

It is a trusted premise of software engineering that we build large systems from smaller components, each of which can be designed and tested with a high degree of confidence. Some design problems, though, only become evident at the system level, and the absence of reliable methods for testing system-level issues can sometimes take us by surprise. Decisions that are legitimate at the component level can have unexpected and sometimes dramatic consequences at the system level. Our global outage on March 8, 2023, was a humbling example of this, and it set forth new goals for us, in both the short and long term.
One of these long-term goals is tackling the challenge of analyzing distributed systems. Distributed systems unlock orders of magnitude of higher scale and service availability, even in the face of zonal and regional failures—but they also introduce more complexity and new failure modes. Experience has taught us that it is nearly impossible to intuitively reason about the behavior of a complex distributed system of concurrently executing processes, even if it is composed of simple parts. Dealing with this additional complexity requires thorough testing of all forms—unit, integration, etc.—as well as testing failure modes, which is often done through chaos tests. These traditional methods for testing software systems focus on system description at the lowest level of detail. Still, higher-level design errors are the hardest to find and the most costly to fix.
To analyze a distributed system during its design phase, we can use additional techniques such as formal modeling and lightweight simulations to describe and ascertain complex system behavior at any desired level of abstraction, tracking it from concept to sometimes even code. They help verify the behavior of a system with multiple well-defined, interacting parts by using model checking to evaluate its properties in all possible design-permitted states.
We recently had the opportunity to use these approaches while working on a new message queuing service named Courier, which allows us to quickly and reliably deliver data across our platforms. In this blog post, we’ll be sharing what insights we gained into our Courier service by applying formal modeling, lightweight simulations, and chaos testing.
Formal modeling and simulations
In formal modeling, we use a high-level specification language to describe a software application and the properties it must satisfy. We then run these descriptions through a model checker that performs an exhaustive search of the states of the application and verifies that the properties are fulfilled.
However, there are aspects of a system that extend beyond whether properties are fulfilled—such as latency, cost, and scalability—that formal modeling cannot describe and verify. To account for this, we can additionally use lightweight simulation: we can build a replica of a system and execute it under controlled conditions to describe statistical properties. This method provides insights into performance characteristics under various real-world conditions and workloads.
There are some caveats to this approach. While modeling and lightweight simulation can validate the design of a system, they do not validate its implementation. These techniques also introduce overhead, as we must keep models and simulations up-to-date with the design of a system. Despite these tradeoffs, we felt that the value we’d gain by employing these techniques outweighed the cost while building Courier. For a foundational system like Courier, which was being designed for several Datadog products, including Workflow Automation and Synthetic Monitoring, reliability and correctness were essential. Further, Courier incorporated several lessons learned from the March 8 outage into its design, and we wanted a quick mechanism to validate and iterate upon these new ideas. And lastly, while unit testing and chaos testing are nonnegotiable parts of our development process, modeling and lightweight simulations provide an additional layer of validation.
Courier: a mission-critical, multi-tenant message queuing service
Before we discuss analyzing Courier, we’ll explain what it is. Many Datadog products rely on a queuing system that handles asynchronous task processing. We had used a Redis-backed queuing system for over a decade, but we began to encounter issues with throughput, scaling, and durability. After much discussion, we decided to implement a new queuing system, named Courier, with the following requirements:
- Multi-tenancy: Courier would be used by numerous teams or products within Datadog, so it needs to guarantee sufficient isolation between different tenants in the system.
- At-least-once delivery: Once a message is sent to Courier, the message must not be lost. The message must be delivered and acknowledged, or moved to a dead letter queue. This ensures that our users do not miss any notifications.
- Graceful degradation and high availability: Courier’s throughput should degrade linearly with available compute capacity. This requirement is a direct response to the outage on March 8, 2023, where a sudden loss of compute capacity caused a severe drop in throughput. By ensuring linear degradation, we aim to maintain partial service availability even when resources are constrained, preventing a complete service failure as experienced during the outage.
- Horizontal scalability: Courier’s throughput should increase linearly with compute capacity. This ensures that we can handle a proportionally larger workload, meeting growing demands without needing to redesign the system architecture.
Solving for multi-tenancy
To solve for multi-tenancy, we decided to have Courier backed by multiple FoundationDB clusters and have each tenant in the system sharded into a subset of these clusters such that no two tenants shared the exact set of FoundationDB clusters. Our plan was to start with eight clusters and shard each tenant into four clusters. With this configuration, Courier can support up to 70 tenants (8C4 = 70) tenants. With this approach, even if one tenant somehow managed to saturate or cause unavailability in its four clusters, all other tenants in the system would have at least 25 percent capacity available. This was sufficient for our use cases.
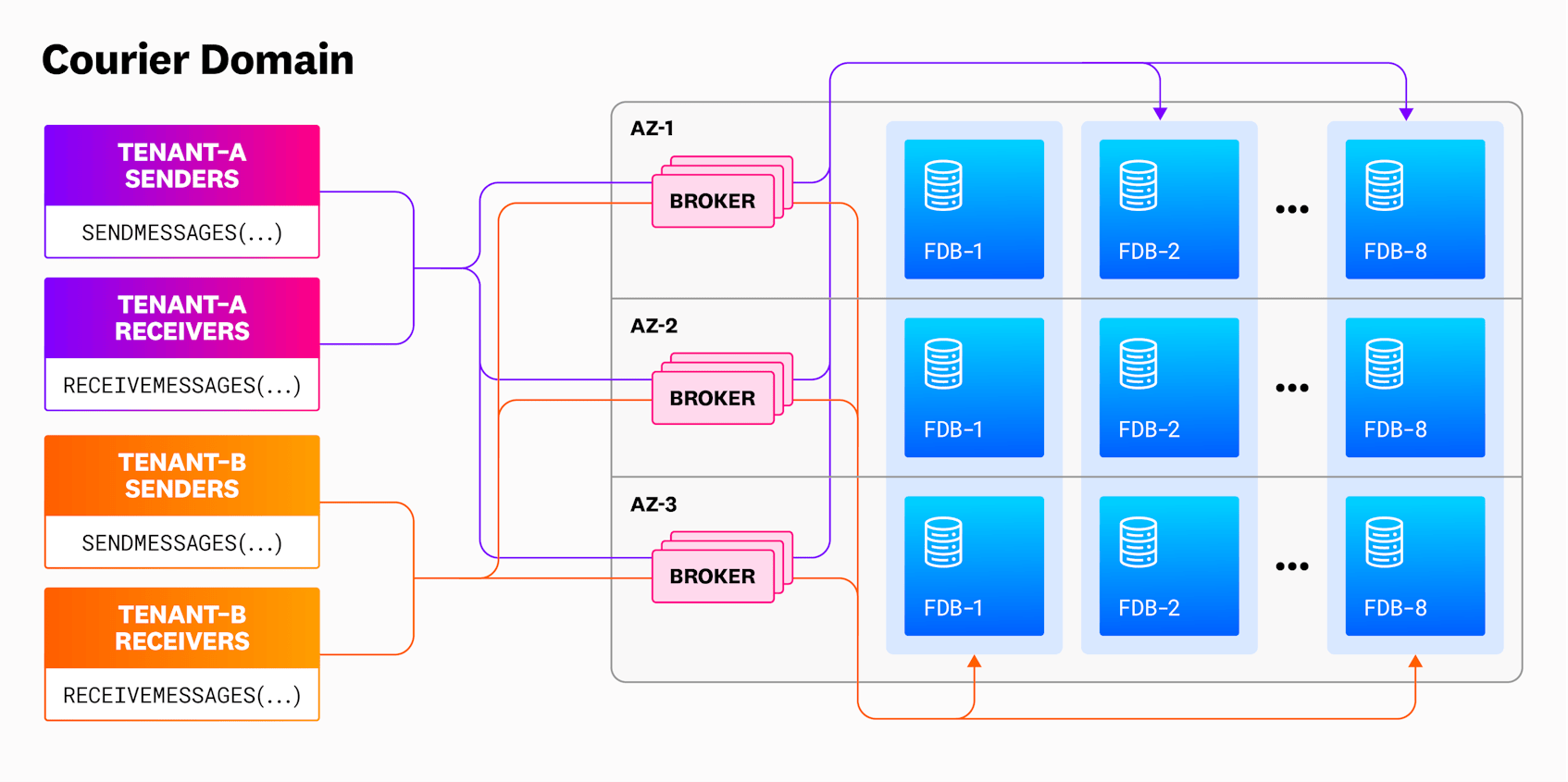
We also planned to have a broker layer that would expose gRPC APIs for sending, receiving, and deleting messages. All clients would connect to this API layer, where the sharding logic described above would happen. The brokers would also perform health checks on FoundationDB and exclude any clusters that were unhealthy. Both FoundationDB and the brokers are deployed across three availability zones for high availability.
The sequence diagram below shows what an example interaction would look like in Courier:
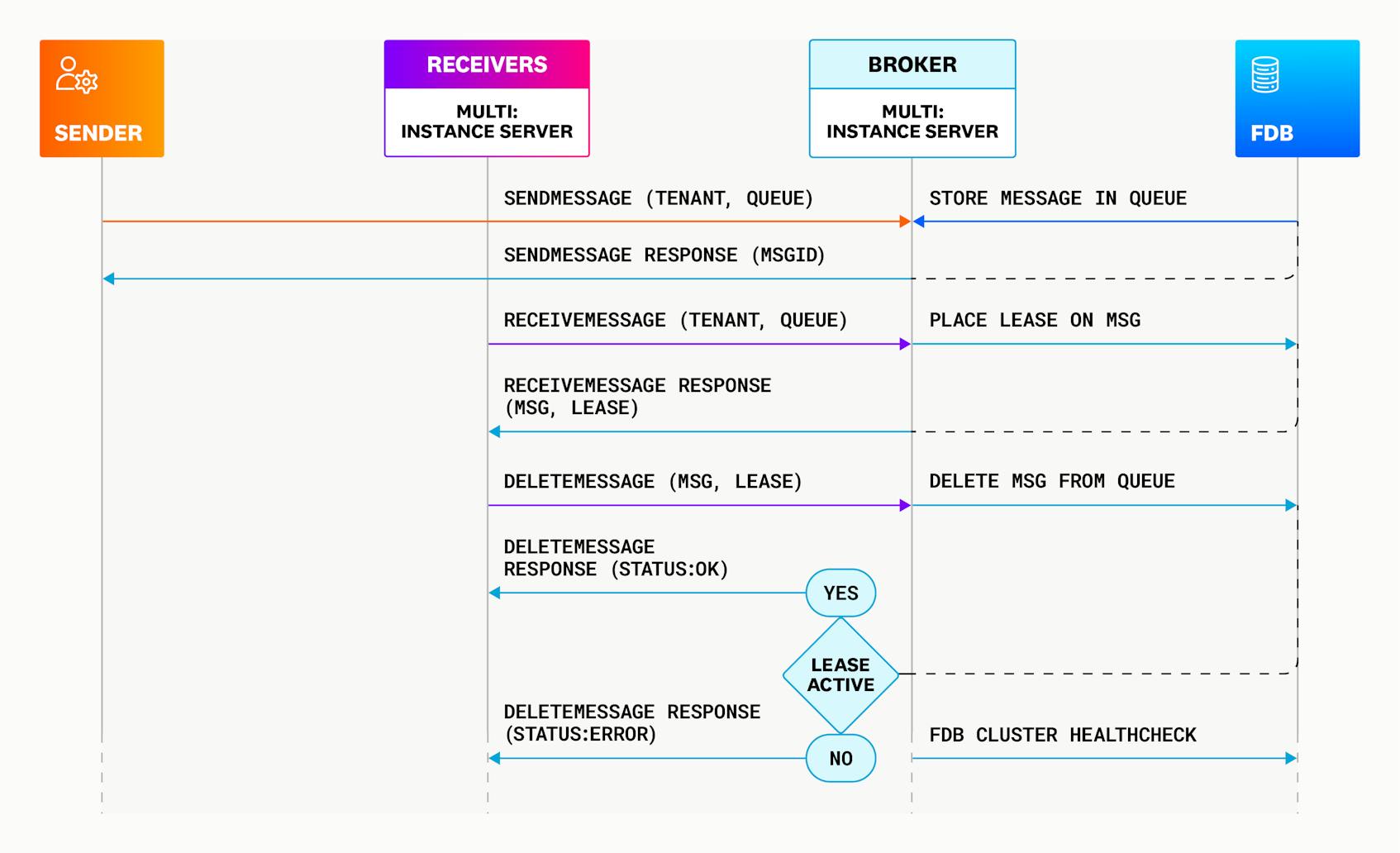
At this point, we had a detailed design document that described how the system worked, and we had used our collective experience to reason through the system’s failure modes, but we still didn’t have a definitive way to say if the system met all requirements. The use of various design elements, including multiple FoundationDB clusters and health checks, led to too many scenarios for us to consider. This was our impetus to formally model Courier.
TLA+
There are many ways to formally model a system—including TLA+, a formal specification language developed by Leslie Lamport. TLA+ provides a high-level language for expressing system specifications, capturing both the structure and behavior of a system. It allows us to precisely define system properties, explore different execution paths, and verify the correctness of the system against those properties. The power of TLA+ lies in its ability to express complex systems concisely and precisely, abstracting away unnecessary implementation details.
TLA+ comes bundled with a model checker called TLC, which takes a specification written in TLA+, performs an exhaustive search of the state space of the specification, and validates all states against any properties that we provide. If model checking passes, it implies that the properties we provided to TLC hold in every state that the system can exist in.
We’d previously used TLA+ to verify idempotency for Husky and to model a replication bug in one of Datadog’s distributed cron schedulers. Since we already had experience with TLA+, we decided to use it to model Courier as well.
TLA+ model overview
We modeled Courier as three processes:
- Broker: Handles SendMessage, ReceiveMessage, and DeleteMessage requests as well as performs health checks on FoundationDB.
- Sender: Dispatches SendMessage requests to the Courier Broker to submit messages to a queue.
- Receiver: Interacts with the Broker to receive and delete messages from the queue.
As mentioned earlier, modeling a system formally often requires specifying the system at a higher level of abstraction than the implementation. For Courier, we omitted a number of implementation details, such as the exact data structures that store messages in FoundationDB, and extended message leases. We even abstracted FoundationDB by representing it as a clusters variable in the model and updating it atomically:
clusters = [c \in 1..NumClusters |-> [t \in 1..NumTenants |-> [q \in 1..NumQueuesPerTenant |-> <<>>]]]
Abstractions allowed us to create a model with a relatively smaller state space, which in turn allowed us to test the system more broadly—and to use the model as a building block to explore interactions with external components. We can extend the model to describe and test specific aspects in more detail in the future if necessary.
Modeling state transitions
Models in TLA+ are described discretely; the system is described as a state machine where an event causes the system to transition from one state to another.
This is how we described the possible state transitions of Courier in TLA+:
Next == \/ (\E self \in Sender!ProcSet: SendMsg(self) \/ HandleSendMsgResponse(self))
\/ (\E self \in Receiver!ProcSet: ReceiveMsg(self) \/ HandleReceiveMsgResponse(self) \/ DeleteMsg(self) \/ HandleDeleteMsgResponse(self))
\/ (\E self \in Broker!ProcSet: ClusterHealthcheck(self))
\/ RestartBroker
\/ ClusterUnavailable
\/ ClusterAvailable
\/ Terminating
Spec == Init /\ [][Next]_vars
/\ WF_vars(RestartBroker)
/\ WF_vars(ClusterUnavailable)
/\ WF_vars(ClusterAvailable)
/\ WF_vars(Terminating)
/\ \A s \in Sender!ProcSet : /\ WF_vars(SendMsg(s))
/\ WF_vars(HandleSendMsgResponse(s))
\* only one receiver must always proceed, the rest can fail and stop at any stage
/\ WF_vars(ReceiveMsg(1))
/\ WF_vars(HandleReceiveMsgResponse(1))
/\ WF_vars(DeleteMsg(1))
/\ WF_vars(HandleDeleteMsgResponse(1))
/\ \A b \in Broker!ProcSet : /\ WF_vars(ClusterHealthcheck(b))
Next == specifies the possible next states of the system based on the current state and the enabled actions. This means that in the next state, the system can transition by performing any of these actions. In our case, it means that any of the following actions can be the next in the state transition:
- Any of the Senders sends a message or handles a Broker response
- Any of the Receivers receives or deletes a message, or handles a Broker response
- Any Broker instance performs a FoundationDB cluster health check
- Any Broker instance is restarted
- A FoundationDB cluster becomes unavailable
- A FoundationDB cluster becomes available
Spec == is used to define the overall specification or behavior of the system being modeled. It allows us to combine various properties, constraints, and initialization conditions into a single specification. For example, here we use WF_vars to specify weak fairness for all actions individually: weak fairness ensures that if an action is enabled infinitely often in the behavior of the system, then it must eventually occur. This allows for occasional skipping or delaying of the action, but the action cannot be indefinitely neglected or ignored. If we do not specify an action (or process) as fair, this indicates that the action can stop occurring at any time.
Modeling SendMessage
By default, Courier runs eight FoundationDB clusters and allows each tenant to be on four out of eight clusters. Writing tenant messages to multiple clusters ensures high availability and helps spread the load.
So how do we model handling a SendMessage request?
First, the Sender dispatches a request:
SendMsg(self) == /\ pcSender[self] = "SendMsg"
/\ IF Cardinality(senderMsgs) = 0 THEN
/\ pcSender' = [pcSender EXCEPT ![self] = "Done"]
/\ UNCHANGED <<**unchanged_vars**>>
ELSE
/\ LET msg == CHOOSE m \in senderMsgs: TRUE
IN \E b \in 1..NumBrokerInstances: Broker!SendMsg(b, msg, self)
/\ pcSender' = [pcSender EXCEPT ![self] = "HandleSendMsgResponse"]
/\ UNCHANGED <<**unchanged_vars**>>
The Broker processes the request and responds to it:
SendMsg(self, msg, sender) ==
LET cs == SelectSeq(tenantToCluster[self][msg.tenant], LAMBDA x: ~(x \in knownUnavailableClusters[self]) /\ ~(x \in unavailableClusters))
IN
IF Len(cs) > 0 THEN
/\ uniqueId' = uniqueId + 1
/\ clusters' = [clusters EXCEPT ![cs[1]][msg.tenant][msg.queue] = Append(clusters[cs[1]][msg.tenant][msg.queue], [msg EXCEPT !.msgID = uniqueId, !.clusterId = cs[1]])]
/\ SendMsgOK' = [SendMsgOK EXCEPT ![sender] = Append(@, msg)]
/\ stats' = [stats EXCEPT !.sent = @ + 1, !.sentIds = @ \union {uniqueId}]
/\ UNCHANGED <<**unchanged_vars**>>
ELSE
/\ SendMsgError' = [SendMsgError EXCEPT ![sender] = Append(@, msg)]
/\ UNCHANGED <<**unchanged_vars**>>
Courier maps each tenant to a set of FoundationDB clusters and maintains a list of healthy clusters (via active and passive health checking). On every SendMessage request, Courier routes the message to an available cluster mapped to the tenant. The request fails only if all clusters mapped to the tenant are unavailable.
Modeling ReceiveMessage and DeleteMessage
Here is how we model the Broker processing a ReceiveMessage request:
ReceiveMsg(self, req, receiver) ==
LET cs == SelectSeq(tenantToCluster[self][req.tenant], LAMBDA x: ~(x \in knownUnavailableClusters[self]) /\ ~(x \in unavailableClusters) /\ Len(clusters[x][req.tenant][req.queue]) > 0 )
IN
IF Len(cs) = 0 THEN
/\ ReceiveMsgError' = [ReceiveMsgError EXCEPT ![receiver] = Append(@, req)]
/\ UNCHANGED <<**unchanged_vars**>>
ELSE
/\ clusterTime' = clusterTime + 1
/\ ReceiveMsgOK' = [ReceiveMsgOK EXCEPT ![receiver] = Append(@, req)]
/\ clusters' = [clusters EXCEPT ![cs[1]][req.tenant][req.queue] = UpdateSeq(clusters[cs[1]][req.tenant][req.queue], 1, uniqueId, cs[1], uniqueId, leaseRecords[self], clusterTime)]
/\ uniqueId' = uniqueId + Len(SelectSeq(clusters'[cs[1]][req.tenant][req.queue], LAMBDA x: x.receiveReqId = uniqueId))
/\ deadLetterQueue' = [deadLetterQueue EXCEPT ![cs[1]][req.tenant][req.queue] = @ \o SelectSeq(clusters[cs[1]][req.tenant][req.queue], LAMBDA x: ~(\E y \in 1..Len(clusters'[cs[1]][req.tenant][req.queue]): clusters'[cs[1]][req.tenant][req.queue][y].msgID = x.msgID))]
/\ ReceiveMsgResult' = [ReceiveMsgResult EXCEPT ![receiver] = Append(@, SelectSeq(clusters'[cs[1]][req.tenant][req.queue], LAMBDA x: x.receiveReqId = uniqueId))]
/\ UNCHANGED <<**unchanged_vars**>>
Under normal circumstances, messages are read and deleted by Receivers after processing or moved to dead letter queues. A deliveryCount variable (in another part of the code) tracks how many times a message was received and informs the service when to move it to a dead letter queue if a Receiver does not delete it. Once a message reaches a designated maximum delivery count, it is moved to the dead letter queue and will no longer be available to any Receivers. For the purposes of this model, we set the maximum delivery count to 2.
If the tenant has no available clusters or no active queues for the requested tenant-queue combination, the Broker returns an error for the request. Otherwise, the Broker checks if there are any available messages (messages that do not have an active lease and have not reached their delivery maximum), and returns such messages to the Receiver. The Broker also moves any messages that belong to the given tenant and queue and have reached their delivery maximum to the dead letter queue.
Here is the model code for a Broker processing a DeleteMessage request:
DeleteMsg(self, msg, receiver) ==
/\ IF ~(msg.clusterId \in unavailableClusters) /\ ~(msg.clusterId \in knownUnavailableClusters[self]) THEN
/\ clusters' = [clusters EXCEPT ![msg.clusterId][msg.tenant][msg.queue] = IF msg.leaseExpiration >= clusterTime THEN SelectSeq(clusters[msg.clusterId][msg.tenant][msg.queue], LAMBDA x: x.msgID /= msg.msgID) ELSE @]
/\ IF Len(clusters[msg.clusterId][msg.tenant][msg.queue]) > Len(clusters'[msg.clusterId][msg.tenant][msg.queue]) THEN
/\ DeleteMsgOK' = [DeleteMsgOK EXCEPT ![receiver] = Append(@, msg)]
/\ UNCHANGED <<**unchanged_vars**>>
ELSE
/\ DeleteMsgError' = [DeleteMsgError EXCEPT ![receiver] = Append(@, [msg EXCEPT !.error = "lease_expired"])]
/\ UNCHANGED <<**unchanged_vars**>>
ELSE
/\ DeleteMsgError' = [DeleteMsgError EXCEPT ![receiver] = Append(@, msg)]
/\ UNCHANGED <<**unchanged_vars**>>
If the message to be deleted is stored on an available cluster, and the message lease expiration time is greater than or equal to cluster time, the message is deleted from the queue. If the lease the Receiver submitted with the DeleteMessage request is expired (lease expiration < cluster time) or the cluster the message is on is not available, the Broker returns an error.
Specifying properties
As mentioned earlier in this blog post, we’re interested in verifying that Courier never loses a message. This means once a message is sent to Courier, it is either received by a receiver and deleted, or it is moved to the dead letter queue. Here’s how we specified this in TLA+:
NoLostMsgs == <>[](Cardinality(Sender!Messages) * Cardinality(Sender!ProcSet) = stats.deleted + stats.deadLetterQueue)
Results
Running the model described above through the TLC model checker passed.
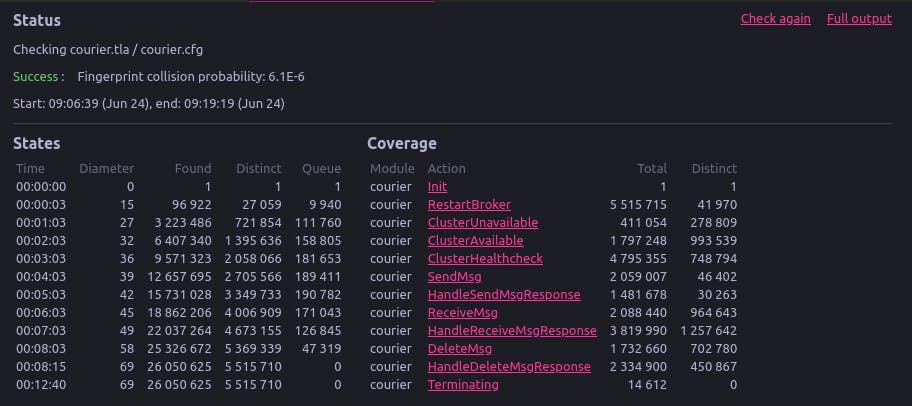
In this case, TLC scanned 5,515,710 distinct states and did not find any cases where our NoLostMsgs property was violated.
While the successful model checking result gave us more confidence in the design for Courier, we found the modeling process valuable in a couple of other ways as well:
- It provided us with a shared understanding of the system and a language through which we could communicate precisely about the system.
- It forced us to be more precise while implementing the system; we found several bugs by simply thinking through if our implementation was consistent with what was modeled. For example, we found a class of bugs related to FoundationDB’s optimistic concurrency control that we abstracted away in the model. (We solved these bugs by ensuring that our transactions were all idempotent).
Simulations
Formally modeling Courier allowed us to verify its correctness properties, but we found it insufficient to explain the performance characteristics of the systems. How much latency can we expect? How does throughput of the system vary under outages and overload?
We were specifically interested in how Courier would perform if it experienced an outage similar to Datadog’s March 8 incident. One of the lessons we learned from this incident pertains to quorum-based distribution systems, such as FoundationDB. These systems are available only if a quorum of nodes are alive; likewise, on recovery, a quorum of nodes must be alive before the system can serve even a single request.
We mentioned earlier that we chose to back Courier with multiple FoundationDB clusters for multi-tenancy, but another reason we made this decision was to hedge our bets in an outage scenario. Having multiple smaller FoundationDB clusters increases the likelihood that at least some quorums would survive if we had a loss in compute capacity. For example, if we only had one 100-node FoundationDB cluster and lost 51 nodes, then our service would be completely unavailable. But instead, if we had ten ten-node FoundationDB clusters and lost 51 nodes, up to eight clusters could survive, depending on where the node losses happened.
We implemented a discrete event simulation using SimPy to quantify more precisely how Courier behaves. In the simulation, we modeled Senders, Receivers, Brokers, and FoundationDB, and we measured throughput against node loss. We used benchmark data from FoundationDB to model CPU usage as well. We simulated two scenarios:
- Optimistic: Failed nodes are distributed across FoundationDB clusters, preserving as many functioning clusters as possible
- Pessimistic: Failed nodes are distributed in the way that results in the maximum number of failed clusters
The chart below shows how Courier behaves in both these scenarios, compared to both a single-cluster system and a hypothetical best-case system with linear degradation:
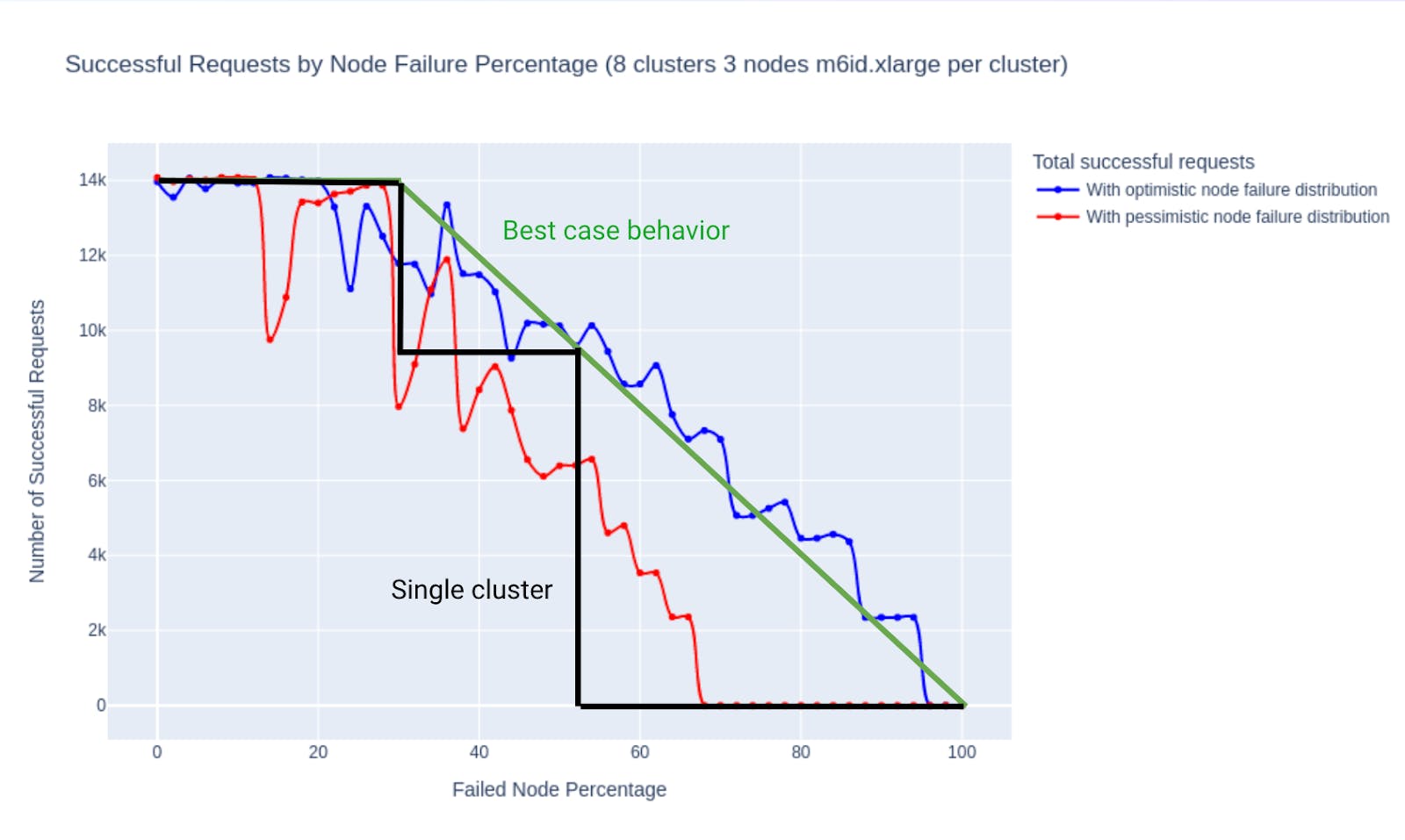
The chart shows that in the optimistic scenario, Courier’s throughput matches that of the best-case system, and in the pessimistic scenario, Courier still behaves better than a system with a single cluster.
At first, we did not understand the oscillations in throughput, but we found an explanation by examining the CPU usage data from our simulation:
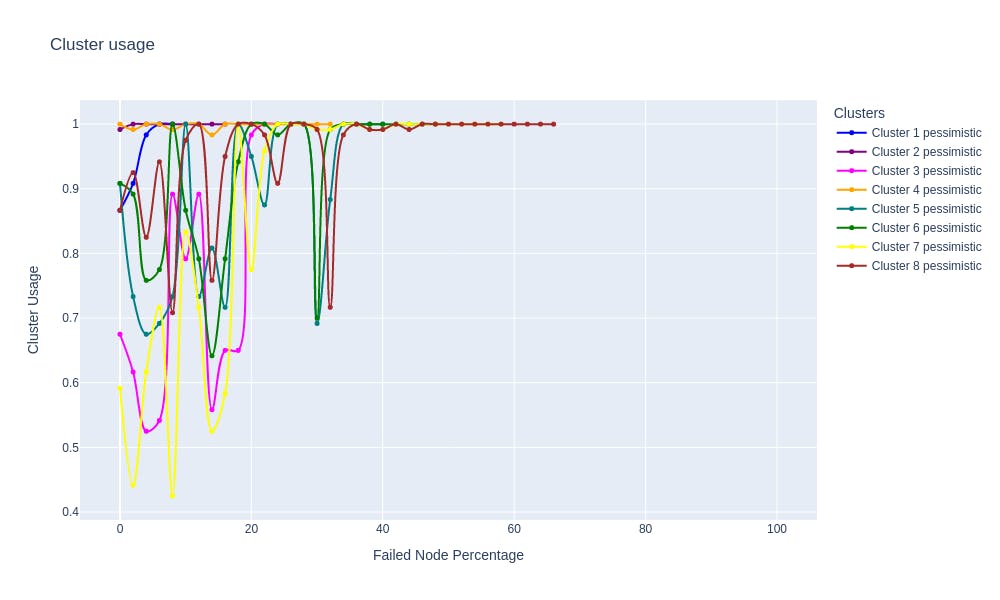
We observed that as a FoundationDB cluster loses nodes, its CPU usage increases, which reduces throughput—but when Courier’s health check detects that a cluster has failed, traffic moves to healthy FoundationDB clusters, causing throughput to recover until the healthy clusters lose nodes. This repeats for each FoundationDB cluster, causing oscillations. To work around this, we changed the inputs to the simulation so that each transaction required less processing power, thereby reducing the CPU load on the remaining nodes. This adjustment diminished the oscillations, as the system could handle the transactions more efficiently. We then re-ran the simulation.
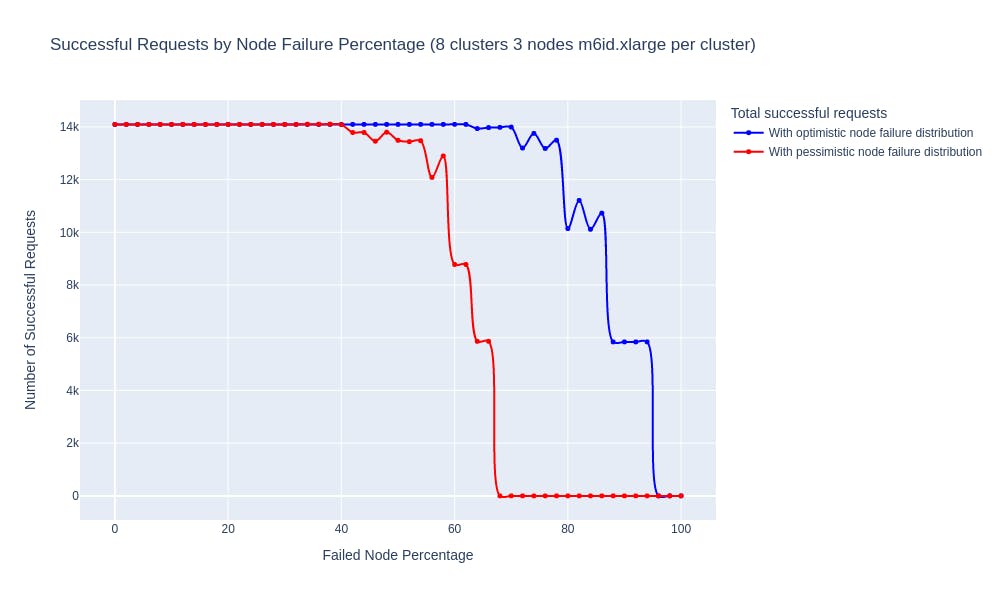
The chart above shows that oscillations in throughput are greatly diminished with this new configuration. This demonstrates how different configurations can yield significantly different results, underscoring the importance of testing various setups to understand their impact on system performance.
Closing the loop
After Courier was implemented, we performed a chaos test that recreated the pessimistic scenario described above. We deployed our actual implementation of Courier, along with four FoundationDB clusters, to a staging environment and used Datadog’s chaos controller to induce node loss on the FoundationDB clusters. The following chart shows the throughput of a single tenant in the system against node loss:
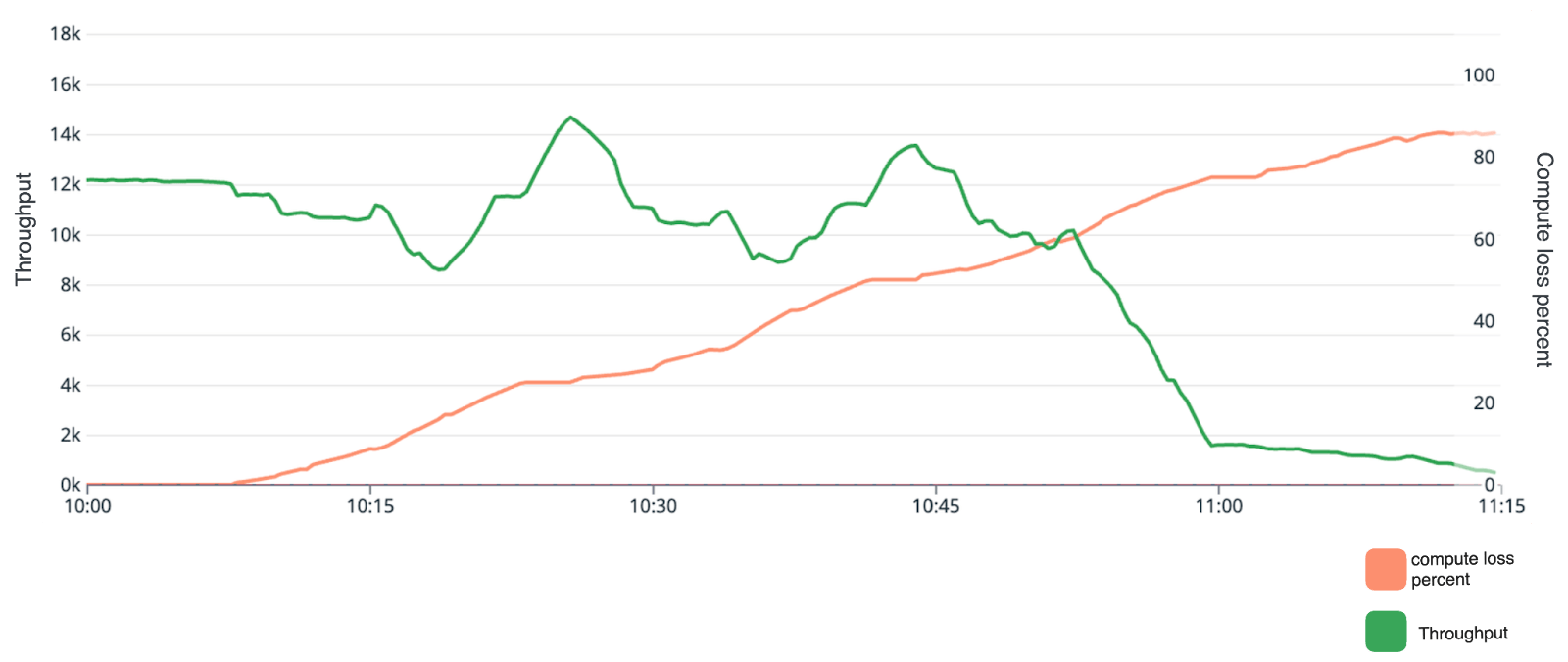
This is very similar to our findings from the simulations.
We found that the simulations were very useful for Courier when it came to determining how availability scaled with the number of replicas. Simulations gave us a much more descriptive picture of what a failure’s range of impact would look like in real life. They also surfaced potential cascading failures: each FoundationDB failure would result in a higher load on remaining clusters and further negatively impact availability. Additionally, after Courier was built, simulations made it easier for us to perform chaos tests, as we knew exactly what to test for and approximately what to expect.
Performance testing
Next, we moved onto performance testing our implementation. We created a very basic set up that had Sender, Receiver, and Broker nodes with a single FoundationDB cluster. We controlled throughput to Courier by varying the number of Sender and Receiver nodes, and we heavily overprovisioned the Brokers so we could understand FoundationDB’s performance characteristics more directly for our use cases. Unfortunately, we couldn’t get enough throughput out of FoundationDB for our implementation to be cost effective. We observed hotspots in CPU usage that cycled through different storage nodes in the FoundationDB cluster:
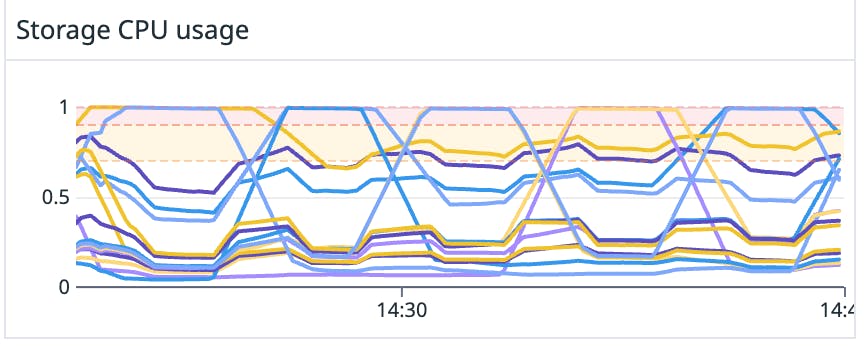
After some investigation, we understood that these hotspots were caused by Courier’s write pattern and how FoundationDB distributed keys across storage nodes.
FoundationDB employs range-based sharding, where data is sharded into contiguous key ranges, and each key range is assigned to one of the storage servers in the cluster. If one of the key ranges runs hot (that is, if it begins consuming high amounts of CPU), FoundationDB breaks that key range into multiple subranges and moves the subranges to different nodes. In Courier, we were using the message receipt timestamp in the keys used to store messages in queues. So the keys that represented the tail of the queue would always run hot, since that’s where all new messages were added. When FoundationDB split the key range, the tail of the queue moved to a different FoundationDB node, causing a CPU usage hotspot on that node. When the key range was split again, the tail simply moved to a different node, causing another hotspot.
To work around this, we added a shard number to the keys and wrote new messages with a randomly selected shard number. This allowed FoundationDB to partition the data in such a way that multiple storage servers can process incoming messages. Similarly, we deliver messages from a random shard number. The downside of this approach is that it made our queue completely unordered, making it very difficult to troubleshoot. With multiple FoundationDB clusters and multiple shard numbers within those clusters, it became difficult to provide even basic metrics like queue lag. And since we were delivering messages in random order, end-to-end tail latencies for message delivery were high.
One potential solution was to scan through all the shards on delivery and pick the oldest message. But this would not work well for highly concurrent or high-throughput queues, since it would cause too many conflicts with FoundationDB’s optimistic concurrency control.
Instead, we decided to add a sequencer process to Courier that orders messages for delivery. The sequencer runs periodically, scans all FoundationDB clusters for undelivered messages, and stores them in-memory in the order in which they should be delivered. When a ReceiveMessage request is received, Courier pops a message from the sequencer and delivers that message to the client. We brought back the Redis sequencer from our initial implementation, since Redis is efficient and well-suited for this role. The sequencer needs only to be fast and not durable, as we can rehydrate it from the FoundationDB clusters if necessary. The interactions between the processes now look like:
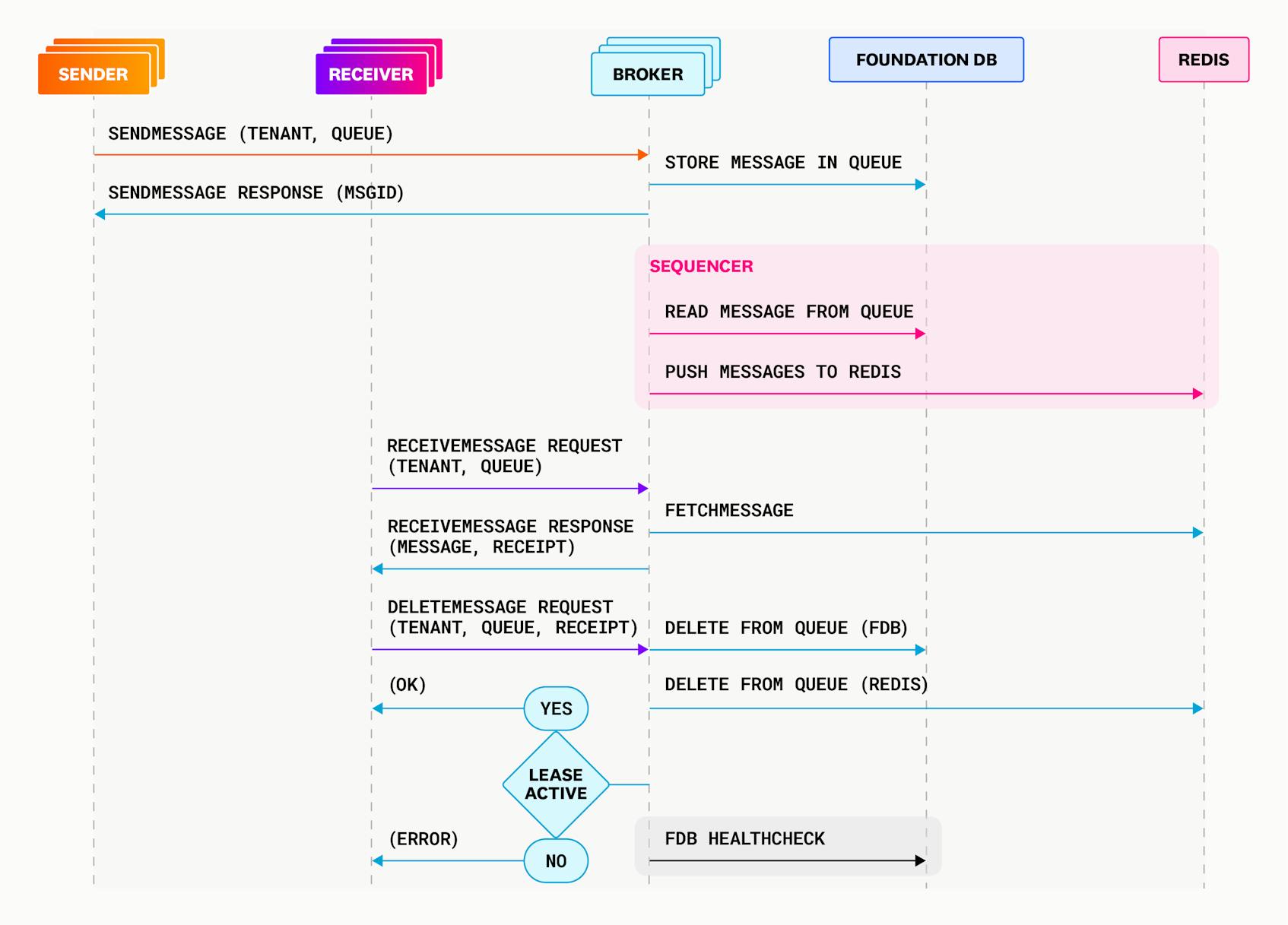
With these changes in, the performance of the system was adequate for our use cases. However, since we changed the design of the system, our TLA+ model was out of date.
Updating the TLA+ model
We updated the TLA+ model to include a sequencer:
Spec == Init /\ [][Next]_vars
/\ WF_vars(RestartBroker)
/\ WF_vars(ClusterUnavailable)
/\ WF_vars(ClusterAvailable)
/\ WF_vars(Terminating)
/\ \A s \in Sender!ProcSet : /\ WF_vars(SendMsg(s))
/\ WF_vars(HandleSendMsgResponse(s))
\* only one receiver must always proceed, the rest can fail and stop at any stage
/\ WF_vars(ReceiveMsg(1))
/\ WF_vars(HandleReceiveMsgResponse(1))
/\ WF_vars(DeleteMsg(1))
/\ WF_vars(HandleDeleteMsgResponse(1))
/\ \A b \in Broker!ProcSet : /\ WF_vars(ClusterHealthcheck(b))
/\ WF_vars(SequencerRoutine(b))When we re-ran model checking, TLC found a case where the NoLostMsg property failed. TLC outputs traces that show the exact sequence of operations that led to the failure:
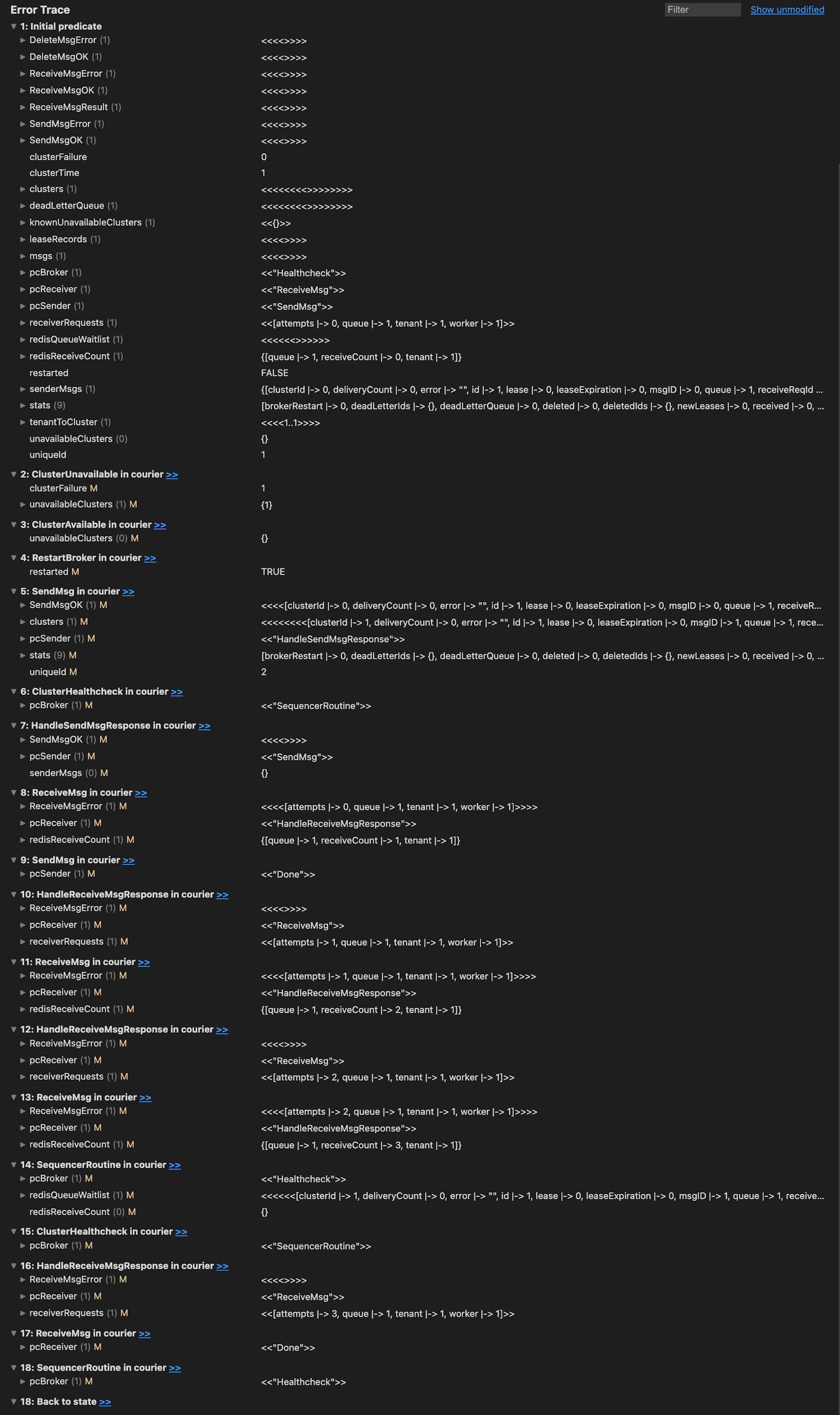
In the trace above, the ‘initial predicate’ step displays the initial state of all variables in the model, while subsequent steps show only variables that have changed since the previous step. Steps 2, 3, 6, 15, and 18 reflect the broker performing health checks, with step 4 indicating a broker restart. Although step 2 shows a health check failure, all other health checks appear to pass and don’t contribute to the model failure.
Step 5 and 7 are interesting—this is where a message is sent to the broker and it responds. Step 6 shows the sequencer routine running, but it does not load any messages since a receive message request has not been registered yet. This happens in Step 8, where the receiver is sending a receive message request and the variable redisReceiveCount gets updated. Since there are no messages in the sequencer at this point, an error is returned.
Steps 10, 11, and 12 show another receive message request starting and completing. In step 13, the broker responds to a new receive message request, and in step 14, the sequencer finally runs. In our model, a receiver only attempts three requests before terminating, which occurs in steps 16 and 17, where pcReceiver = "done" indicates termination.
ReceiveMsg(self) == /\ pcReceiver[self] = "ReceiveMsg"
/\ IF (Cardinality(senderMsgs) = 0 /\ QueueEmpty(clusters, receiverRequests[self].tenant, receiverRequests[self].queue) /\ Len(msgs[self]) = 0)
\/ receiverRequests[self].attempts = 3 THEN
/\ pcReceiver' = [pcReceiver EXCEPT ![self] = "Done"]Because the sequencer didn’t run within three receive attempts, the receiver was not able to receive the message. In theory, the sequencer is not guaranteed to run within any number of attempts of the receiver and can remain permanently out-of-date with what’s stored in FoundationDB.
But in practice, the sequencer is guaranteed to run at some point—we programmed it to run every three seconds and, if it became unavailable or slow, it would find the FoundationDB messages when it recovers. Therefore, our NoLostMsgs property should really be checking that messages fulfill one of three properties: persisted in FoundationDB, delivered and deleted, or moved to the dead letter queue. This tradeoff—where we rely on the periodic running of the sequencer instead of immediate processing and accept that there may be a period when messages are sent but not delivered—was one that we knew about and deemed adequate for our use cases. The availability of SendMessages is not impacted with this change. The model gave us an assurance that we didn’t introduce any other failure modes with this change.
Next Steps
As noted at the beginning of this blog post, formal modeling and lightweight simulations are powerful tools for verifying the design of distributed systems. However, they do not guarantee that the implementation fully aligns with the model and simulations, as subtle differences may exist. Determining whether an implementation sufficiently aligns with the models and simulations requires a deep understanding of both the model and simulations, as well as the implementation itself, and ultimately relies on human judgment. Following internal reviews, we partnered with Professor Nancy Day’s lab at the University of Waterloo to review our work and bring the latest advances in formal modeling into industry applications. This work is still ongoing.
Moreover, once a system is built and in production, we find it tedious to keep the models and simulations up-to-date. We may choose to update our models for large design changes (such as when we added a sequencer), but for routine feature work and bug fixes, we often take a more pragmatic approach and verify our changes through unit, integration, and chaos testing. Oftentimes, an update to our models may not even be required, since the model is a higher-level abstraction than our implementation.
A more recent technique, called deterministic simulations, popularized by FoundationDB, would allow us to perform similar tests as part of our CI/CD process, helping to verify every release. In deterministic simulations, an actual implementation of a system is executed in tightly controlled environments to verify the correctness of a system. Any non-deterministic inputs in the system such as time, random numbers, I/O operations, etc. are mocked so that any bugs found in the simulation can be reproduced along with the exact sequence of operations that led to the bug. Since time is itself mocked, a deterministic simulator can execute a system much faster than traditional unit and integration tests and can cover a large number of test cases. Failure injection is often combined with deterministic simulations.
Applying deterministic simulation techniques to Courier has been challenging. Courier is written in Go, and the Go runtime itself introduces non-determinism into our application: iteration over maps, scheduling of goroutines, and execution of select statements are all non-deterministic. Courier also comprises three different binaries: the brokers, Redis, and FoundationDB—which adds another layer of complexity. Recently Antithesis, a company founded by former FoundationDB engineers, introduced a generalized approach to deterministic testing through a custom-built deterministic hypervisor. This enables deterministic simulations in a language- and technology-agnostic way. While we weren’t able to use deterministic simulations for Courier, it remains an active area of research for us.
If you’re interested in working with us at Datadog, we’re hiring.
