A guide to Log Management Indexing Strategies with Datadog
October 9, 2024
The following guide was written with Datadog customers in mind, but a majority of the prevailing guidance can be applied beyond Datadog.
The applicable points to any log management solution and strategy are:
- When you have a billion of the same log, you don’t need to keep every single one (e.g. sampling)
- Not all logs are created equal (e.g. don’t store/index your debug logs)
- Some logs shouldn’t be logs (e.g. low information density with low cardinality that tracks change over time should be log-to-metrics instead)
- “Don’t chase the tail” — apply the 80/20 rule to your optimizations and configurations (e.g. don’t chase < 1% volumes with index optimizations).
The intent of this document is to provide Datadog customers with an as prescriptive as possible recommendation to provide flexibility and balance between central governance, budget control, and autonomy for individual teams. This is based on our observations and discussions with Datadog Log Management customers at scale who have optimized their usage and administration of Datadog Log Management, what has worked best for them, and our own internal (DD) experiences (both at Datadog and prior experience in other companies and roles).
There is no one size fits all strategy, and we’ve worked with many customers who continue to tweak their strategies over time as unknowns are uncovered, new teams, technologies, sources, etc are onboarded, and as their Datadog/Observability experience increases. We aim to set customers up for success and help avoid any non-optimal configurations early on.
Common Successful Indexing & Config Strategies
These strategies are derived from customers at scale who use Datadog Log Management in an optimized way.
Log Indexes provide fine-grained control over your Log Management budget by allowing you to segment data into value groups for differing retention, quotas, usage monitoring, and billing. By default your account starts with a single catch-all index of all your logs, but in almost all cases you will want to define different retention strategies for different kinds of logs, as well as manage varying quotas and costs for those different sources.
Indexes are defined by a filter, which is the same search syntax as a logs query. Any logs that match the filter will go into that index. Indexes can be ordered, and log events can only match one index and go into the first index they match. Indexes can also contain exclusion filters which can be used to gain finer grain control over which logs are retained via sampling. By default indexes have zero exclusion filters, so all logs that match are retained for the indexes retention period.
Below we present two common successful patterns we see amongst our customers. Both are valid depending on a company’s needs. Both can be implemented together as well, though some minor manipulations for index filters will be required.
Consider using Flex Logs when you have high-volume (10B or more events per month) long-term retention (30 days or longer) needs and where unlimited query capacity is not a concern. Standard Indexing is more suitable when you need logs to troubleshoot live operations. For example, if you have to use production application logs to troubleshoot a sudden spike in the number of users and queries, like during a SEV-2 or higher-severity incident or outage. Flex logs is a cost-effective storage and query tier for certain categories of logs (but not limited to those). See the Flex Logs blog for more information on how to think about different kinds of logs in terms of retention periods and querying frequency.
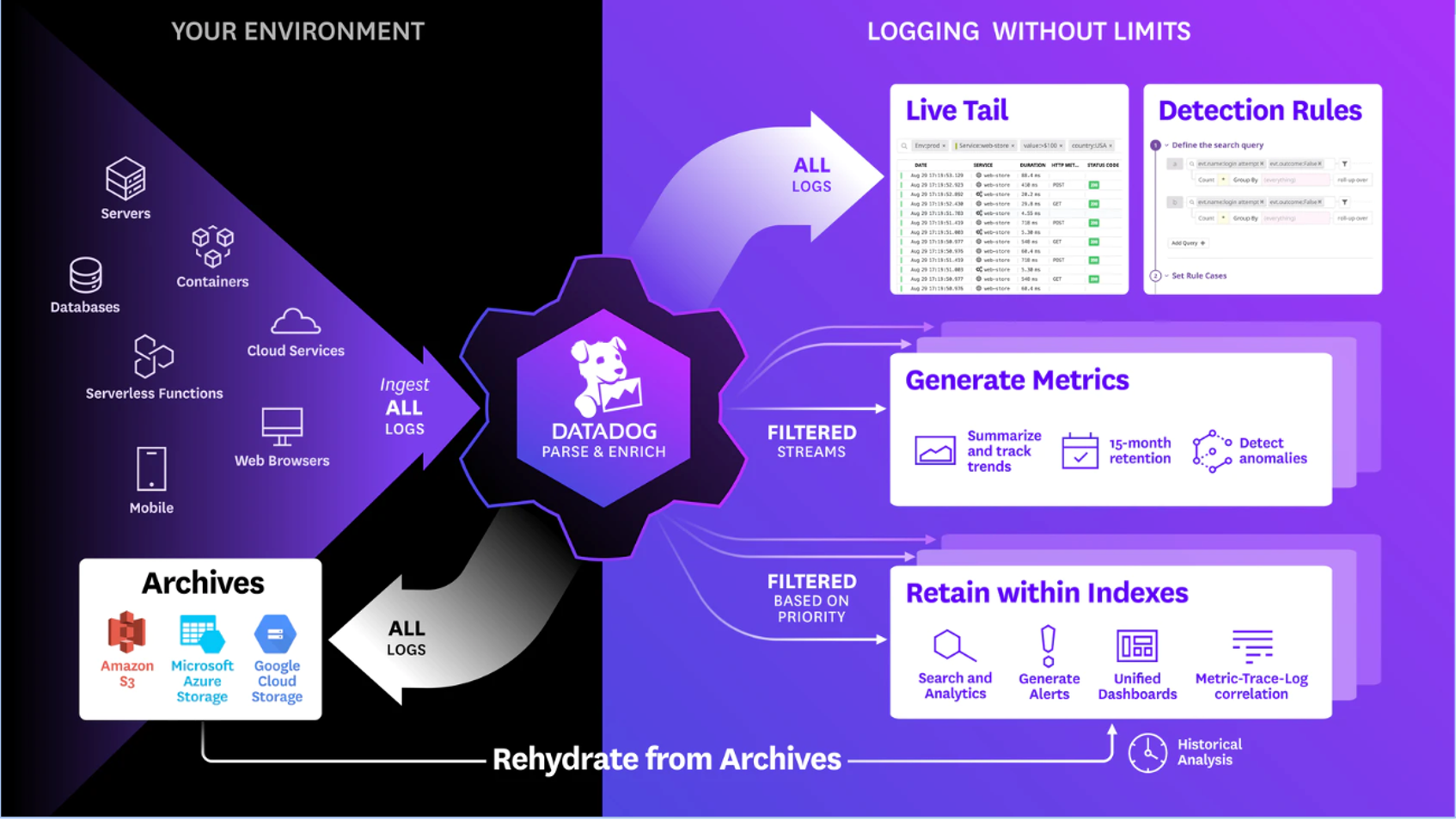
For all configurations where we suggest exclusions / sampling, Datadog’s Live Tail will allow users to view logs in real time regardless if they are excluded or indexed but after they’ve been processed by the on-stream ingest pipeline.
Focus on subsets with a majority of logs
We suggest applying the 80/20 rule, and tackling the buckets that make up the vast majority of indexed logs. We often see customers “chasing the tail” and optimizing for buckets that make up less than 1% of their total volume.
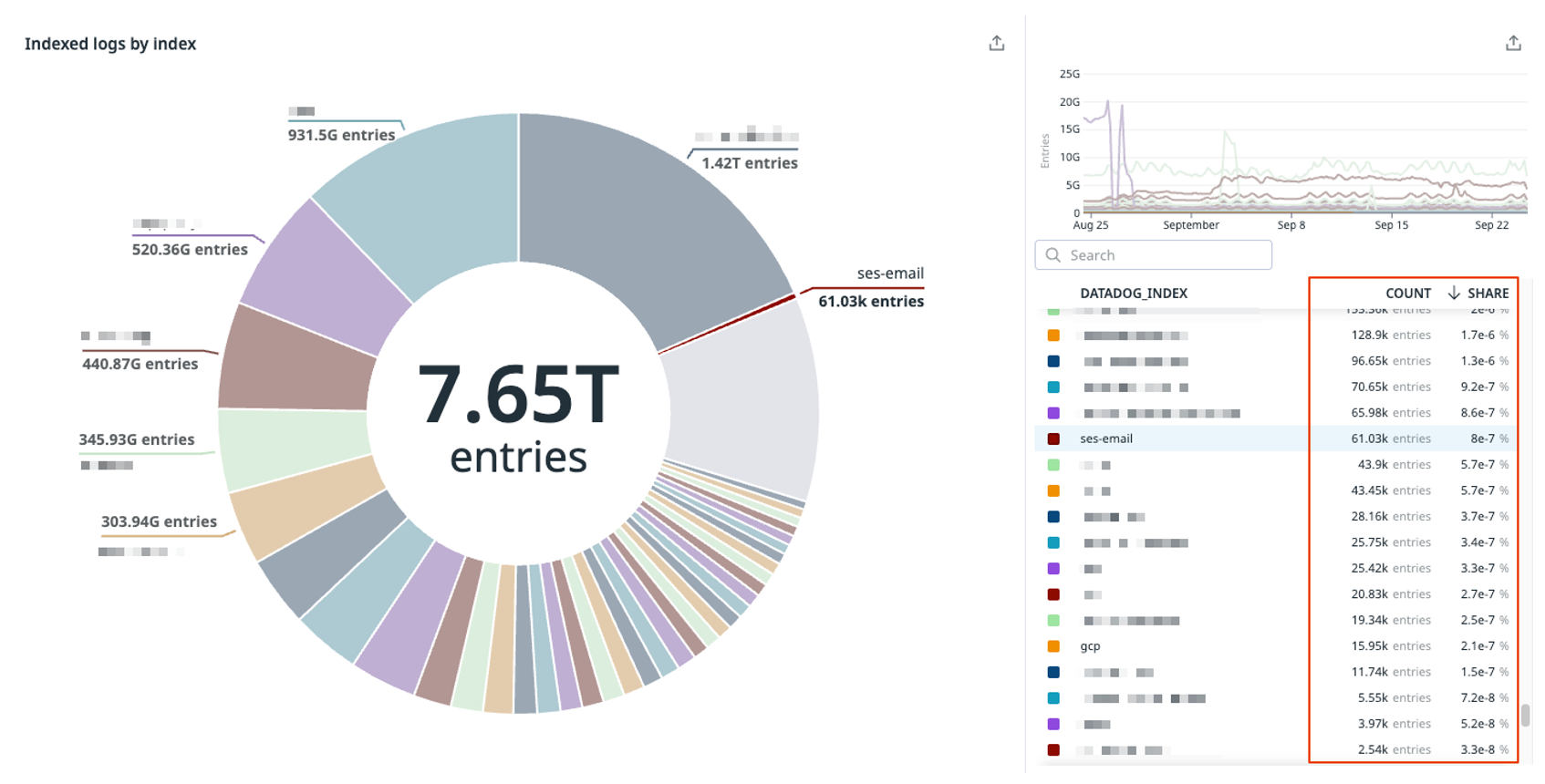
Take the following screenshot for example, here we can see an anonymized chart from a customer’s indexing strategy where they are “chasing the tail” with volumes well below 1% of total volume (see bottom right side, where each row is an index and its contribution to overall volume).
The list at the bottom right side of the screenshot shows:
- Each row as an index
- The number of events in that index in the count column
- The volume as a percentage of the total volume in the share column.
This showcases a poor indexing strategy where the customer has created indexes that are well below 1% of total volumes. There will be little ROI in trying to find optimizations here. Start with the largest percentage subset of logs first, these may be your highest traffic services, or your noisiest technologies (for example,. CDN, network, DNS, and audit logs) that produce your highest volumes. Often within these larger subsets, you can find many exclusion, sampling, and logs-to-metric opportunities.
Strategy: Company / Org wide without Flex
This indexing strategy is to broadly define your indexes based on retention and segmentation rules to support your use cases. This is a good tactic for companies that have a centralized observability team and strategy (or a mature observability/logging culture) that is less concerned with volume/cost control at the business-unit/product/team/service level. This tends to be a good starting point for most adopters of Datadog log management as the administrative overhead is low and it offers broad control over all logs, but does not preclude it as a long term strategy.
Define indexes based on retention buckets and any segmentation rules to support use cases, e.g.:
7 day standard indexing production critical/error/warning logs
- Errors / Warnings across all app and vended logs (e.g. CSP managed services, i.e AWS ALB logs)
- Apply intelligent sampling to certain apps as needed
- Extract logs to metrics for critical services to identify trends over 15mo
3 day standard indexing production info++ logs
- All info logs regardless of source
- Sample, 30–75%, per source as needed
- Exclude 90%+ for any low information density logs, e.g. application health check
- If necessary, extract via logs to metrics for alerting
- In some cases exclude 100% at customer discretion
- Route to archives
- Extract logs to metrics for critical services from info logs
3 day standard indexing for all status of non-production logs
- Sample, 30–75%, per source as needed + route to archives
- Exclude all debug logs
- Optionally route to archives depending on use cases
- Exclude 90%+ for any low information density logs, e.g. application health check
- Extract logs to metrics for critical services to identify trends over 15mo
Debug logs
- We generally don’t see customers store their debug logs as they tend to be very noisy and not very useful beyond the application development process, rather they encourage developers to use Live Tail to view any debug logs regardless of environment, but there may be use cases. However every company, organization, and team is different and uses logs in different ways, so this may be applicable.
In some cases, at customer discretion to meet their needs and use cases, they may want to extend or reduce the retention period for error/warning logs to either 15 days or 3 days respectively.
Strategy: Company / Org wide with Flex
If you decide to include Flex Logs as part of your strategy then you have the option to shift high volume, low information density logs, such as network flow logs, directly into the Flex Logs tier, skipping standard indexing altogether saving yourself the cost associated with “hot ” storage and query. You can do this by creating an index that does not include the standard tier and goes directly to the flex tier. Please note that for logs used for real-time monitoring and troubleshooting, e.g. application logs, that you might use during an incident or outage, should not be sent directly to the Flex tier. Read our blog post on Flex Logs to learn more.
Note: logs used for real-time monitoring and troubleshooting, e.g. application logs that you might use during an incident or outage, should not be sent directly to the Flex tier. Read our blog post on Flex Logs to learn more.
What we’ve seen most customers adopt is a 10 to 30% (of total volume) standard indexing rate for production application logs, in some cases only error logs, into the standard tier, extended into Flex for 30 days, and then all other log volumes going directly into the Flex tier. This is generally for very high volume accounts and makes the financial feasibility of keeping high volume logs feasible.
Define indexes based on retention buckets and any segmentation rules to support use cases, e.g.:
3 day standard indexing production critical/error/warning logs
- Errors / Warnings across all app and vended logs (e.g. CSP managed services, i.e AWS ALB logs)
- Apply intelligent sampling to certain apps as needed — If also trace correlation needed, sample with trace_id
- Extract logs to metrics for critical services to identify trends over 15mo
- Optionally extended these logs for 30+ days by adding Flex Logs to the index
[Optional] 3 day standard index for critical production info++ logs
- Info logs you would use in a live operations situation (e.g. incident or outage) or for alerting
- Apply intelligent sampling to certain categories as needed
- Extract logs to metrics for critical services to identify trends over 15mo
- Optionally extended these logs for 30+ days by adding Flex Logs to the index
30+ day Flex Logs non-critical production info++ logs
- All info logs regardless of source
- Sample, 30–75%, per source as needed
- Exclude 90%+ for any low information density logs, e.g. application health check
- If necessary, extract via logs to metrics for alerting
- In some cases exclude 100% at customer discretion
- Route to archives
- Extract logs to metrics for critical services from info logs
30+ day Flex Logs for all status of non-production logs
- Sample, 30–75%, per source as needed + route to archives
- Exclude all debug logs
- Optionally route to archives depending on use cases
- Exclude 90%+ for any low information density logs, e.g. application health check
- Extract logs to metrics for critical services to identify trends over 15mo
Debug logs
- We generally don’t see customers store their debug logs as they tend to be very noisy and not very useful beyond the application development process, rather they encourage developers to use Live Tail to view any debug logs regardless of environment. However every company, organization, and team is different and uses logs in different ways, so there may be cases where you want to index them, but their value is very point in time so we wouldn’t suggest keeping them longer than 3 days if at all.
Unit Focused
For companies concerned with per unit (a unit being an organization, business unit, product, team, etc) retention, cost, exclusion, etc controls they tend to implement this or similar configurations. This strategy tends to work best for smaller companies, but we do see larger organizations adopt it as well. We suggest picking high-level units, such as BU or product, not service or source, as this can lead to 1000s of indexes which can be cumbersome to maintain and often leads to suboptimal index usage (e.g. < 1% of total volumes).
It should be noted that these configurations tend to require more administrative overhead and more planning. Datadog encourages customers to keep their index count as low as possible to avoid a frustrating and overly complex user/administrative experience. Datadog offers 100 indexes out of the box, our recommendation is to keep your unit count below this threshold if possible.
If you decide to include Flex Logs as part of your strategy then you have the option to shift high volume, low information density logs, such as network flow logs, directly into the Flex Logs tier, skipping standard indexing altogether saving yourself the cost associated with “hot ” storage and query. You can do this by creating an index that does not include the standard tier and goes directly to the flex tier.
Note: Logs used for real-time monitoring and troubleshooting, e.g. application logs that you might use during an incident or outage, should not be sent directly to the Flex tier. Read our blog post on Flex Logs to learn more.
Without Flex Logs
For each unit, create 3 indexes - one per environment tier per unit split by category of log, e.g.:
7 day standard index: Unit X - Production Errors
- Critical + Errors + Warnings
- Extract logs to metrics for critical services from info logs
- Sample as needed (5-25%)
3 day standard index: Unit X - Production Info
- Info (sampling rate 20-50%)
- Extract logs to metrics for critical services from info logs
3 day standard index: Unit X - Non-prod
- All logs from non-production environments
- Heavily sample info logs (50-80%)
… N indexes (x3 numbers of units)
Exclude all Debug logs, route to archive, and use Live Tail.
In some cases, at customer discretion to meet their needs and use cases, they may want to extend or reduce the retention period for error/warning logs to either 15 days or 3 days respectively.
With Flex Logs
For each unit, create 3 indexes (and one optional) - one per environment tier per unit split by category of log, e.g.:
3 day standard index: Unit X - Production Errors
- Critical + Errors + Warnings
- Extract logs to metrics for critical services from info logs
- Optionally extended these logs for 30+ days by adding Flex Logs to the index
- Sample as needed (5-25%)
[Optional] 3 day standard index for critical production info logs
- Info logs you would use in a live operations situation (e.g. incident or outage) or for alerting
- Sample as needed (5-25%)
- Optionally extended these logs for 30+ days by adding Flex Logs to the index
30+ day Flex Logs: Unit X - Production Info
- Info (sampling rate 20-50%)
- Extract logs to metrics for critical services from info logs
30+ day Flex Logs: Unit X - Non-prod
- All logs from non-production environments
- Heavily sample info logs (50-80%)
… N indexes (x3 numbers of units)
Exclude all Debug logs, route to archive, and use Live Tail.
Catch-all Index
In each of the above cases, it is often prudent to define a catch-all index (the same as the initial index Datadog provides). This index remains at the bottom of your index order, and will capture any logs that don’t meet the filter criteria of a higher index. This is often useful as new environments, teams, applications, sources, etc are sent to Datadog that can be considered “unknowns” – in this way you can monitor the index and adjust your higher level index strategy accordingly. This index can have a lower quota to avoid suffering from accidental spikes, and you can set up additional monitors and alerts to notify you when this index goes above a certain customer defined threshold.
Infrequent Access + Long Term Retention
For any use cases (compliance, audit, regulatory, security, or other internal needs) that require long term retention and immediate searchability (not rehydration), we recommend enabling Flex Logs on any given index. Flex can be added to an index at any time, and from the point it is configured log events that surpass the standard retention period will move to the Flex Logs retention tier. Flex Logs is available in 30 day increments.
Do note that this is a slower access tier, so it will not be as fast as standard indexing queries. For this reason we do not offer log alerting via monitors on this tier. There are compute options available from extra small to large to accommodate companies with different log volumes and concurrent query usage. We’re happy to talk to you about proper sizing based on your use cases and needs.
Rather than enabling Flex Logs on every single index (though that is certainly an option and choice customers can make), Datadog recommends creating custom one-off indexes for teams that really need longer retention and ONLY enabling Flex Logs with 30 days+ on those specific indexes. For example, let’s say Team Security says “I need retention for Cloudtrail logs for 90 days”, then create a special index with query criteria source:cloudtrail and enable Flex Logs only on that index.
If an index already contains a specific log source (as defined by an index filter) there are some options for how to configure Flex Logs. Simply enable Flex Logs for that index and choose a retention period. Or if you prefer to not keep those logs in the standard tier at all, add a new filter to your index to exclude those specific log events (e.g. -service:myapp) then setup a new index with the opposite filter (e.g. service:myapp) and choose only Flex Logs without standard indexing.
Archiving Strategy
Archives are cloud provider storage buckets that a customer owns, that Datadog forwards logs to, after the log event has gone through the Datadog log ingest pipeline. Archives work whether you’ve chosen to index your log event or not (so if you exclude a log from indexing, it can still be routed to an archive). This allows for retaining logs for longer periods of time (defined by you) and meeting compliance requirements while also keeping auditability for ad-hoc investigations, with Rehydration at commodity storage prices.
Generally Datadog advises to break your archive into high level conceptual units, e.g. environment: production, quality-assurance, test, dev, etc, and include DD tags in the archive for scoped rehydrations. Similar to the unit based indexing strategy, the overhead of managings 10s of archives versus 100s is more successful at scale. The unit can also be organization/team based, but adding more dimensions leads to higher cardinality, and by using DD tags in the archive you can scope easily so it becomes unnecessary to split archives by such minutia.
For each singular unit, create an archive — one per environment tier, e.g.:
- Production
- QA
- Test
- Dev
Alternatively, for each customer defined unit (org, BU, product, team, etc), create two archives — one per environment tier per unit, e.g.:
- Unit X — Production
- Unit X — Non-prod
Two alternative strategies we see often are:
- Splitting by env tier + status is one we also see often, but does lead to a much higher number of archives to manage
- Splitting by unit only, this can lead to rehydration mistakes more easily, as rehydration queries need to be more tightly defined
Other Archive Settings
For each archive, make sure to set a Max Scan Size to prevent accidentally large rehydrations.
Be sure, if your filter is broad, that you include DD tags so that when you rehydrate you can more easily target a lower number of events resulting in a faster and optimized rehydration.
General Governance
- Create monitors that alert on estimated usage metrics broken down by service, source, or any other dimension to get notified if you have ingestion spikes that are unexpected.
- For each index, make sure to set up a Daily Quota + Warning Threshold to get notified on spikes.
- Restrict the Modify Index permission to only “unit leads” or central admins.
- If you need to scrub sensitive data in logs before they are indexed (stored), review Datadog’s Sensitive Data Scanner documentation.
- Review the Logs Role Based Access Control (RBAC) guide for how to structure your various roles, restrict access to certain logs (Logs Restriction Queries), or restrict access to certain log configuration assets (e.g. indexes, pipelines, archives, etc).
- Use Audit Trail to build a monitor and get notified if anyone changes Index retention or Exclusion Filter values.
Managing Cost
- Setup anomaly monitors against estimated usage metrics
- Determine other metrics and dimensions in the estimated usage dashboard that are important to you and setup monitors for them
- Threshold alerts on log ingest/index spikes by dimensions you care about
- Set quotas per index and alert when nearing the quota or when it has been reached
- Any logs beyond the quota will still work with archives and log-to-metrics
- Exclude unuseful / low information density logs that either A. are just noise, or B. could be a log-to-metric
- Use log patterns within Datadog to help find these kinds of logs
- Convert logs-to-metrics for high level analysis over 15 months for logs that don’t carry high cardinality metadata and that aren’t a fit for any logs use cases
- E.g. HTTP status code logs that don’t provide additional information
- For high volume plus long term retention needs, talk with Datadog regarding Flex Logs
- Fixed cost for compute capacity
- $0.05 per million logs per month
- Warm always queryable storage for up to 15 months
- Implement a log aggregation tool to reduce the volume of logs you send to Datadog via deduping, aggregation, sampling, quotas, and log-to-metrics all at the edge in your own infrastructure
Redacted/Genericized Sample Account Analysis
This is a sample of an account analysis that was performed for a paying customer and any identifying information has been removed.
Analysis based on point in time, <redacted>, and the preceding 30 days of logs indexed with Datadog totaling 628B events.
There are many approaches that can be taken, and these are without context to the <REDACTED> use cases, but if such a prescriptive suggestion is useful then Datadog will be happy to have a focused discussion around use cases to help them further refine their strategy. This is based on what we were able to learn from analyzing your Datadog account.
Current Index Configuration
- 47 indexes — majority by service
- Top 10 indexes account for 80% of logs
- Top 10 indexes account for 90% of total cost
- Many indexes for < 0.05% total volume and even several < 0.01%
- Datadog would not recommend continuing down this path for optimization purposes (see recommends in next section)
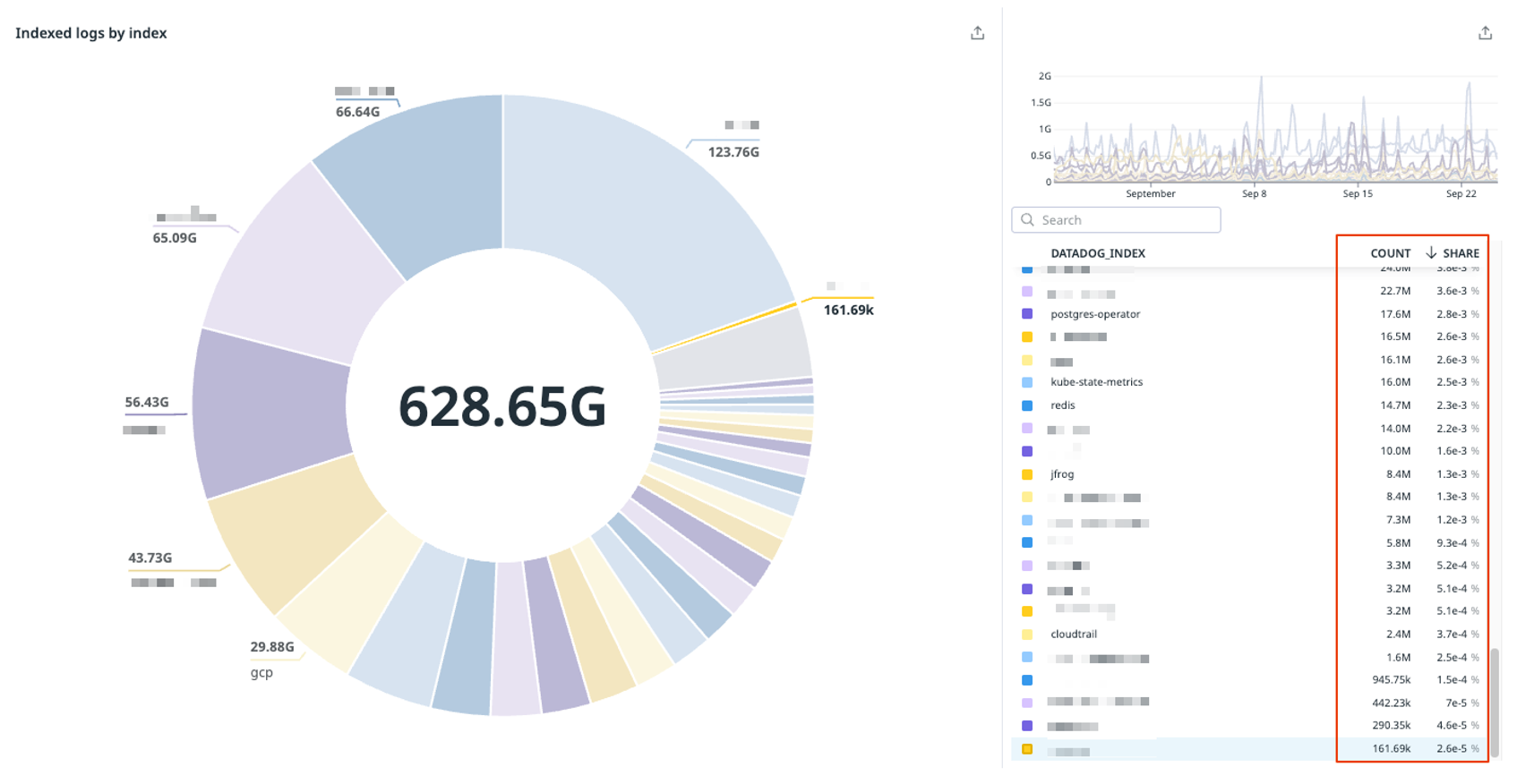
- Overall 7% exclusion ratio
- Opportunities abound for sampling, exclusion, and logs-to-metrics
- There is a unit based approach to the current indexing strategy, a mix of `team`, `infra`, and `platform` tags some in combination together and occasionally the use of `category` tags to further filter down.
- Lacking consistency in tag usage for filters (i.e. not always using
team)
- Lacking consistency in tag usage for filters (i.e. not always using
- 34 standard tier extended to flex tier for 30d
- 8 indexes straight to Flex Tier
- 5 indexes without Flex Tier
- There are 4 retention buckets: 3, 5, 7, and 15 days
- 1 catch-all index that excludes everything
- It would be better to forward this to an archive potentially should you ever need to recover logs that don’t match a filter above
Log Events/Volumes
- 628B events ingested
- 584B events indexed
- Exclusion ratio: 7.02%
- 1.46PB ingested bytes
- 439 service tags
- Top 10 values account for 88% of all indexed logs
- Values such as empty string (
””)(428M) or${service}(literal)(475M) - 2.4B (15%) logs missing service tag (N/A)
- 125 team tag values
- Top 10 values account for 93% of all indexed logs
- 30 infra tag values
- Top 5 values account for 80% of all indexed logs
- 11 env values
- Top 3 values account for 99% of all indexed logs
- 8 status values
- `info` accounts for 94.1% of all indexed logs
- 2.39M logs excluded to have timestamps > 18hr
- 2B logs dropped due to timestamps too far in the future (>2hr in the future)
- 166.2M logs missing `env` tag
- 4.4M logs with double tagged `env` (`dev` and `ops`)
Log Patterns (finding optimizations)
Looking at patterns we noted a number of situations that could be reduced. It will require someone to review.
For example: the top pattern consumed ~17B indexed events in the last 15 days, with no variation in the message, and very little metadata (no attributes, only tags)
~27B info logs, pattern: `Sent [200–500] in [2–15525]*` from `service:
` - Example: `Sent 200 in 56ms`
- Largely appear to be tracking response times
- Excellent case for a custom metric using logs-to-metrics
- Could also potentially be sent in as a metric to begin with
- Depends on cardinality, would require someone with knowledge of system(s) and use cases to make determination
~18.4B warn logs, no pattern, from `service:
` - Same message over and over: `Elixir.
.Services.ParseUserAgent.parse_app_version.nil` - Fairly low info density
- User agent, file_name, method_name, might have some variation, further analysis could be done using DD Log Analytics
- Same message over and over: `Elixir.
~2.3B: info `request * on app version v*`
- UUID + app version
- Not sure how useful this is
~2.1B info `INFO: Feature Flag: *: true`
- Could be submitted as metadata on other logs for the service
~970M warning `yyyy/MM/dd HH:mm:ss [warn] [35–9099]#[35–9099]: [78673–32773985] a client request body is buffered to a temporary file /tmp/nginx/client-body/ client: XXX.XXX.XXX.XXX, server: *, request: “POST /api/v1/push HTTP/1.1”, host: “<redacted>”`
- Heavy sampling here could save a lot
- Either need to bump client_body_buffer_size or if you expect to upload files that will not fit into the memory buffer, just suppress/ignore this warning
~760M info `CACHE_HIT`
- no pattern — could be a log-to-metric?
- or submitted as a metric in the first place?
- no pattern — could be a log-to-metric?
~261M Debug events
- Generally we don’t see customers needing debug events, but your use cases may call for it
- If not needed would suggest excluding
… And plenty of others for review.
Suggested Optimization & Indexing Strategy
Based on the above account deep dive, we suggest applying the 80/20 rule, and tackling the few buckets that make up the vast majority of indexed logs.
With that in mind, something like below would be a good model to start from that will scale:
Focus on those buckets which make up the majority of logs
- In this case the dimensions being used for index filters
- NOT on those that make up < 0.1%
- don’t chase the tail — low ROI
- That could possibly come later but not a place to start
Potentially re-imagine the index strategy in place
- As noted in the account analysis section above:
- There are many indexes for < 0.05% total volume and even several < 0.01%.
- Top 10 indexes account for 80% of logs
- Top 10 indexes account for 90% of total cost
- Target these top contributors, potentially splitting those buckets into smaller indexes
- To avoid administrative overhead burden, let those indexes which make up < 1% go to some catch-all-like buckets for easier management and to avoid optimizing “for the tail”
- As noted in the account analysis section above:
Improve sampling/exclusions, many low information/value logs (HTTP requests [e.g. 200 OK], service health checks, etc), some examples:
- See the “Log Patterns (finding optimizations)” section
- Generate log-to-metrics for any trends that need to be tracked but where the individual log is not important
Continue the trend towards moving audit, transactional, and low information density logs straight to Flex logs vs 7d standard then to Flex tier.
- Datadog noted 3 flex only indexes (meaning no standard indexing) on/around Jan ~31, but on Feb 06 there were now 8 straight to Flex indexes.
- Certain use cases might dictate some standard indexing, could leverage 3d in those cases to optimize cost
- Can still generate metrics from logs that go straight to the flex tier
- These metrics can be used for real time alerting
If cost optimization is a concern:
- Setup anomaly monitors against estimated usage metrics: https://docs.datadoghq.com/logs/guide/best-practices-for-log-management/#alert-on-unexpected-log-traffic-spikes
- Find other metrics and dimensions that you may care about on the estimated usage dashboard: https://app.datadoghq.com/dash/integration/logs_estimated_usage
- Threshold alerts on spikes: https://docs.datadoghq.com/logs/guide/best-practices-for-log-management/#alert-when-an-indexed-log-volume-passes-a-specified-threshold
- Set quotas per index and alert when nearing the quota or when it has been reached: https://docs.datadoghq.com/logs/guide/best-practices-for-log-management/#alert-on-indexes-reaching-their-daily-quota
- Any logs beyond the quota will still work with archives and log-to-metrics
Continue sending logs to an archive for rehydration for anything beyond index retention periods
- This also applies to any logs that have been excluded from indexing due to sampling, exclusion, or quotas reached
- If rehydration becomes tedious due to single large archive, suggest breaking up catch-all (*) archive into logical buckets for faster scan and re-ingest
Supplemental
Best Practices
Be sure to read through our Best Practices for Log Management guide and Logging Without Limits™ Guide for additional information, and a review of the majority of the recommendations made in this document.
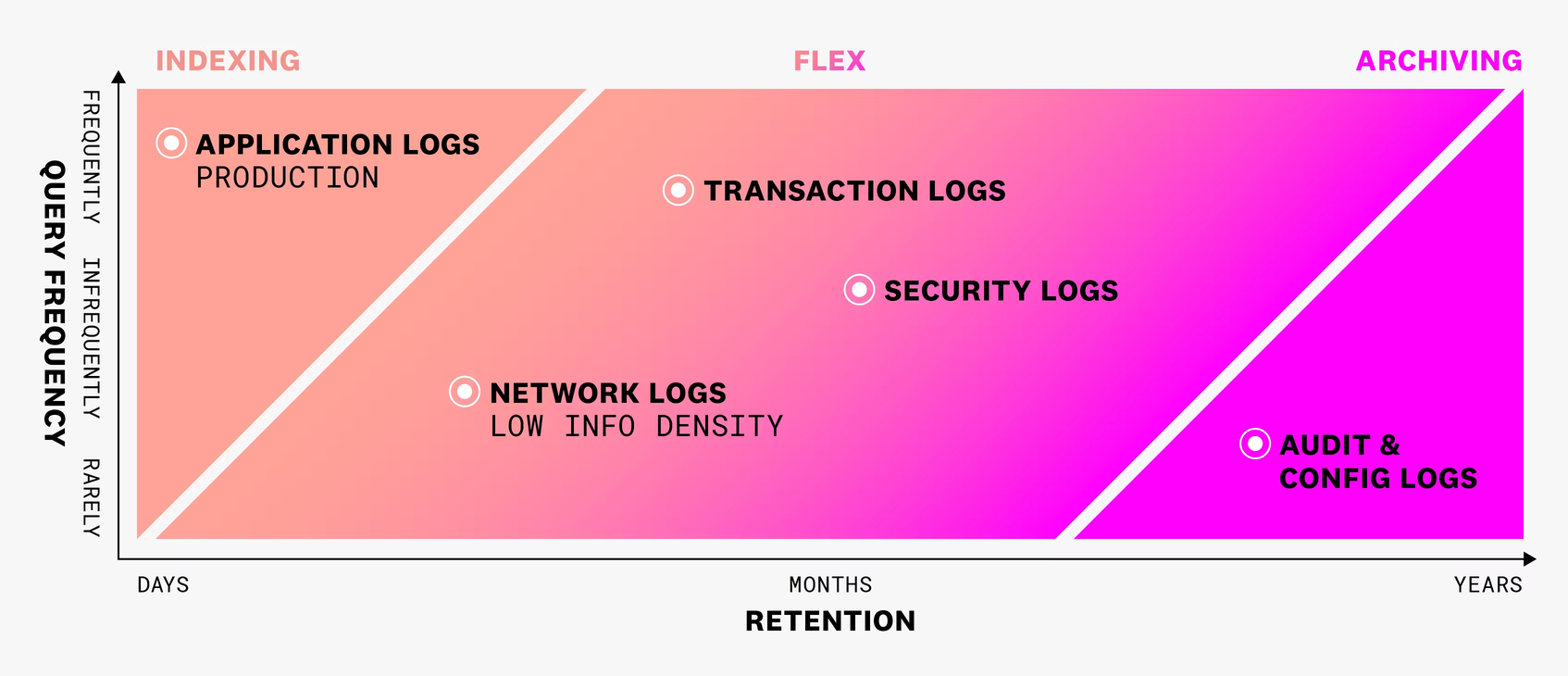
How should I be thinking about retention?
Read the Flex Logs blog to better understand how to think about various logs in the context of retention and query frequency.
How do I know what to exclude?
Once you have logs flowing into Datadog, this becomes a bit easier. Read our Logging Without Limits guide to see how to use the Datadog platform to find and define exclusion filters. But ultimately this comes down to intimate knowledge of your systems. If you aren’t the application/service/system owner, it is best to consult with those team(s) to help determine what is useful to keep.