
When managing queues and services in streaming data pipelines that use technologies like Kafka and RabbitMQ, SREs and application developers often struggle to determine if these pipelines are performing as expected. Visibility into the performance of a streaming data pipeline, after all, requires visibility into every component of that pipeline. Any issue at any step—whether it originates from a producer or consumer, a hot shard in a queue, or the underlying infrastructure—can cause data and events to be delayed, which increases latency and lag. Meanwhile, the fragmented ownership of these components adds more complexity to already complex systems. The pressure generated by bottlenecks can overwhelm downstream services or queues owned by different product or platform teams, who may be unaware of regressions further up the pipeline. This lack of visibility can lead to prolonged downtime, data loss, and diminished application performance, which can ultimately result in broken SLAs and a degraded customer experience.
Datadog Data Streams Monitoring (DSM) helps you easily track and improve the performance of streaming data pipelines and event-driven applications that use Kafka and RabbitMQ by mapping and monitoring services and queues across your pipeline end to end, all in one place. The deep visibility provided by DSM enables you to monitor latency between any two points within a pipeline; pinpoint faulty producers, consumers, or queues driving latency and lag; discover hard-to-debug pipeline issues such as blocked messages or offline consumers; root-cause and remediate bottlenecks so that you can avoid critical downtime; and quickly see who owns a pipeline component for immediate resolution.
DSM automatically maps the architecture of your entire streaming data pipeline, including visualization of interdependencies, service ownership, and key health metrics across the services and infrastructure your pipeline depends on.
In this post, we’ll show you how you can use DSM to:
- Monitor and alert on end-to-end latency
- Pinpoint the root causes of bottlenecks in pipelines
- Identify and remediate floods of backed-up messages
- Enhance existing troubleshooting workflows
Monitor and alert on end-to-end latency
The DSM map shows you, at a glance, the topology of your streaming data pipelines or event-driven applications. DSM visualizes dependencies between services, the queues they communicate with, and the clusters they are part of—all in one place—so you can easily track the flow of data in real time and collaborate more efficiently between service owners. Additionally, DSM provides end-to-end latency, throughput, and consumer lag metrics out of the box, eliminating the manual work involved in monitoring your streaming data pipelines by using logs and custom metrics. This detailed visibility helps you understand why messages have been delayed, which is helpful for adhering to SLAs relating to latency and performance.
For example, say you are an engineer on a trading platform that facilitates stock transactions. You own the balance-checker service that reads funds in customer accounts, which runs on a Kafka pipeline. Within the pipeline, balance-checker runs between trade-server and trade-executor, a fact that requires the processing latency for your service to stay extremely low. This is because, according to your platform’s SLA with its customers, the time elapsed between the trade-server and trade-executor services—that is, the time between when a customer inputs their trade and when the customer’s trade is fully executed—is expected to complete within in 1 second or less. If any of these services have an increase in latency, therefore, they may be causing the pipeline to violate the SLA.
You click on the balance-checker service in the DSM map to open up the side panel and navigate to the Pathways tab. This view allows you to see the time it takes for a message to make its way from the balance-checker service to the queue for processing. You want to ensure that latency on balance-checker never exceeds 0.5 seconds, because you’ve determined that latency any higher than 0.5 seconds risks exceeding the SLA for total transaction time and is thus unacceptable.

You can also click the New Monitor button to set up an alert on this pathway to notify you whenever latency to this service is more than 0.5 seconds behind. This will enable you to stay ahead of issues and troubleshoot before they become widespread.
Pinpoint the root causes of bottlenecks in pipelines
In addition to helping you monitor latency on the services you own, DSM provides a source of shared knowledge for disparate teams to better visualize services within streaming data pipelines as a whole, and work together to spot and remediate bottlenecks. The DSM map helps you visually identify latency spikes from upstream teams or unhealthy consumers experiencing sudden changes in throughput. This visibility—in tandem with Datadog metrics from the Kafka and RabbitMQ integrations, your services’ infrastructure, and connected telemetry from across the stack—can help you build plans of action to prevent bottlenecks, which can cause increased latency, cascading failures in downstream services, and negative effects on end-user experience.
Let’s take a look at another example. Say you’re an SRE on a platform team responsible for maintaining and provisioning infrastructure that powers Kafka clusters. You need to ensure that when application teams send data through hosts running Kafka, the hosts are running as expected so that the data passes through the pipelines reliably. You receive a page alerting you of a spike in consumer lag. You then navigate to DSM, which allows you to filter by cluster from the left-hand side panel. This in turn enables you to view the services that are sending data through the Kafka topics that are running on the cluster you were alerted to. You can click on the service that is indicating abnormal lag patterns to bring up a side panel that displays this information in the Incoming Messages by Producing Service timeseries.

You can see that there is a spike in throughput between 11:30 and 11:45—the time you got paged due to an unhealthy broker. Below the timeseries graph, in the Related Services section, you see the breakdown of throughput by upstream producing and downstream consuming service. You see that the majority of this spike is coming from the Data Science team, so you reach out to them to find out why they were sending more data than expected through these hosts. This way, you as an SRE can predict and plan for these events in the future—for example, by scaling up your cluster or increasing the maximum message size.
Identify and remediate floods of backed-up messages
The DSM Overview tab provides a prioritized view of your system that immediately brings your attention to bottlenecks. This view is broken down into three different logical entities—service, queue, and cluster—so you can quickly see the services with the highest lag, the longest queues, and the clusters with the most queues.
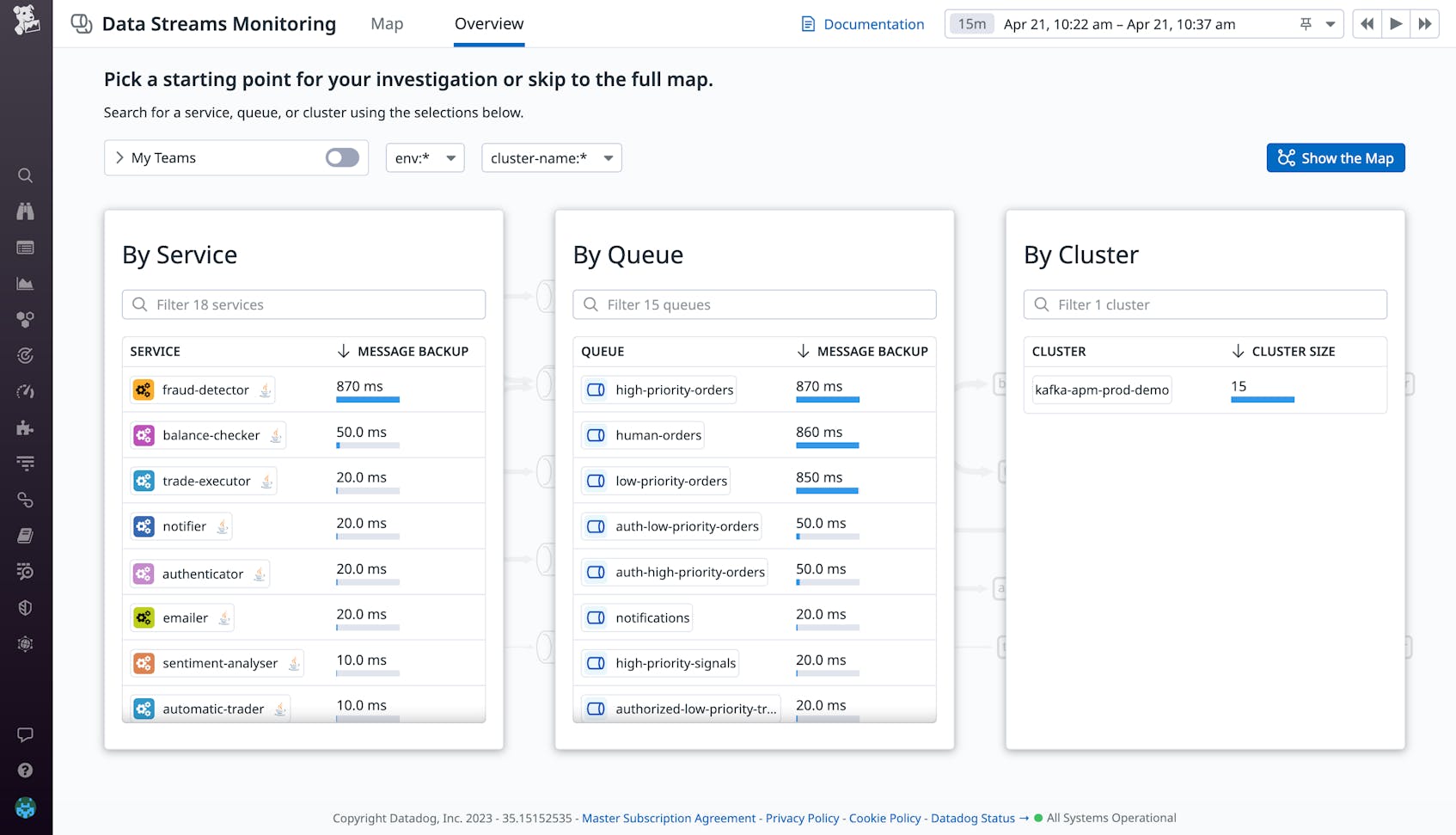
For instance, say you are a software engineer looking for ways to improve performance on an e-commerce site. Because your application is complex and your DSM map is large, you open the DSM Overview tab to see if it can provide you with a jumping-off point for your investigation. At the top of the list of backed-up services, you see the fraud-detector service with 870 milliseconds of consumer lag, which you decide to look into.
When you click on the fraud-detector service, DSM automatically jumps to the map and opens the service side panel, breaking down the details so you can see end-to-end latency of pathways, throughput metrics, processing latency, infrastructure metrics, and more. At the top of the side panel, you can see exactly which Kafka topics and partitions are causing high lag in the consumer service. In the Throughput tab, you see there’s a spike in latency in the timeframe 1:30-1:45 a.m. You bring this information to the team that owns the fraud-detector service (which you can see listed right in the side panel) and find out that they deployed a new update to the service at 1:30 a.m., which they hypothesize to be at the root cause of the slowdown. They roll back the deployment to alleviate the latency while they investigate further.
Enhance existing troubleshooting workflows
When troubleshooting, the out-of-the-box metrics offered by DSM are complemented by Datadog’s Service Catalog, alerting, distributed tracing, out-of-the-box integration dashboards, and more. It’s easy to pivot from localized bottlenecks found in the DSM views to individual traces, logs, or infrastructure metrics that further explain where and why messages have been delayed, providing additional context to help you remediate the issue.
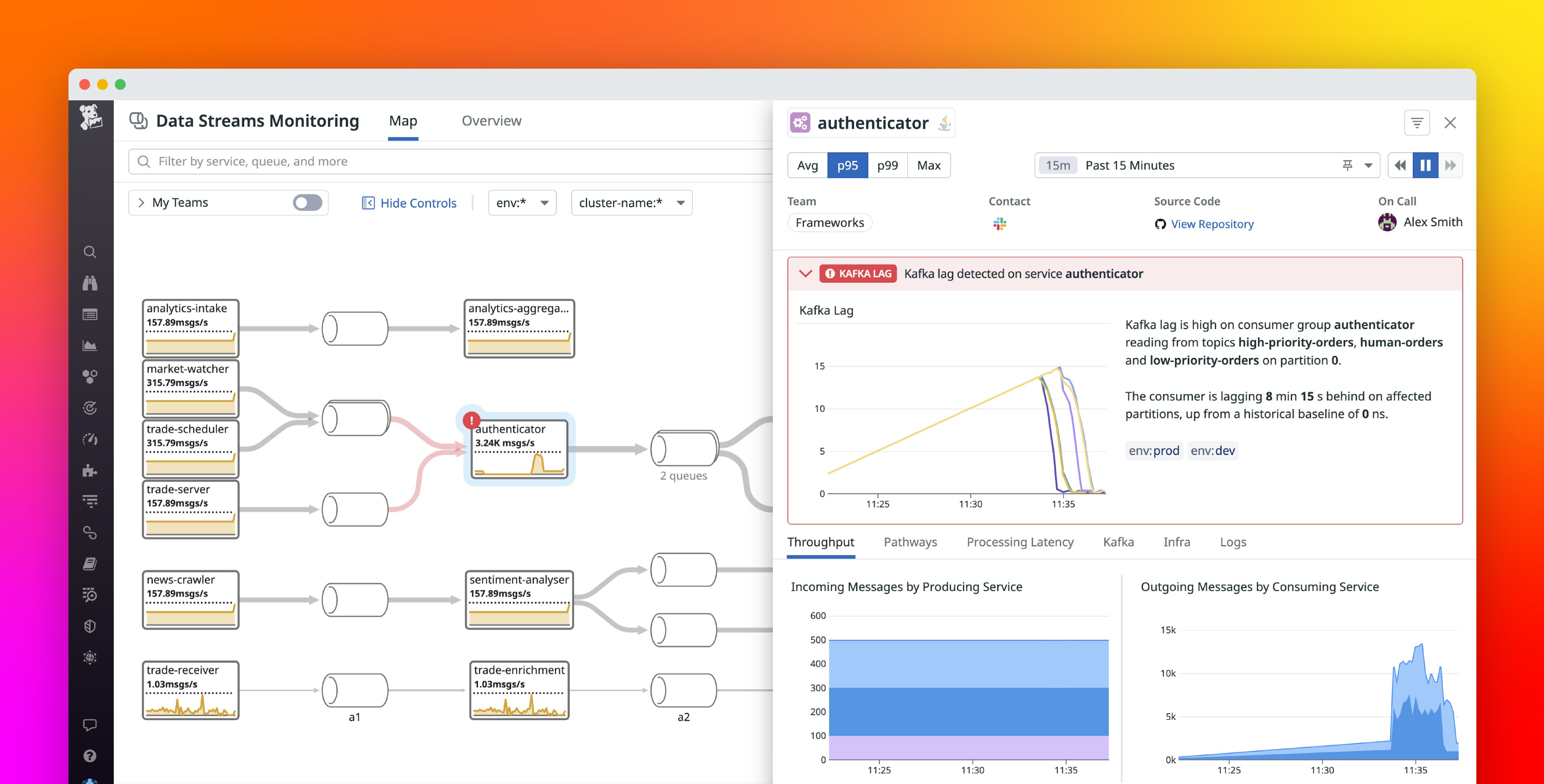
For example, say you’re an application developer on an e-commerce site, and you receive an alert on the authenticator service, which you suspect is the reason end-to-end latency is elevated in your Kafka pipeline. You may want to understand which events are delayed the most and the root cause
From the DSM map, you click on the service and switch to the Processing Latency tab, which joins APM and DSM data to allow you to find specific traces that are taking the longest to be processed, helping you troubleshoot.

You see the spike in latency between 10:35 and 10:40. Below the breakdown, you can see individual events that took the longest to be processed within the authenticator service. Each event is linked to a trace, which you can click through to see.
Upon investigating the authenticator span list, you find that one particular action—Produce Topic auth-high-priority-orders—is taking an especially long time. With this knowledge in hand, you can debug the part of the service’s code responsible for the slowdown. Troubleshooting the issue with DSM helps you get to the root cause much easier and faster than before. Moreover, you can use Datadog’s source code integration to debug the code in the same platform.
Monitor your data streaming pipelines with Datadog DSM
DSM automatically maps the topology of your entire event-driven application, simplifying an often complex web of queues and microservice interdependencies—especially at scale—to provide you with a clear, holistic view of the flow of data across your system. This deep visibility makes it easier to detect message delays, pinpoint the root cause of bottlenecks, and spot floods of backed-up messages—enabling you to avoid critical downtime.
If you’re new to Datadog, sign up for a 14-day free trial and see firsthand how you can take advantage of the DSM today.
