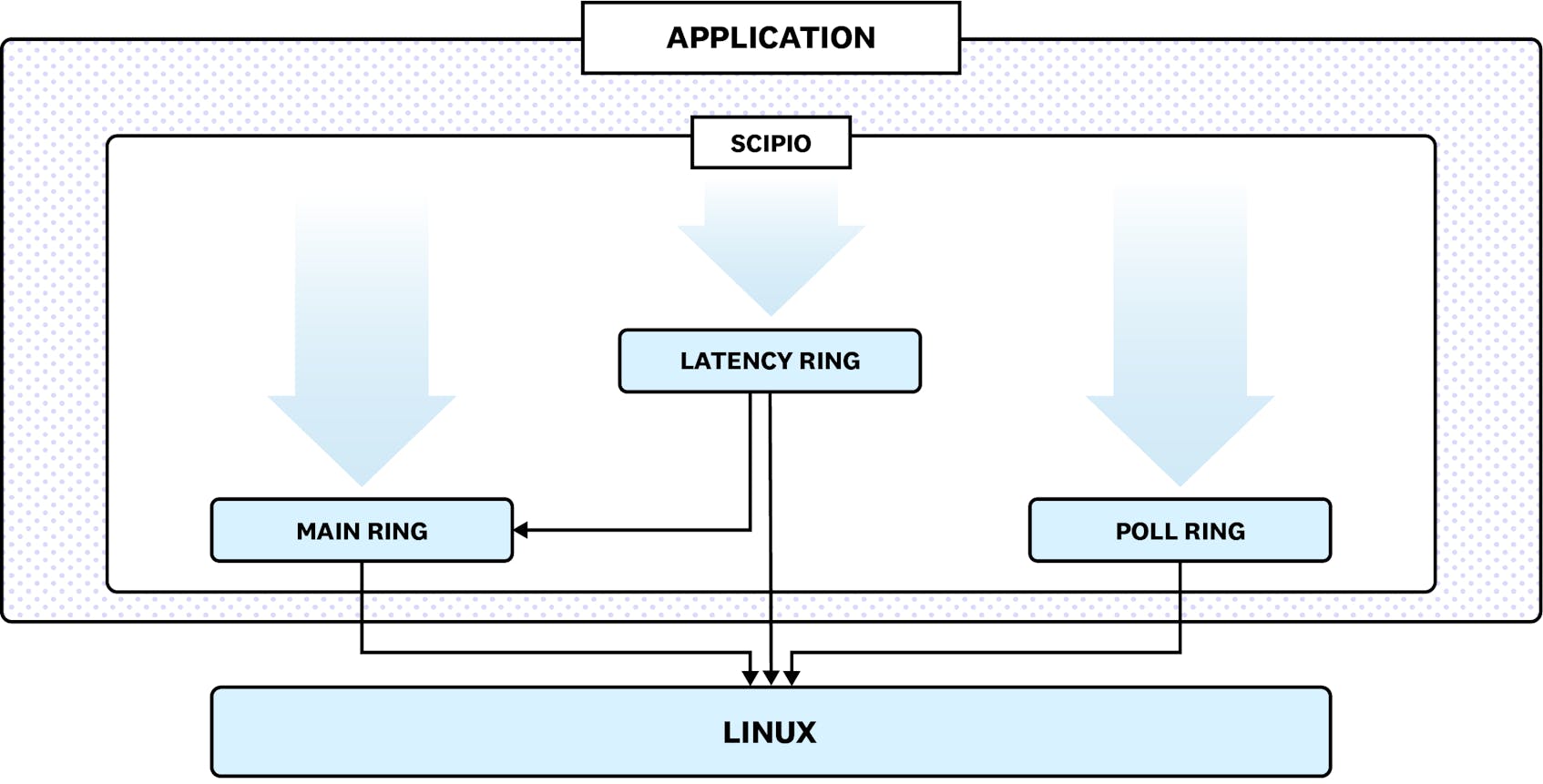
A normal request, like opening or closing a file, sending or receiving data from a socket, will go on either the Main or Latency rings, depending on its latency needs.
When those requests are ready, they post into io_uring’s completion ring and Glommio can consume them. Due to io_uring’s architecture, there is not even a need to issue a system call. The events are present in a shared memory area between Linux and the application and managed by a ring buffer.
What is the difference between those two rings? By its nature, the thread-per-core model is cooperative when it comes to scheduling: if tasks could be yanked from the CPU without noticing, we wouldn’t be able to employ lock-free programming. So they have to voluntarily yield control whenever they have run for too long.
How long is too long? A task that is going to do some long-lived operation (like a loop of unknown size), should call a Glommio function called yield_if_needed(). Here is an example:
// Now busy loop and make sure that we yield when we have too.
loop {
if *(lat_status.borrow()) {
break; // Success!
}
Local::yield_if_needed().await;
}
This code employs a loop until a certain condition holds true, which can take a long time. Other tasks may become starved if the user doesn’t call yield_if_needed(). This function takes direct advantage of io_uring’s architecture. Let’s recall how a ring buffer is supposed to operate:
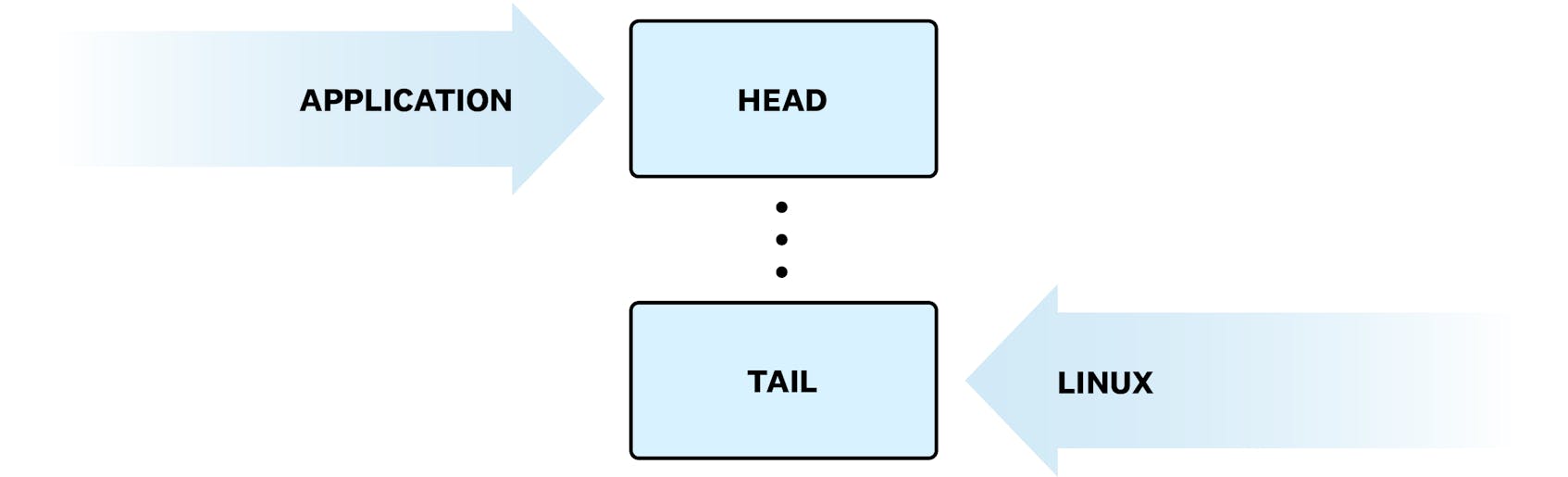
Applications consume events from the head of the buffer and move its position when done. Linux posts events to the tail of the buffer and similarly moves its position when done. Because that happens in a shared memory area, we can, at any time, know if there are pending events in the ring. This is also very cheap: all we need to do is read two integers and compare them, which doesn’t add a significant amount of cost to those loops.
But our implementation of yield_if_needed() only looks at the Latency ring. An application could, for instance, listen on two sockets: one of them for queries that have to be served as soon as possible with good latency, and another for queries for which throughput matters more.
If a query arrives in the throughput oriented socket, other running tasks will not yield immediately. When the query does have control of the CPU, it will have it for longer. Over time, Glommio’s scheduler will ensure that each class runs for a fair amount of time, but each block of time will be longer.
But if a query arrives in the latency oriented socket, other tasks will know about it and yield.
The attentive reader will have noticed a link between the main ring and the latency ring in the figure. Although a bit of implementation detail, that is the cherry on top of this architecture. When there is no work left to do, the thread where the executor lives goes to sleep. It is possible to go to sleep by blocking in the io_uring: it will automatically wake up when there are events. However, a blocking call will, by definition, block and won’t execute anything else. So it is only possible to wait for one of the rings.
One of the many operations that io_uring supports is poll, which notifies us of activity in any file descriptor. And because io_uring itself has a file descriptor, it is possible to poll on that too. So before Glommio issues a blocking call for the main ring, it registers the latency ring’s file descriptor for poll onto the main ring. If there are any events in the latency ring, it will generate activity in the main ring which will in turn wake up.

The last ring is the poll ring. It is used for read and write requests coming from an NVMe device. Usually, storage I/O requests generate an interrupt when they are ready, causing Linux to stop what it is doing to handle them, which generates yet another context switch.
Requests that go through the poll ring do not generate interrupts, but instead rely on Glommio to explicitly poll, or ask the kernel, at its own time and discretion when they are ready. That reduces the context switch penalty even more and is especially important for workloads that can generate small requests. For example, if a user wants to generate an alert on a specific point in a timeseries, which is no bigger than a couple of bytes.
Because requests in this ring do not generate interrupts, that means that we cannot go to sleep if there are pending I/O requests that haven’t been completed. So it doesn’t need to be linked to the other rings. Does that work with Kubernetes?
Linux is ubiquitous in the modern datacenter, to the point that we can take advantage of Linux-only APIs like io_uring to bring things like Glommio to fruition. But another technology that is slowly but surely reaching that status is Kubernetes. Kubernetes is a flexible abstraction, where pods can be running everywhere. That begs the question: will a thread-per-core architecture do well on Kubernetes?
The answer is yes: thread-per-core applications will run on any Kubernetes infrastructure. However, best performance will come from matching the application to the physical cores available in the underlying hardware. To do that effectively:
- Avoid oversubscription of resources
- Assign pods to specific nodes
- Limit pods to specific CPUs
- Isolate hardware interrupts, so they are outside the pod
Most of those things are already done by many organizations when running stateful sets, which is where the need for reliable and consistent performance comes from.
I like it! What now?
As hardware gets faster and more feature rich, it is important to bring applications in line with new techniques to take full advantage of what the hardware provides. Modern applications that need to be sharded for scalability are prime candidates for using a thread-per-core architecture, where each CPU will have sole control over a fragment of the dataset.
Thread-per-core architectures are friendly to modern hardware, as their local nature helps the application to take advantage of the fact that processors ship with more and more cores while storage gets faster, with modern NVMe devices having response times in the ballpark of an operating system context switch.
For all the advantages, thread-per-core architectures can be daunting and complex, which is why we wrote Glommio. Glommio builds upon Rust’s native asynchronous support and Linux’s innovative event-based io_uring API to build a thread-per-core library that is easy to consume.
Glommio is an open source project, available on Github, and on crates.io. If you find a use for it, we’d love to hear about it! We now have community at Zulip Chat. As you can see, Datadog is pushing the envelope in terms of what the modern datacenter looks like. If this kind of problem interests you, we’re always looking for talented engineers to join us!
